Confluent Cloud から Routine Load を使用してデータをロードする
このトピックでは、Confluent から CelerData にメッセージ(イベント)をストリームするための Routine Load ジョブの作成方法を紹介し、Routine Load に関する基本的な概念を説明します。
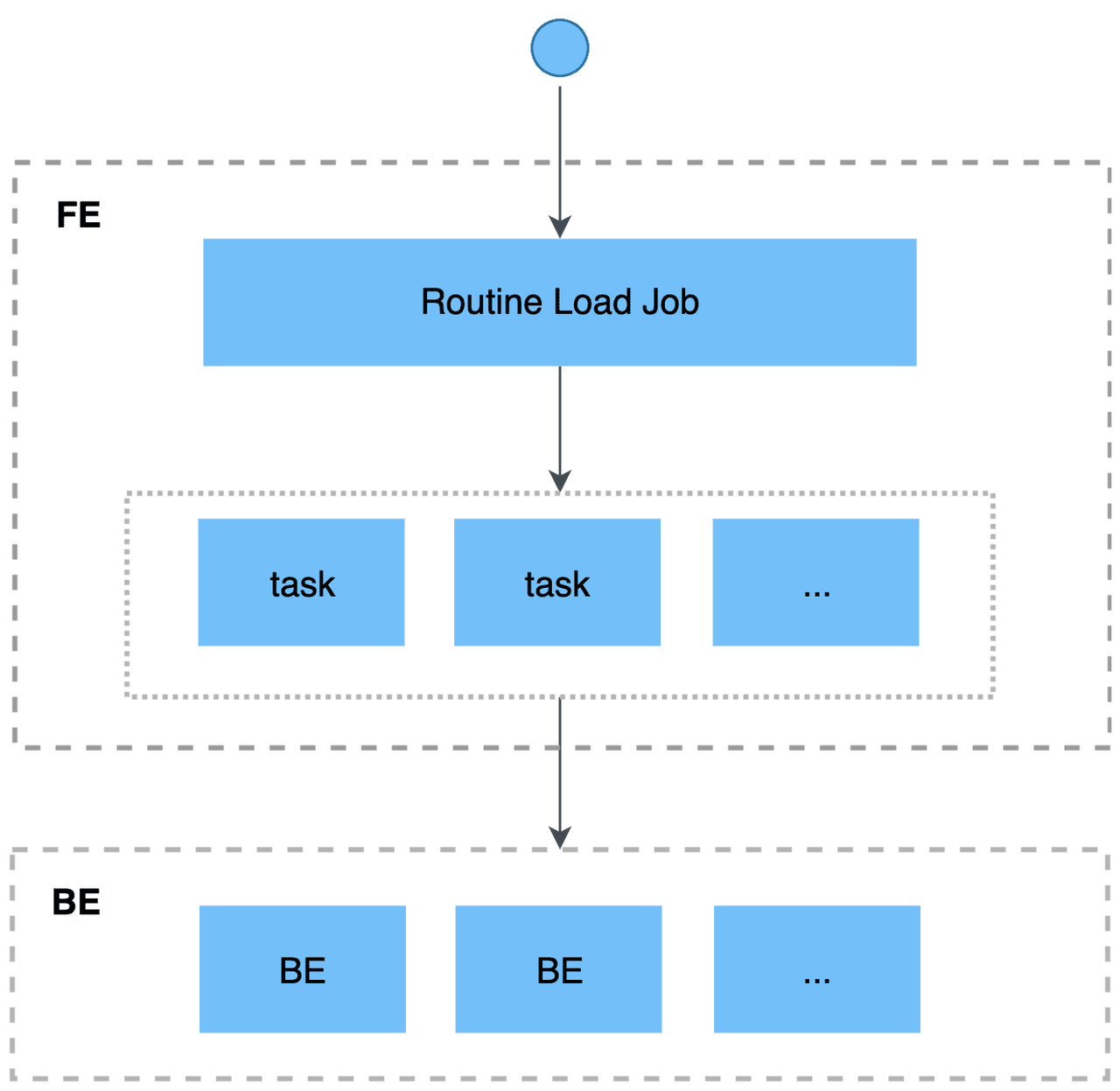
ストリームのメッセージを CelerData に継続的にロードするには、Confluent トピックにメッセージストリームを保存し、Routine Load ジョブを作成してメッセージを消費します。Routine Load ジョブは CelerData に永続化され、トピック内のすべてまたは一部のパーティションのメッセージを消費する一連のロードタスクを生成し、メッセージを CelerData にロードします。
Routine Load ジョブは、CelerData にロードされたデータが失われたり重複したりしないように、正確に一度だけの配信セマンティクスをサポートします。
サポートされているデータファイル形式
Routine Load は現在、Confluent クラスターからの CSV および JSON 形式のデータの消費をサポートしています。
注意
CSV 形式のデータについては、CelerData は 50 バイト以内の UTF-8 エンコードされた文字列を列セパレータとしてサポートしています。一般的に使用される列セパレータには、カンマ(,)、タブ、パイプ(|)があります。
動作の仕組み
始める前に
CelerData が Confluent Cloud クラスターにアクセスするためのネットワークの設定
-
VPC 内の CelerData のサブネットがインターネットに接続できることを確認してください。
- CelerData がプライベートサブネットにある場合、プライベートサブネット用に NAT ゲートウェイが設定されていることを確認し、CelerData がインターネットに接続できるようにします。
- CelerData がパブリックサブネットにある場合、CelerData はデフォルトでインターネットに接続できます。
-
セキュリティ目的で、VPC のセキュリティグループに以下のアウトバウンドルールを追加し、VPC 内の CelerData が Confluent Cloud にアクセスできるようにします。

-
Port range を
9092に設定します。注意
ポートが Confluent Cloud 上の Bootstrap server のポートであることを確認してください。
-
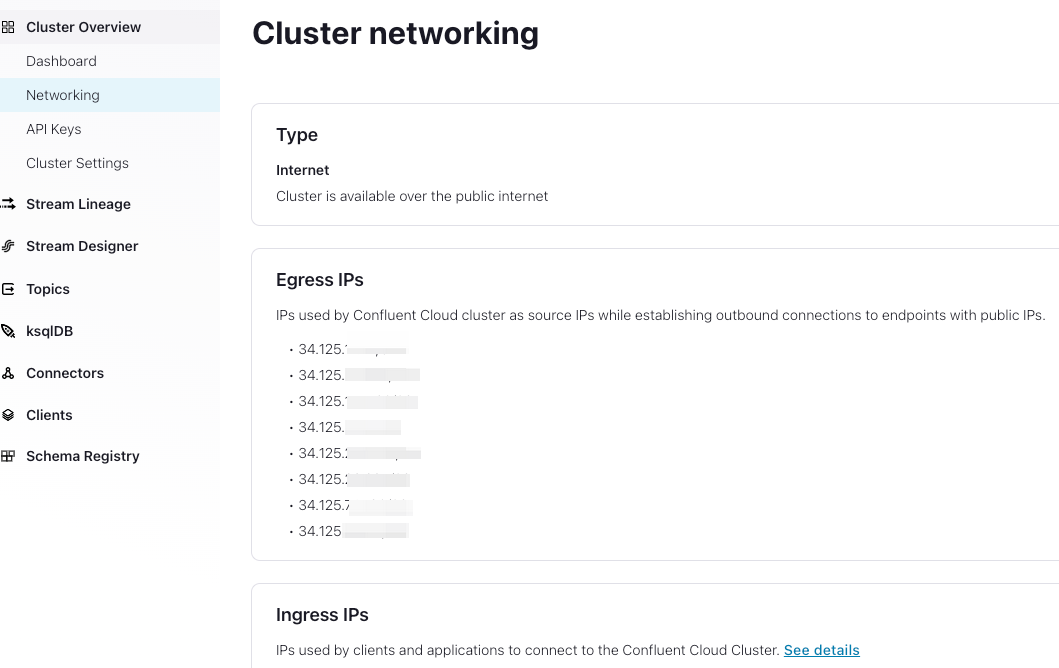
Destination を設定します。Confluent Cloud クラスターの Egress IP は、Confluent Cloud の
Cluster Overview > Networking > Egress IPsから Get started with Static Egress IP Addresses に従って確認できます。Confluent Cloud クラスターのすべての Egress IP を設定する必要があります。
-
-
(オプション)Confluent がファイアウォールメカニズムを有効にしている場合、CelerData クラスター(FE および BE)の以下の IP アドレスを Confluent クラスターのアクセス制御リストに追加します。
-
CelerData が AWS の VPC のプライベートサブネットにある場合 CelerData クラスター(FEs および BEs)の NAT ゲートウェイの Elastic IP アドレスを Confluent Cloud クラスターの ACL に追加します。Elastic IP アドレスは
VPC > NAT Gatewaysから確認できます。プライベートサブネット用の NAT ゲートウェイを選択する必要があります。その後、以下のように Elastic IP アドレスを確認できます。
-
CelerData が AWS の VPC のパブリックサブネットにある場合 CelerData クラスター(FEs および BEs)の Public IP アドレスを Confluent Cloud クラスターの ACL 許可リストに追加します。Public IP は AWS の
EC2 > Instancesから確認できます。
-
基本操作
Routine Load ジョブを作成する
以下の2つの例は、Confluent Cloud クラス�ターで CSV 形式および JSON 形式のデータを消費し、Routine Load ジョブを作成して CelerData にデータをロードする方法を示しています。詳細については、CREATE ROUTINE LOAD を参照してください。
CSV 形式のデータをロードする
このセクションでは、Confluent Cloud クラスターで CSV 形式のデータを消費し、Routine Load ジョブを作成して CelerData にデータをロードする方法を説明します。
データセットを準備する
Confluent Cloud クラスターのトピック ordertest1 に CSV 形式のデータセットがあるとします。データセット内の各メッセージには、注文 ID、支払い日、顧客名、国籍、性別、価格を表す6つのフィールドが含まれています。
2020050802,2020-05-08,Johann Georg Faust,Deutschland,male,895
2020050802,2020-05-08,Julien Sorel,France,male,893
2020050803,2020-05-08,Dorian Grey,UK,male,1262
2020050901,2020-05-09,Anna Karenina",Russia,female,175
2020051001,2020-05-10,Tess Durbeyfield,US,female,986
2020051101,2020-05-11,Edogawa Conan,japan,male,8924
テーブルを作成する
CSV 形式のデータのフィールドに基づいて、データベース example_db にテーブル example_tbl1 を作成します。以下の例では、CSV 形式のデータで顧客の性別を表すフィールドを除外した5つのフィールドを持つテーブルを作成します。
CREATE TABLE example_db.example_tbl1
(
`order_id` bigint NOT NULL COMMENT "Order ID",
`pay_dt` date NOT NULL COMMENT "Payment date",
`customer_name` varchar(26) NULL COMMENT "Customer name",
`nationality` varchar(26) NULL COMMENT "Nationality",
`price`double NULL COMMENT "Price"
)
ENGINE=OLAP
PRIMARY KEY (order_id,pay_dt)
DISTRIBUTED BY HASH(`order_id`);
Routine Load ジョブを送信する
以下のステートメントを実行して、トピック ordertest1 のメッセージを消費し、テーブル example_tbl1 にデータをロードする Routine Load ジョブ example_tbl1_ordertest1 を送信します。ロードジョブは、トピックの指定されたパーティションの初期オフセットからメッセージを消費します。
CREATE ROUTINE LOAD example_db.example_tbl1_ordertest1 ON example_tbl1
COLUMNS TERMINATED BY ",",
COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price)
PROPERTIES
(
"desired_concurrent_number" = "5"
)
FROM KAFKA
(
"kafka_broker_list" ="<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest1",
"kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.security.protocol"="SASL_SSL",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="***",
"property.sasl.password"="***"
);
ロードジョブを送信した後、SHOW ROUTINE LOAD ステートメントを実行して、ロードジョブのステータスを確認できます。
-
ロードジョブ名
テーブルに複数のロードジョブが存在する可能性があります。そのため、ロードジョブを送信したときの対応するトピックと時間でロードジョブに名前を付けることをお勧めします。これにより、各テーブルのロードジョブを区別するのに役立ちます。
-
列セパレータ
プロパティ
COLUMN TERMINATED BYは、CSV 形式のデータの列セパレータを定義します。デフォルトは\tです。 -
Kafka ブローカーリスト
"kafka_broker_list" ="<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",Confluent Cloud クラスターへの接続を確立するためのホストとポートのペアのリストです。
Cluster Overview > Cluster Settingsで確認できます。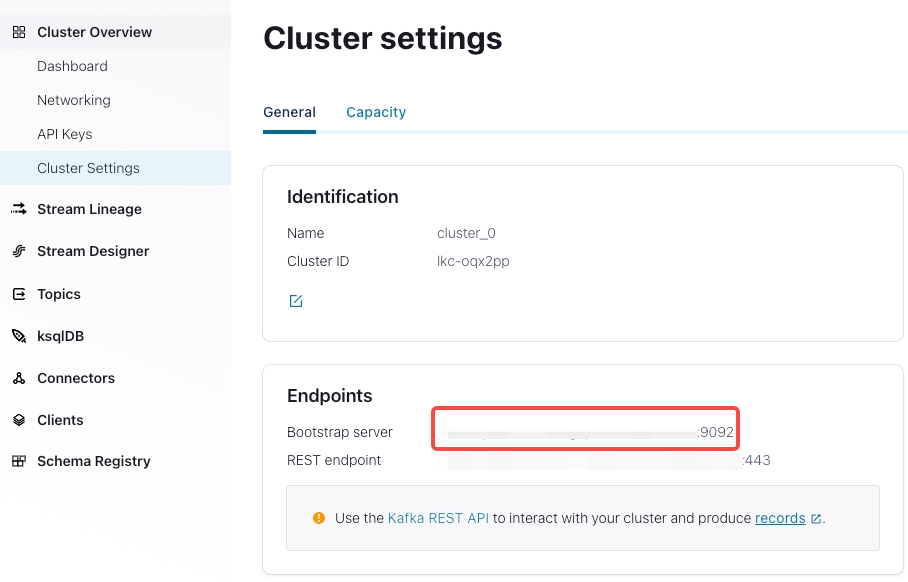
-
トピックパーティションとオフセット
プロパティ
kafka_partitionsとkafka_offsetsを指定して、メッセージを消費するパーティションとオフセットを指定できます。たとえば、トピックordertest1のパーティション"0,1,2,3,4"からすべて初期オフセットでメッセージを消費するロードジョブを作成する場合、プロパティを次のように指定します。"kafka_partitions" ="0,1,2,3,4",
"kafka_offsets" ="OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_END,OFFSET_END"また、すべてのパーティションのデフォルトオフセットをプロパティ
property.kafka_default_offsetsで設定することもできます。"kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"詳細については、CREATE ROUTINE LOAD を参照してください。
-
データのマッピングと変換
CSV 形式のデータと CelerData テーブルの間のマッピングと変換の関係を指定す�るには、
COLUMNSパラメータを使用する必要があります。-
データのマッピング
CelerData は CSV 形式のデータの列を抽出し、それらを
COLUMNSパラメータで宣言されたフィールドに順番にマッピングします。 CelerData はCOLUMNSパラメータで宣言されたフィールドを抽出し、それらを CelerData テーブルの列に名前でマッピングします。 -
データの変換
この例では、CSV 形式のデータから顧客の性別を表す列を除外しています。そのため、
COLUMNSパラメータのフィールドtemp_genderはこのフィールドのプレースホルダーとして使用されます。他のフィールドは CelerData テーブルexample_tbl1の列に直接マッピングされます。注意
CSV 形式のデータの列の名前、数、および順序が CelerData テーブルのものと完全に一致する場合、
COLUMNSパラメータを指定する必要はありません。
-
-
タスクの同時実行性
トピックパーティションが多く、十分な BE ノードがある場合、タスクの同時実行性を高めることでロードを加速できます。
実際のロードタスクの同時実行性を高めるには、Routine Load ジョブを作成する際に
desired_concurrent_numberの値を増やすことができます。また、動的 FE 設定項目max_routine_load_task_concurrent_numを大きな値に設定することもできます。この FE 設定項目は�、デフォルトの最大ロードタスク通貨を指定します。実際のタスクの同時実行性は、存続している BE ノードの数、事前に指定されたトピックパーティションの数、および
desired_concurrent_numberとmax_routine_load_task_concurrent_numの値の最小値によって定義されます。この例では、存続している BE ノードの数は
5、事前に指定されたトピックパーティションの数は5、max_routine_load_task_concurrent_numの値は5です。実際のロードタスクの同時実行性を高めるために、デフォルト値3から5にdesired_concurrent_numberの値を増やすことができます。プロパティの詳細については、CREATE ROUTINE LOAD を参照してください。
-
暗号化と認証
"property.security.protocol"="SASL_SSL",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="***",
"property.sasl.password"="***"-
property.security.protocol: Confluent Cloud はデフォルトでSASL_SSLを使用するため、SASL_SSLを使用できます。注意
本番環境では
SASL_PLAINTEXTを使用することは推奨されません。 -
property.sasl.mechanism: シンプルなユーザー名/パスワード認証メカニズムであるPLAINを使用できます。 -
property.sasl.username: Confluent Cloud クラスターの API キーです。Cluster Overview > API Keysで確認できます。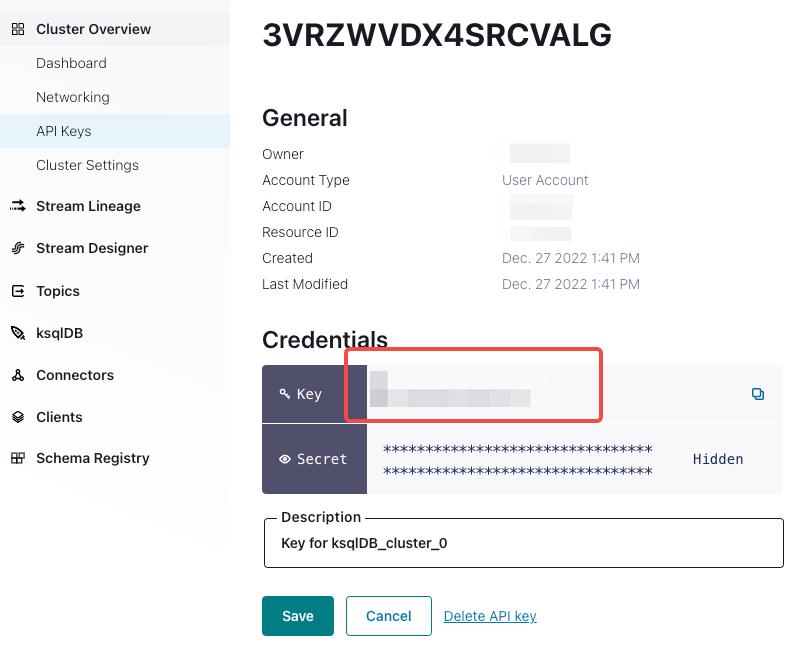
-
property.sasl.password: Confluent Cloud クラスターの API シークレットです。クラスター作成時にダウンロードした txt ファイルで確認できます。
-
JSON 形式のデータをロードする
このセクションでは、Confluent Cloud クラスターで JSON 形式のデータを消費し、Routine Load ジョブを作成して CelerData にデータをロードする方法を説明します。
データセットを準備する
Confluent Cloud クラスターのトピック ordertest2 に JSON 形式のデータセットがあるとします。データセットには、商品 ID、顧客名、国籍、支払い時間、価格を表す6つのキーが含まれています。さらに、支払い時間キーを DATE 型に変換し、CelerData テーブルの pay_dt 列にロードしたいとします。
{"commodity_id": "1", "customer_name": "Mark Twain", "country": "US","pay_time": 1589191487,"price": 875}
{"commodity_id": "2", "customer_name": "Oscar Wilde", "country": "UK","pay_time": 1589191487,"price": 895}
{"commodity_id": "3", "customer_name": "Antoine de Saint-Exupéry","country": "France","pay_time": 1589191487,"price": 895}
注意
各 JSON オブジェクトは1つのメッセージに含まれている必要があります。そうでない場合、JSON パースエラーが返されます。
テーブルを作成する
JSON 形式のデータのキーに基づいて、データベース example_db にテーブル example_tbl2 を作成します。
CREATE TABLE `example_tbl2`
(
`commodity_id` varchar(26) NULL COMMENT "Commodity ID",
`customer_name` varchar(26) NULL COMMENT "Customer name",
`country` varchar(26) NULL COMMENT "Country",
`pay_time` bigint(20) NULL COMMENT "Payment time",
`pay_dt` date NULL COMMENT "Payment date",
`price`double SUM NULL COMMENT "Price"
)
ENGINE=OLAP
PRIMARY KEY(`commodity_id`,`customer_name`,`country`,`pay_time`,`pay_dt`)
DISTRIBUTED BY HASH(`commodity_id`);
Routine Load ジョブを送信する
以下のステートメントを実行して、トピック ordertest2 のメッセージを消費し、テーブル example_tbl2 にデータをロードする Routine Load ジョブ example_tbl2_ordertest2 を送信します。ロードタスクは、トピックの指定されたパーティションの初期オフセットからメッセージを消費します。
CREATE ROUTINE LOAD example_db.example_tbl2_ordertest2 ON example_tbl2
COLUMNS(commodity_id, customer_name, country, pay_time, price, pay_dt=from_unixtime(pay_time, '%Y%m%d'))
PROPERTIES
(
"desired_concurrent_number"="5",
"format" ="json",
"jsonpaths" ="[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]"
)
FROM KAFKA
(
"kafka_broker_list" ="<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest2",
"kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.security.protocol"="SASL_SSL",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="***",
"property.sasl.password"="***"
);
ロードジョブを送信した後、SHOW ROUTINE LOAD ステートメントを実行して、ロードジョブのステータスを確認できます。
- データ形式
PROPERTIES の節で "format"="json" を指定して、データ形式が JSON であることを定義する必要があります。
-
データのマッピングと変換
JSON 形式のデータと CelerData テーブルの間のマッピングと変換の関係を指定するには、
COLUMNSパラメータとプロパティjsonpathsを指定する必要があります。COLUMNSパラメータで指定されたフィールドの順序は、JSON 形式のデータの順序と一致し、フィールドの名前は CelerData テーブルの名前と一致する必要があります。プロパティjsonpathsは、JSON データから必要なフィールドを抽出するために使用されます。これらのフィールドは、プロパティCOLUMNSによって命名されます。この例では、支払い時間フィールドを DATE データ型に変換し、CelerData テーブルの
pay_dt列にデータをロードする必要があるため、from_unixtime関数を使用する必要があります。他のフィールドはテーブルexample_tbl2のフィールドに直接マッピングされます。-
データのマッピング
CelerData は JSON 形式のデータの
nameとcodeキーを抽出し、それらをjsonpathsプロパティで宣言されたキーにマッピングします。 CelerData はjsonpathsプロパティで宣言されたキーを抽出し、それらをCOLUMNSパラメータで宣言されたフィールドに順番にマッピングします。 CelerData はCOLUMNSパラメータで宣言されたフィールドを抽出し、それらを CelerData テーブルの列に名前でマッピングします。 -
データの変換
この例では、キー
pay_timeを DATE データ型に変換し、CelerData テーブルのpay_dt列にデータをロードする必要があるため、COLUMNSパラメータでfrom_unixtime関数を使用する必要があります。他のフィールドはテーブルexample_tbl2のフィールドに直接マッピングされます。 したがって、この例では JSON 形式のデータから顧客の性別を表す列を除外しているため、COLUMNSパラメータのフィールドtemp_genderはこのフィールドのプレースホルダーとして使用されます。他のフィールドは CelerData テーブルexample_tbl1の列に直接マッピングされます。注意
JSON オブジェクトのキーの名前と数が CelerData テーブルのフィールドと完全に一致する場合、
COLUMNSパラメータを指定する必要はありません。
-
ロードジョブとタスクを確認する
ロードジョブを確認する
SHOW ROUTINE LOAD ステートメントを実行して、ロードジョブ example_tbl2_ordertest2 のステータスを確認します。CelerData は、実行状態 State、統計情報(消費された総行数とロードされた総行数を含む)Statistics、およびロードジョブの進行状況 progress を返します。
ロードジョブの状態が自動的に PAUSED に変更された場合、エラーロウの数がしきい値を超えた可能性があります。このしきい値の設定に関する詳細な指示については、CREATE ROUTINE LOAD を参照してください。問題を特定してトラブルシューティングするために、ReasonOfStateChanged および ErrorLogUrls ファイルを確認できます。問題を修正した後、RESUME ROUTINE LOAD ステートメントを実行して、PAUSED ロードジョブを再開できます。
ロードジョブの状態が CANCELLED の場合、ロードジョブが例外に遭遇した可能性があります(たとえば、テーブルが削除されたなど)。問題を特定してトラブルシューティングするために、ReasonOfStateChanged および ErrorLogUrls ファイルを確認できます。ただし、CANCELLED ロードジョブを再開することはできません。
MySQL [example_db]> SHOW ROUTINE LOAD FOR example_tbl2_ordertest2 \G
*************************** 1. row ***************************
Id: 63013
Name: example_tbl2_ordertest2
CreateTime: 2022-08-10 17:09:00
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:example_db
TableName: example_tbl2
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 3
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"commodity_id,customer_name,country,pay_time,pay_dt=from_unixtime(`pay_time`, '%Y%m%d'),price","maxBatchIntervalS":"20","whereExpr":"*","dataFormat":"json","timezone":"Asia/Shanghai","format":"json","json_root":"","strict_mode":"false","jsonpaths":"[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]","desireTaskConcurrentNum":"3","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"3","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"ordertest2","currentKafkaPartitions":"0,1,2,3,4","brokerList":"<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>"}
CustomProperties: {"security.protocol":"SASL_SSL","sasl.username":"******","sasl.mechanism":"PLAIN","kafka_default_offsets":"OFFSET_BEGINNING","sasl.password":"******"}
Statistic: {"receivedBytes":230,"errorRows":0,"committedTaskNum":1,"loadedRows":2,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":2,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":522}
Progress: {"0":"1","1":"OFFSET_ZERO","2":"OFFSET_ZERO","3":"OFFSET_ZERO","4":"OFFSET_ZERO"}
ReasonOfStateChanged:
ErrorLogUrls:
OtherMsg:
注意
停止したロードジョブやまだ開始されていないロードジョブを確認することはできません。
ロードタスクを確認する
SHOW ROUTINE LOAD TASK ステートメントを実行して、ロードジョブ example_tbl2_ordertest2 のロードタスクを確認します。現在実行中のタスクの数、消費されるトピックパーティションと消費進行状況 DataSourceProperties、および対応するコーディネータ BE ノード BeId などを確認できます。
MySQL [example_db]> SHOW ROUTINE LOAD TASK WHERE JobName = "example_tbl2_ordertest2" \G
*************************** 1. row ***************************
TaskId: 18c3a823-d73e-4a64-b9cb-b9eced026753
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:05
LastScheduledTime: 2022-08-10 17:47:27
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"1":0,"4":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
*************************** 2. row ***************************
TaskId: f76c97ac-26aa-4b41-8194-a8ba2063eb00
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:05
LastScheduledTime: 2022-08-10 17:47:26
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"2":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
*************************** 3. row ***************************
TaskId: 1a327a34-99f4-4f8d-8014-3cd38db99ec6
TxnId: -1
TxnStatus: UNKNOWN
JobId: 63013
CreateTime: 2022-08-10 17:09:26
LastScheduledTime: 2022-08-10 17:47:27
ExecuteStartTime: NULL
Timeout: 60
BeId: -1
DataSourceProperties: {"0":2,"3":0}
Message: there is no new data in kafka, wait for 20 seconds to schedule again
ロードジョブを一時停止する
PAUSE ROUTINE LOAD ステートメントを実行して、ロードジョブを一時停止できます。ステートメントが実行されると、ロードジョブの状態は PAUSED になりますが、停止していません。RESUME ROUTINE LOAD ステートメントを実行して再開できます。SHOW ROUTINE LOAD ステートメントでそのステータスを確認することもできます。
以下の例では、ロードジョブ example_tbl2_ordertest2 を一時停止します。
PAUSE ROUTINE LOAD FOR example_tbl2_ordertest2;
ロードジョブを再開する
RESUME ROUTINE LOAD ステートメントを実行して、一時停止されたロードジョブを再開できます。ロードジョブの状態は一時的に NEED_SCHEDULE になり(ロードジョブが再スケジュールされているため)、その後 RUNNING になります。SHOW ROUTINE LOAD ステートメントでそのステータスを確認できます。
以下の例では、一時停止されたロードジョブ example_tbl2_ordertest2 を再開します。
RESUME ROUTINE LOAD FOR example_tbl2_ordertest2;
ロードジョブを変更する
ロードジョブを変更する前に、PAUSE ROUTINE LOAD ステートメントで一時停止する必要があります。その後、ALTER ROUTINE LOAD を実行できます。変更後、RESUME ROUTINE LOAD ステートメントを実行して再開し、SHOW ROUTINE LOAD ステートメントでそのステータスを確認できます。
存続している BE ノードの数が 6 に増加し、消費されるトピックパーティションが "0,1,2,3,4,5,6,7" になったとします。実際のロードタスクの同時実行性を高めたい場合、以下のステートメントを実行して、希望するタスクの同時実行数 desired_concurrent_number を 6 に増やし(存続している BE ノードの数以上)、トピックパーティションと初期オフセットを指定します。
注意
実際のタスクの同時実行性は複数のパラメータの最小値によって決定されるため、FE 動的パラメータ
max_routine_load_task_concurrent_numの値が6以上であることを確認する必要があ��ります。
ALTER ROUTINE LOAD FOR example_tbl2_ordertest2
PROPERTIES
(
"desired_concurrent_number" = "6"
)
FROM kafka
(
"kafka_partitions" = "0,1,2,3,4,5,6,7",
"kafka_offsets" = "OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_BEGINNING,OFFSET_END,OFFSET_END,OFFSET_END,OFFSET_END"
);
ロードジョブを停止する
STOP ROUTINE LOAD ステートメントを実行して、ロードジョブを停止できます。ステートメントが実行されると、ロードジョブの状態は STOPPED になり、停止したロードジョブを再開することはできません。SHOW ROUTINE LOAD ステートメントで停止したロードジョブのステータスを確認することはできません。
以下の例では、ロードジョブ example_tbl2_ordertest2 を停止します。
STOP ROUTINE LOAD FOR example_tbl2_ordertest2;
FAQ
-
問題の説明: Routine Load ジョブが SQL ステートメント
show routine load <my_job>を実行したときにReasonOfStateChangedフィールドでno partition in this topicというエラーを報告します。ErrorReason{errCode = 4, msg='Job failed to fetch all current partition with error [failed to send proxy request to TNetworkAddress(hostname:10.0.1.2, port:8060) err failed to send proxy request to TNetworkAddress(hostname:10.0.1.2, port:8060) err [no partition in this topic]]'}考えられる原因:
kafka_topicプロパティが正しくありません。たとえば、トピックが存在しない、またはkafka_partitionsプロパティが正しく設定されていないなどです。 -
問題の説明: Routine Load ジョブが SQL ステートメント
SHOW ROUTINE LOAD <my_job>を実行したときにReasonOfStateChangedフィールドでfailed to get partition meta: Local: Broker transport failureというエラーを報告します。ErrorReason{errCode = 4, msg='Job failed to fetch all current partition with error [failed to send proxy request to TNetworkAddress(hostname:10.0.1.2, port:8060) err failed to send proxy request to TNetworkAddress(hostname:10.0.1.2, port:8060) err [failed to get partition meta: Local: Broker transport failure]]'}考えられる原因: SSL チャネルが確立できません。
解決策: CelerData から Confluent Cloud への SSL 証明書検証を無効にしてトラブルシューティングを行うことができます。
"property.enable.ssl.certificate.verification"="false"
注意
- 安全ではないため、本番環境では無効にする必要があります。
- Confluent Cloud 上で新しい一時的な API キーのペアを生成し、セキュリティ目的で
username/passwordプロパティとして使用する必要があります。SSL 証明書検証が無効になっている場合、インターネットを介してユーザー名/パスワードが安全ではありません。
その後、Routine Load ジョブが CelerData にデータを正常にロードする場合、SSL 証明書に問題がある可能性があります。たとえば、CelerData が CA ルート証明書を自動的に見つけられないなどです。そのため、以下のプロパティを追加して CelerData に手動で CA ルート証明書を指定できます。CA ルート証明書の詳細については、librdkafka - INTRODUCTION.md # SSL を参照してください。
"property.ssl.ca.location"="/etc/ssl/certs/ca-bundle.crt"