Amazon Kinesis からデータをロードする
このトピックでは、Amazon Kinesis から CelerData にデータをロードする方法について説明します。
仕組み
全体的なソリューションは次のとおりです。
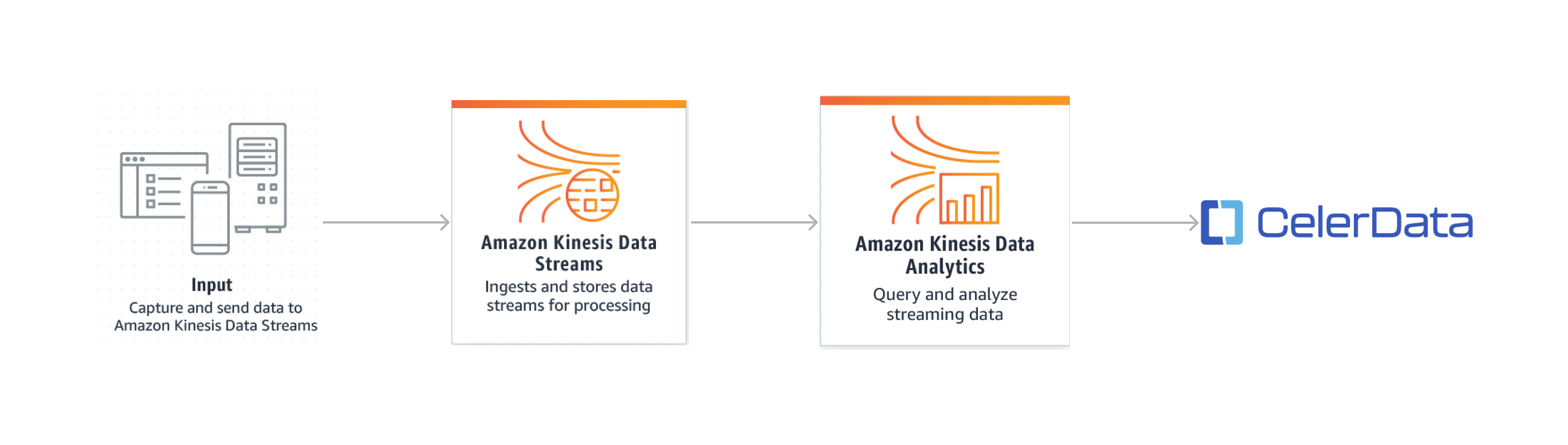
- ビジネスアプリケーションがストリーミングデータを Kinesis データストリームに書き込みます。
- Kinesis データストリームから入力データを読み取るために、Kinesis Data Analytics アプリケーションを作成します。
- Kinesis Data Analytics アプリケーションは、flink-connector-starrocks SDK を使用して CelerData クラスターにデータを書き込みます。
注意事項
- 最初に get started 演習を行い、Kinesis データストリームをソースおよびシンクとして使用する Kinesis Data Analytics アプリケーションを作成することを強くお勧めします。これにより、Kinesis に迅速に慣れ、CelerData クラスターにデータを書き込む前に発生する可能性のある問題を解決できます。
- スムーズなロード操作を確保するために、AWS Management Console を使用して Kinesis データストリームと Kinesis Data Analytics アプリケーションを作成し、get started 演習で指定された名前を使用することをお勧めします。
- Kinesis Data Analytics アプリケーションを構成する際には、次の構成に注意してください:
- IAM ポリシーを編集する際には、Kinesis データストリームにアクセスするための権限を追加することを確認してください。
- データ分析アプリケーションのネットワーキングを構成する際には、Kinesis Data Analytics アプリケーションがインターネットにアクセスできることを、Configure the application networking の指示に厳密に従って確認してください。
- CelerData クラスターを作成する際には、SSL 接続を有効にする必要があります。
- アプリケーションを正常に実行し、データストリームにデータをロードし始めたら、Data Viewer を使用してデータストリーム内のデータを表示し、ターゲットの CelerData テーブルにデータがロードされているかどうかを確認できます。
始める前に
Kinesis Data Analytics アプリケーションがインターネット経由で CelerData クラスターに接続できることを確認してください。
CelerData クラスターのネットワーキングを構成する
-
特に CelerData クラスターがプライベートサブネットにある場合、インターネットから CelerData クラスターに接続できることを確認してください。CelerData クラスターがパブリックサブネットにある場合、デフォルトでインターネット経由で接続できます。このトピックでは、パブリックサブネットにある CelerData クラスターを例として使用します。
-
CelerData クラスターリソースに関連付けられたセキュリティグループが、Kinesis Analytics アプリケーションからのトラフィックを許可していることを確認してください。
-
CelerData Cloud BYOC コンソールにサインインし、CelerData クラスターに関連付けられたセキュリティグループ IDを見つけます:

-
Amazon VPC コンソールにサインインします。
-
左側のナビゲーションペインで、Security Groups を選択します。CelerData クラスターリソースに関連付けられたセキュリティグループを見つけます。
-
Inbound Rules タブで、Edit inbound rules を選択します。
-
赤枠で強調表示された次のルールを追加します:
ポート
443と9030を追�加する必要があります。
Note
CelerData クラスターを作成する際には、SSL 接続を有効にする必要があります。
-
Kinesis Data Analytics アプリケーションのネットワーキングを構成する
Kinesis Data Analytics アプリケーションを構成する際に、Kinesis Data Analytics アプリケーションがインターネットにアクセスできることを確認してください。
- アプリケーションの VPC をカスタマイズする場合、アプリケーションのネットワーキングは次の要件を満たす必要があります:
- Kinesis Data Analytics アプリケーションはプライベートサブネットで実行される必要があります。
- VPC にはパブリックサブネットに NAT ゲートウェイまたはインスタンスが含まれている必要があります。
- プライベートサブネットから NAT ゲートウェイまたはインスタンスをホストするパブリックサブネットへのアウトバウンドトラフィックの�ルートが構成されている必要があります。 詳細については、Internet and Service Access for a VPC-connected Kinesis Data Analytics application を参照してください。
- または、アプリケーションのネットワーキングを No VPC として構成することもできます。
基本操作
ストリーミングデータを Kinesis Data Stream に書き込む
Kinesis Data Stream を使用して、大量のデータレコードをリアルタイムで保存できます。
- Kinesis データストリームを作成する。Kinesis を初めて使用する場合は、get started 演習と同じ名前
ExampleInputStreamを使用することをお勧めします。 - Kinesis Data Analytics アプリケーションを正常に実行した後、Kinesis データストリームにデータを書き込む。
CelerData クラスターにデータベースとテーブルを作成する
Kinesis データストリーム内のデータレコードに従って、CelerData クラスターにデータベースとテーブルを作成します。
CREATE DATABASE IF NOT EXISTS example_db;
USE example_db;
CREATE TABLE stock (
`EVENT_TIME` datetime NOT NULL,
`TICKER` varchar(65533) NOT NULL,
`PRICE` float NULL
) ENGINE=OLAP
DUPLICATE KEY(`EVENT_TIME`)
DISTRIBUTED BY HASH(`EVENT_TIME`) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
Kinesis Data Analytics アプリケーションを使用して Kinesis Data Stream からデータを読み取り、CelerData にデータを書き込む
Kinesis Data Analytics アプリケーションを使用して、データストリームから継続的にデータを読み取り、ストリーミングデータを処理および分析し、CelerData クラスターに書き込むことができます。
デモコードを編集して Kinesis Data Analytics アプリケーションを構築する
Kinesis Data Analytics アプリケーションは、Kinesis Data Stream からデータを読み取り、flink-connector-starrocks SDK を使用してデータを複数の並列 Stream Load ジョブにカプセル化し、CelerData クラスターにデータをロードします。
アプリケーションのデモコードは、主にソースデータストリームとターゲット CelerData クラスターの Flink ジョブプロパティを構成します。元の AWS コードと比較して、デモコードは pom.xml ファイルで flink-connector-starrocks 依存関係を使用し、シンク関数でターゲット CelerData クラスターのジョブプロパティを構成します。
デモコードを編集して Kinesis Data Analytics アプリケーションを構築する手順は次のとおりです:
-
Kinesis Data Analytics アプリケーションを開発するための前提条件を満たしていることを確認してください。
-
リモートリポジトリをクローンします。
git clone git@github.com:StarRocks/demo.git -
BasicStreamingJob.java ファイルを含むディレクトリに移動します。このトピックでは Flink バージョン 1.15 を例として使用するため、GettingStarted ディレクトリに移動する必要があります。
cd ./demo/AwsDemo/amazon-kinesis-data-analytics-java-examples/GettingStarted/src/main/java/com/amazonaws/services/kinesisanalytics -
デモコードを編集し、BasicStreamingJob.java ファイルでソースとシンクのプロパティを構成します。
Note
以下は BasicStreamingJob.java ファイルの一部のコードのみを示しています。全体のコー��ドとコードの差分については、この pull request を参照してください。
public class BasicStreamingJob {
private static final Log log = LogFactory.getLog(BasicStreamingJob.class);
private static final String region = "us-west-2"; // The region of the source data stream
private static final String inputStreamName = "ExampleInputStream"; // The name of the source data stream
private static final String outputStreamName = "ExampleOutputStream";
private static DataStream<String> createSourceFromStaticConfig(StreamExecutionEnvironment env) {
Properties inputProperties = new Properties();
inputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
inputProperties.setProperty(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST");
return env.addSource(new FlinkKinesisConsumer<>(inputStreamName, new SimpleStringSchema(), inputProperties));
}
......
public static void main(String[] args) throws Exception {
// Set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/* If you want to use runtime configuration properties, uncomment the lines below
* DataStream<String> input = createSourceFromapplicationProperties(env);
*/
log.info("Create an input");
DataStream<String> input = createSourceFromStaticConfig(env);
/* If you want to use runtime configuration properties, uncomment the lines below
* input.sinkTo(createSinkFromapplicationProperties())
*/
log.info("Start to create an sink");
// input.sinkTo(createSinkFromStaticConfig());
input.addSink(createCelerDataSinkFromapplicationProperties());
log.info("Success to add a CelerData sink");
env.execute("Flink Streaming Java API Skeleton");
}
private static SinkFunction<String> createCelerDataSinkFromapplicationProperties() throws IOException {
Map<String, Properties> applicationProperties = KinesisAnalyticsRuntime.getapplicationProperties();
Properties outputProperties = applicationProperties.get("ProducerConfigProperties");
if (outputProperties == null) {
outputProperties = new Properties();
log.info("ProducerConfigProperties is not set. It will use default config");
}
else {
log.info("ProducerConfigProperties: " + outputProperties.toString());
}
StarRocksSinkOptions.Builder builder = StarRocksSinkOptions.builder()
.withProperty("jdbc-url", outputProperties.getProperty("jdbc-url", "jdbc:mysql://xxxxxxxx.cloud-app.celerdata.com:9030"))
.withProperty("load-url", outputProperties.getProperty("load-url", "https://xxxxxxxx.cloud-app.celerdata.com"))
.withProperty("username", outputProperties.getProperty("username", "admin"))
.withProperty("password", outputProperties.getProperty("password", "123456"))
.withProperty("database-name", outputProperties.getProperty("database-name", "example_db"))
.withProperty("table-name", outputProperties.getProperty("table-name", "stock"))
/**
* The connector can encapsulate the data into two formats: CSV and JSON
* For CSV data:
* .withProperty("sink.properties.format", "csv")
* For JSON data:
*/
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.jsonpaths", "[\"event_time\", \"ticker\", \"price\"]")
// .withProperty("sink.properties.columns", "event_time, ticker, price")
.withProperty("sink.properties.strip_outer_array", "true");
for (Map.Entry<Object, Object> property : outputProperties.entrySet()) {
if (StringUtils.startsWith(property.getKey().toString(), "sink.")) {
builder.withProperty(property.getKey().toString(), property.getValue().toString());
}
}
return StarRocksSink.sink(builder.build());
}
ソース およびシンクプロパティ
-
ソースプロパティ
プロパティ 必須 説明 region Yes 入力 Kinesis Data Stream のリージョン。 inputStreamName Yes 入力 Kinesis Data Stream の名前。 -
シンクプロパティ
プロパティ 必須 説明 jdbc-url Yes MySQL サーバーを通じて CelerData クラスターにアクセスするために使用される URL。この形式は jdbc:mysql://xxxxxxxxx.cloud-app.celerdata.com:9030です。load-url Yes HTTP サーバーを通じて CelerData クラスターにアクセスするために使用される URL。この URL は、CelerData クラスターに割り当てられたドメイン名を持つ HTTPS URL です。例: https://xxxxxxxxx.cloud-app.celerdata.com。database-name Yes CelerData データベースの名前。 table-name Yes CelerData テーブルの名前。 username Yes ターゲットデータベースとテーブルに書き込み権限を持つアカウントのユーザー名。 password Yes 上記のアカウントのユーザー名のパスワード。 sink.properties.* No Stream Load プロパティ。詳細については、data_desc および opt_properties を参照してください。 sink.properties.format No データ形式。有効な値: CSVおよびJSON。デフォルト値:CSV。sink.properties.jsonpaths No JSON データからロードしたいフィールドの名前。このパラメータの値は JSON 形式です。 sink.properties.strip_outer_array No flink-connector-starrocks がデータを JSON 形式にカプセル化し、その後 CelerData クラスターにデータをロードする場合、このパラメータを trueに設定する必要があります。flink-connector-starrocks はメッセージをグループ化して Stream Load ジョブを実行します。有効な値:trueおよびfalse。デフォルト値:false。後でプロパティを更新したり、さらにプロパティを構成したりする場合は、Configuration タブの Runtime properties セクションで構成を変更できます。
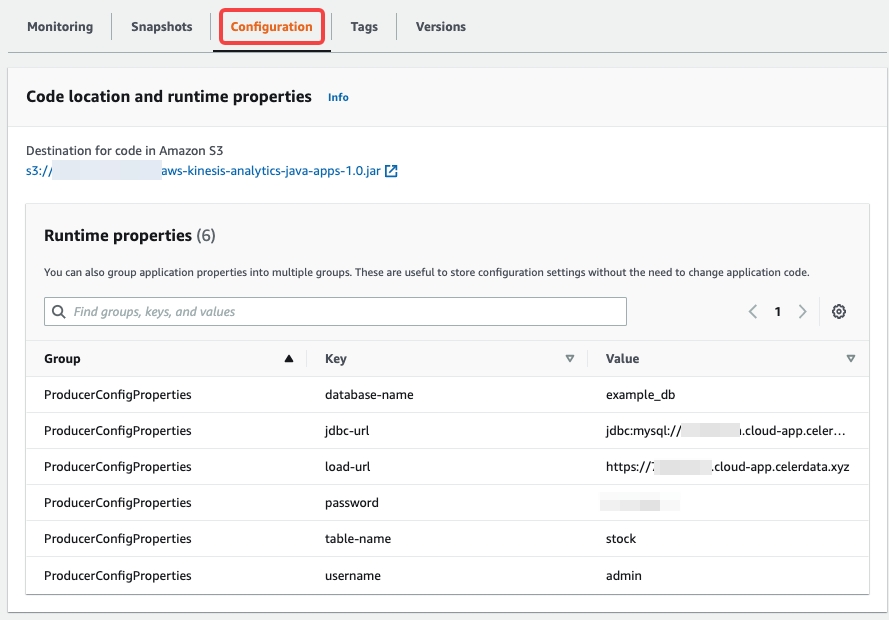
-
pom.xml ファイルに flink-connector-starrocks 依存関係を追加します。
<dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<version>1.2.6_flink-1.15</version>
</dependency>flink-connector-starrocks バージョンは
${flink-connector-starrocks.version}_flink-${fink.version}_${scala.version}の形式です。また、Flink バージョンが 1.15.x の場合、Scala バージョンを指定する必要はありません。サポートされているすべてのバージョンについては、flink-connector-starrocks の github リポジトリ を参照してください。 -
デモコードをコンパイルして JAR ファイルにパッケージ化します。詳細については、Compile the application Code を参照してください。
mvn package -Dflink.version=1.15.2
- aws-kinesis-analytics-java-apps-1.0.jar ファイルを Amazon S3 バケットにアップロードします。詳細については、Upload the Apache Flink Streaming Java Code を参照してください。
Kinesis Data Analytics アプリケーションの作成と構成
Create and Run the Kinesis Data Analytics application に従って、Kinesis Data Analytics アプリケーションを作成および構成します。次の構成に注意してください。
IAM ポリシーの構成
Kinesis Data Analytics アプリケーションがデータストリームを読み取るために必要な権限を含む IAM ロールを構成します。
-
Kinesis Data Analytics アプリケーションを作成する際に、デフォルトで必要なポリシーを持つ IAM ロールを作成します。
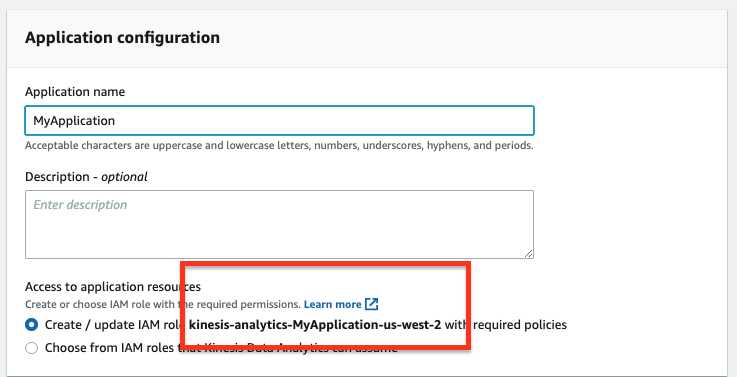
-
アプリケーションを作成した後、IAM ポリシーを編集し、アプリケーションに添付されたポリシーが次のように編集されていることを確認します。サンプルアカウント ID
012345678901を自分のアカウント ID に置き換える必要があります。{
"Sid": "ReadInputStream",
"Effect": "Allow",
"Action": "kinesis:*",
"Resource": "arn:aws:kinesis:us-west-2:012345678901:stream/ExampleInputStream"
}
アプリケーションコードの場所を構成する
アプリケーションを構成する際に、アプリケーションコードの場所を指定する必要があります:
-
Amazon S3 バケットの場合、アプリケーション JAR ファイルを含む S3 バケットを指定します。
-
Path to Amazon S3 objectの場合、アプリケーション JAR ファイルの名前を指定します。デフォルトの名前は aws-kinesis-analytics-java-apps-1.0.jar です。
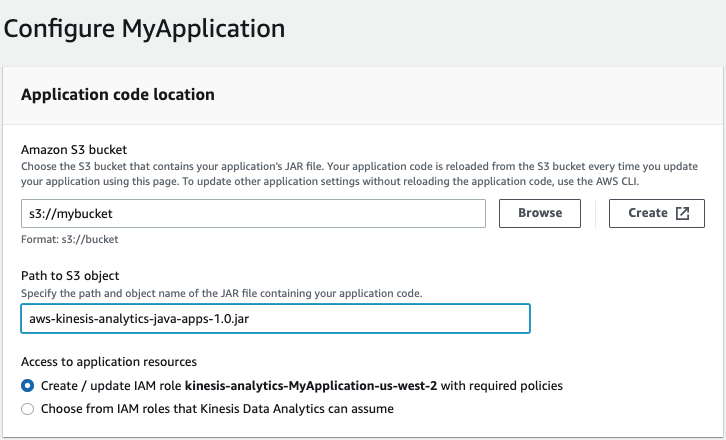
アプリケーションネットワーキングの構成
-
アプリケーションを構成する際に、アプリケーションがインターネットにアクセスできるようにネットワーキングを構成する必要があります:
-
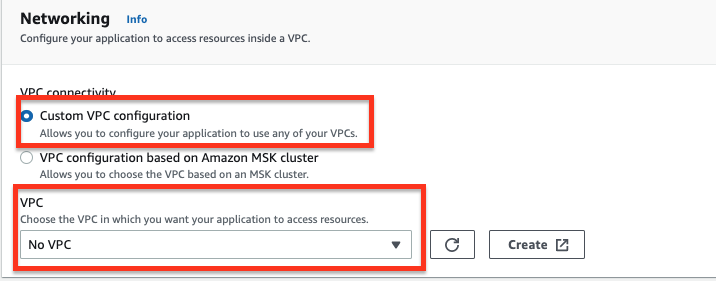
オプション 1: VPC connectivity に対して Custom VPC configuration を選択し、VPC ドロップダウンリストから No VPC を選択します。
-
オプション 2: Internet and Service Access for a VPC-Connected Kinesis Data Analytics application に提供されている指示に厳密に従ってネットワーキングを指定します。要するに、アプリケーションネットワーキングは次の要件を満たす必要があります:
- Kinesis Data Analytics アプリケーションはプライベートサブネットで実行される必要があります。
- VPC にはパブリックサブネットに NAT ゲートウェイまたはインスタンスが含まれている必要があります。
- プライベートサブネットから NAT ゲートウェイまたはインスタンスをホストするパブリックサブネットへのアウトバウンドトラフィックのルートが構成されている必要があります。
-
Kinesis Data Analytics アプリケーションを実行する
-
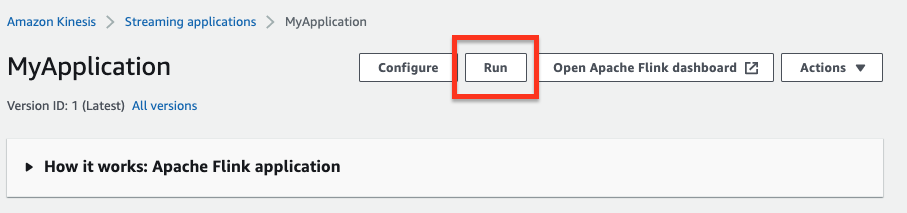
MyApplication ページで、Run を選択します。表示されるメッセージで、Confirm をクリックします。
-
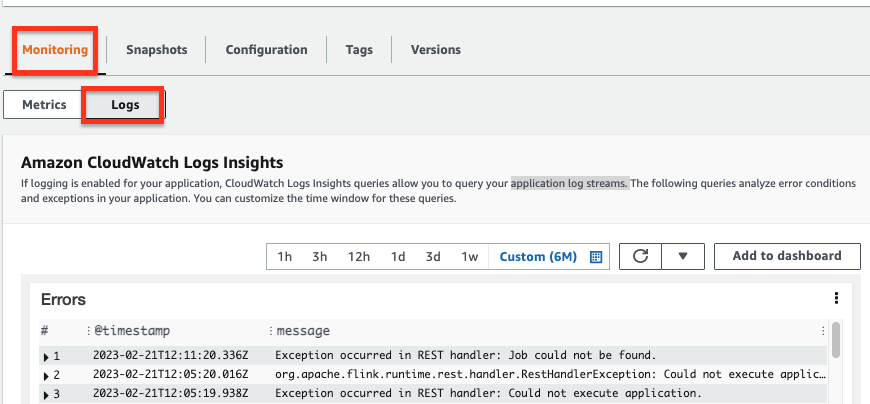
Monitoring タブの Logs セクションで、アプリケーションの実行情報を表示します。例えば、アプリケーションのErrors、Exceptions、Job status exceptions などを分析してエラーや例外を確認します。
Configuration タブの Logging and monitoring セクションで、アプリケーションの
INFOまたはWARNログを表示することもできます。ログストリーム kinesis-analytics-log-stream を開いて、BasicStreamingJobやstarrocksなどのイベントフィルターを使用して詳細なログを検索します。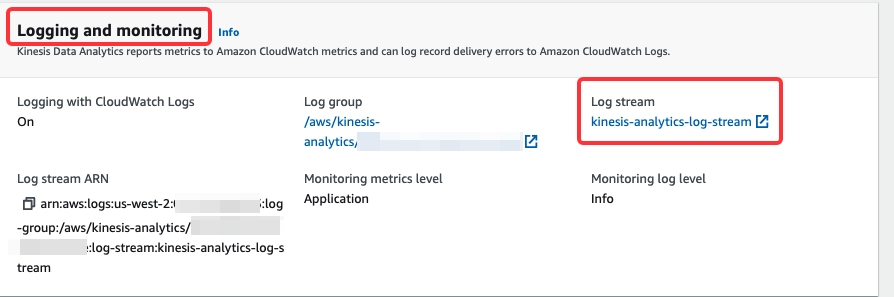
FAQ
- 問題の説明: Monitoring タブの Logs セクションの Exceptions 部分で、フィールド throwableInformation に
org.apache.flink.kinesis.shaded.com.amazonaws.SdkClientException: Unable to execute HTTP request : Connect to kinesis.us-west-2.amazonaws.com:443 [kinesis.us-west-2.amazonaws.com/34.223.45.1] failed: connect timed outと表示された場合、どうすればよいですか。
考えられる原因: Kinesis Analytics アプリケーションがプライベートサブネットではなく、パブリックサブネットに起動されています。
解決策:- アプリケーションの VPC をカスタマイズする場合、アプリケーションのネットワーキングが次の要件を満たしていることを確認してください:
- Kinesis Data Analytics アプリケーションはプライベートサブネットで実行される必要があります。
- VPC にはパブリックサブネットに NAT ゲートウェイまたはインスタンスが含まれている必要があります。
- プライベートサブネットから NAT ゲートウェイまたはインスタンスをホストするパブリックサブネットへのアウトバウンドトラフィックのルートが構成されている必要があります。 詳細については、Internet and Service Access for a VPC-connected Kinesis Data Analytics application を参照してください。
- または、アプリケーションのネットワーキングを No VPC として構成することもできます。
- アプリケーションの VPC をカスタマイズする場合、アプリケーションのネットワーキングが次の要件を満たしていることを確認してください:
- 問題の説明: Monitoring タブの Logs セクションの Error 部分で、フィールド message に
Error occurred when trying to start the jobと表示され、フィールド throwableInformation にFailed to get StarRocks versionと表示された場合、どうすればよいですか。
考えられる原因: CelerData クラスターのjdbc-urlが正しくありません。
解決策:mysql -u <celerdata_domain_name> -P 9030 -uadminを使用して、CelerData クラスターへの接続をテストします。 - 問題の説明: Monitoring タブの Logs セクションの Exceptions 部分で、フィールド message に
"message": "Failed to connect to address:``xxxxxxxxx.cloud-app.celerdata.com``”と表示された場合、どうすればよいですか。
考えられる原因: アプリケーションが HTTPS プロトコルを介して CelerData クラスターのドメインにアクセスできません。
解決策:
次の CelerData 構成を確認してください:- CelerData クラスターが SSL 接続を有効にしています。
- celerdata クラスターに関連付けられたセキュリティグループが、ポート
443を開くためのインバウンドルールを追加しています。