ビットマップインデックス
このトピックでは、ビットマップインデックスの作成と管理方法、および使用例について説明します。
ビットマップインデックスは、ビットマップ(ビットの配列)を使用する特別なデータベースインデックスです。ビットは常に 0 と 1 のいずれかの値を持ちます。ビットマップ内の各ビットは、テーブル内の単一の行に対応しています。各ビットの値は、対応する行の値に依存します。
ビットマップインデックスは、特定の列のクエリパフォーマンスを向上させるのに役立ちます。クエリがソートキー列にヒットした場合、CelerData はプレフィックスイン��デックスを使用して効率的にクエリ結果を返します。ただし、データブロックのプレフィックスインデックスエントリは 36 バイトを超えることはできません。ソートキーとして使用されていない列のクエリパフォーマンスを向上させたい場合は、その列に対してビットマップインデックスを作成できます。
利点
ビットマップインデックスの利点は次のとおりです。
- 列が低基数の場合、応答時間を短縮できます。例えば、ENUM 型の列などです。列内の異なる値の数が比較的多い場合は、ブルームフィルターインデックスを使用してクエリ速度を向上させることをお勧めします。詳細は Bloom filter indexing を参照してください。
- 他のインデックス技術と比較して、ストレージスペースを節約できます。ビットマップインデックスは通常、テーブル内のインデックス付きデータのサイズのほんの一部しか占めません。
- 複数のビットマップインデックスを組み合わせて、複数の列に対してクエリを実行できます。詳細は Query multiple columns を参照してください。
使用上の注意
- 等号 (
=) または [NOT] IN 演算子を使用してフィルタリングできる列に対してビットマップインデックスを作成できます。 - 重複キーテーブルまたはユニークキーテーブルを使用するテーブルのすべての列に対してビットマップインデックスを作成できます。集計テーブルまたは主キーテーブルを使用するテーブルの場合、キー列に対してのみビットマップインデックスを作成できます。
- FLOAT、DOUBLE、BOOLEAN、および DECIMAL 型の列はビットマップインデックスの作成をサポートしていません。
- クエリがビットマップインデックスを使用しているかどうかは、クエリのプロファイルの
BitmapIndexFilterRowsフィールドを確認することで確認できます。
ビットマップインデックスの作成
列に対してビットマップインデックスを作成する方法は 2 つあります。
-
テーブルを作成する際に列に対してビットマップインデックスを作成します。例:
CREATE TABLE d0.table_hash
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5",
v1 CHAR(10) REPLACE,
v2 INT SUM,
INDEX index_name (column_name [, ...]) USING BITMAP COMMENT ''
)
ENGINE = olap
AGGREGATE KEY(k1, k2)
DISTRIBUTED BY HASH(k1) BUCKETS 10
PROPERTIES ("storage_type" = "column");次の表は、ビットマップインデックスに関連するパラメータを説明しています。
Parameter Required Description index_name Yes ビットマップインデックスの名前。 column_name Yes ビットマップインデックスが作成される列の名前。これらの列名を指定することで、複数の列に対してインデックスを作成できます。 COMMENT No ビット��マップインデックスのコメント。 CREATE TABLE ステートメントの他のパラメータの説明については、 CREATE TABLE を参照してください。
-
CREATE INDEX ステートメントを使用してテーブルの列に対してビットマップインデックスを作成します。パラメータの説明と例については、 CREATE INDEX を参照してください。
CREATE INDEX index_name ON table_name (column_name) [USING BITMAP] [COMMENT ''];
ビットマップインデックスの表示
SHOW INDEX ステートメントを使用して、テーブル内に作成されたすべてのビットマップインデックスを表示できます。パラメータの説明と例については、 SHOW INDEX を参照してください。
SHOW { INDEX[ES] | KEY[S] } FROM [db_name.]table_name [FROM db_name];
Note
インデックスの作成は非同期プロセスです。したがって、作成プロセスが完了したインデックスのみを表示できます。
ビットマップインデックスの削除
DROP INDEX ステートメントを使用して、テーブルからビットマップインデックスを削除できます。パラメータの説明と例については、 DROP INDEX を参照してください。
DROP INDEX index_name ON [db_name.]table_name;
使用例
たとえば、次の employee テーブルは、会社の従業員情報の一部を示しています。
| ID | Gender | Position | Income_level |
|---|---|---|---|
| 01 | female | Developer | level_1 |
| 02 | female | Analyst | level_2 |
| 03 | female | Salesman | level_1 |
| 04 | male | Accountant | level_3 |
単一列のクエリ
たとえば、Gender 列のクエリパフォーマンスを向上させたい場合、次のステートメントを使用して列に対してビットマップインデックスを作成できます。
CREATE INDEX index1 ON employee (Gender) USING BITMAP COMMENT 'index1';
上記のステートメントを実行すると、次の図のようにビットマップインデックスが生成されます。
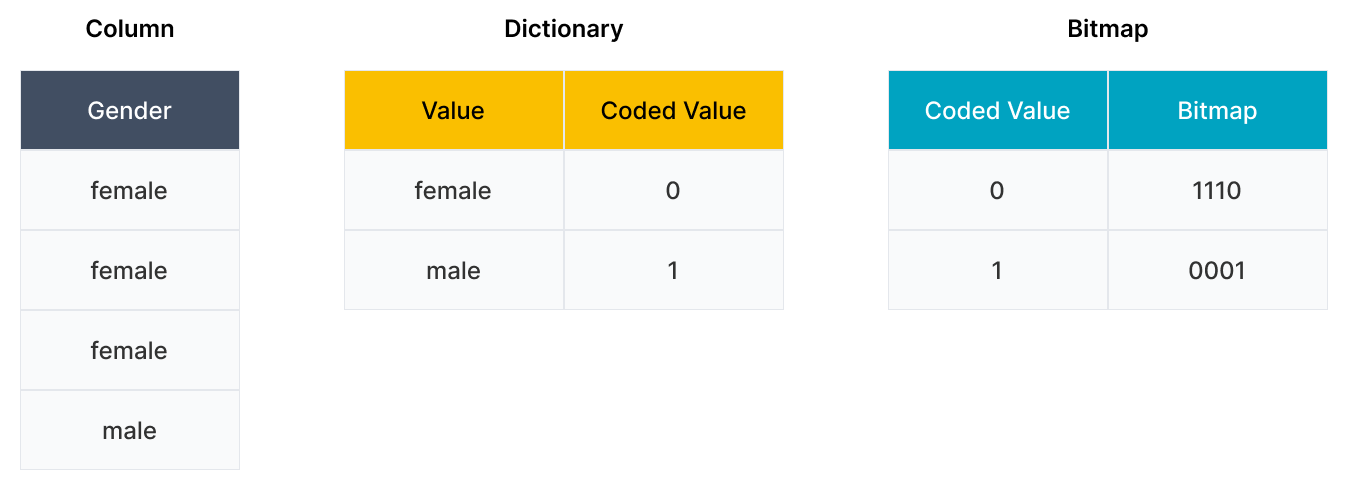
- 辞書を構築する: CelerData は
Gender列の辞書を構築し、femaleとmaleを INT 型のコード化された値0と1にマッピングします。 - ビットマップを生成する: CelerData はコード化された値に基づいて
femaleとmaleのビットマップを生成します。femaleのビットマップは1110で、femaleは最初の 3 行に表示されます。maleのビットマップは0001で、maleは 4 行目にのみ表示されます。
会社の男性従業員を見つけたい場合、次のようにクエリを送信できます。
SELECT xxx FROM employee WHERE Gender = male;
クエリが送信されると、CelerData は辞書を検索して male のコード化された値 1 を取得し、次に male のビットマップ 0001 を取得します。これは、クエリ条件に一致するのは 4 行目のみであることを意味します。その後、CelerData は最初の 3 行をスキップし、4 行目のみを読み取ります。
複数列のクエリ
たとえば、Gender と Income_level 列のクエリパフォーマンスを向上させたい場合、次のステートメントを使用してこれら 2 ��つの列に対してビットマップインデックスを作成できます。
-
GenderCREATE INDEX index1 ON employee (Gender) USING BITMAP COMMENT 'index1'; -
Income_levelCREATE INDEX index2 ON employee (Income_level) USING BITMAP COMMENT 'index2';
上記の 2 つのステートメントを実行すると、次の図のようにビットマップインデックスが生成されます。
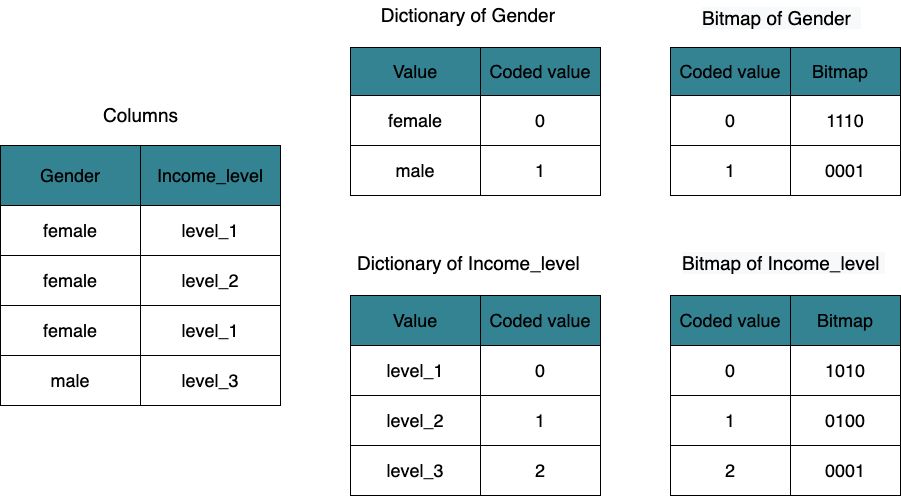
CelerData はそれぞれ Gender と Income_level 列の辞書を構築し、これら 2 つの列の異なる値に対してビットマップを生成します。
Gender:femaleのビットマップは1110、maleのビットマップは0001です。Producer:level_1のビットマップは1010、level_2のビットマップは0100、level_3のビットマップは0001です。
level_1 の給与を持つ女性従業員を見つけたい場合、次のようにクエリを送信できます。
SELECT xxx FROM employee
WHERE Gender = female AND Income_level = Level_1;
クエリが送信されると、CelerData は同時に Gender と Income_level の辞書を検索して、次の情報を取得します。
femaleのコード化された値は0で、femaleのビットマップは1110です。level_1のコード化された値は0で、level_1のビットマップは1010です。
CelerData は AND 演算子に基づいてビット単位の論理演算 1110 & 1010 を実行し、結果 1010 を取得します。この結果に基づいて、CelerData は最初の行と 3 行目のみを読み取ります。