Kafka コネクタを使用して Confluent Cloud からデータをロードする
このトピックでは、Kafka コネクタ、starrocks-kafka-connector を使用して、Confluent から CelerData にメッセージ(イベント)をストリームする方法を紹介します。Kafka コネクタは、少なくとも一度のセマンティクスを保証します。
Kafka コネクタは Kafka Connect とシームレスに統合でき、これにより CelerData は Kafka エコシステムとより良く統合されます。リアルタイムデータを CelerData にロードしたい場合、賢明な選択です。Routine Load と比較して、以下のシナリオで Kafka コネクタが推奨されます:
- Routine Load がサポートする CSV、JSON、Avro フォーマット以外の Protobuf などのさまざまなフォーマットでデータをロードします。データが Kafka Connect のコンバータを使用して JSON および CSV フォーマットに変換できる限り、Kafka コネクタを介して CelerData にデータをロードできます。
- Debezium 形式の CDC データなど、データ変換をカスタマイズします。
- 複数の Kafka トピックからデータをロードします。
- Confluent Cloud からデータをロードします。
- ロードバッチサイズ、並行性、およびその他のパラメータを細かく制御して、ロード速度とリソース利用のバランスを取る必要があります。
始める前に
Confluent クラスターがインターネット経由で CelerData クラスターに接続できることを確認してください。
CelerData クラスターのネットワーク設定を構成する
-
CelerData クラスターがインターネットから接続できることを確認します。特に、CelerData クラスターがプライベートサブネットにある場合です。CelerData クラスターがパブリックサブネットにある場合、デフォルトでインターネット経由で接続できます。このトピックでは、パブリックサブネットにある CelerData クラスターを例として使用します。
-
CelerData クラスターのリソースが関連付けられているセキュリティグループが、Confluent クラスターからのトラフィックを許可していることを確認します。
-
CelerData Cloud BYOC コンソール にサインインし、CelerData クラスターが関連付けられている Security Group ID を見つけます。

-
Amazon VPC コンソール にサインインします。
-
左側のナビゲーションペインで Security Groups を選択します。表示されるページで、CelerData クラスターのリソースが関連付けられているセキュリティグループを見つけます。
-
Inbound Rules タブで、Edit inbound rules を選択します。
-
赤枠で強調表示された次のルールを追加します:
ポート
443と9030を追加する必要があります。
-
基本的な手順
次の例は、Confluent Cloud から CelerData に Avro 形式のレコードをロードする方法を示しています。
- ソースコネクタを使用して、Confluent クラスターのトピックにデータを生成します。次の例では、ソースコネクタは Datagen Source で、データ形式は Avro です。
- CelerData テーブルを作成します。
- シンクコネクタ(カスタムコネクタ、starrocks-kafka-connector を使用する必要があります)を使用して、Confluent クラスターのトピックから CelerData テーブルにデータをロードします。
Confluent クラスターのトピックにデータを生成する
-
Confluent クラスターを選択し、その Connectors ページに入り、+ Add Connector をクリックします。その後、ソースコネクタとして Datagen Source を選択します。
-
Datagen Source コネクタを構成します。
-
Topic 選択セクションで:
+ Add new topic をクリックし、トピックの名前とパーティション番号を指定します。この例では、トピックの名前を
datagen_topicと指定します。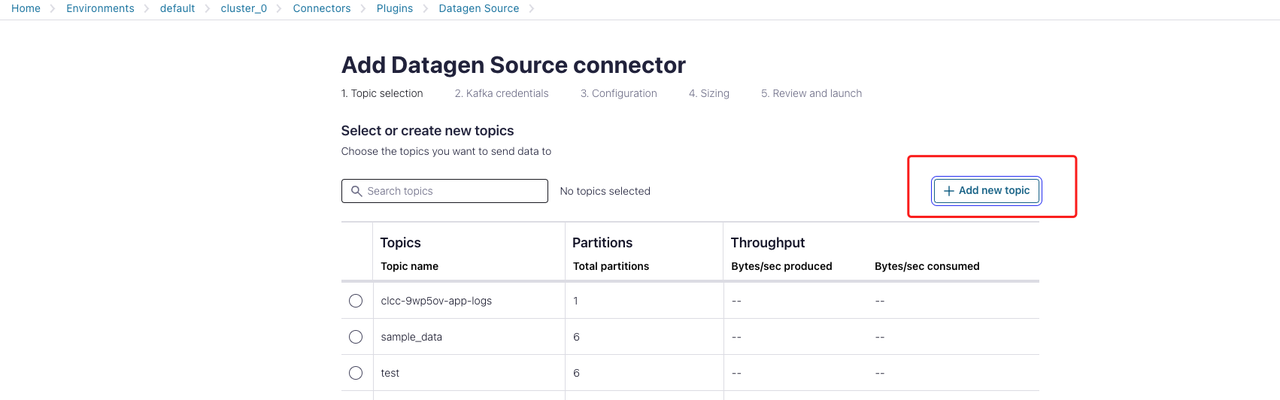
-
Kafka credentials セクションで:
この例はロードプロセスに素早く慣れるための簡単なガイドなので、Global access を選択し、Generate API key & download をクリックします。
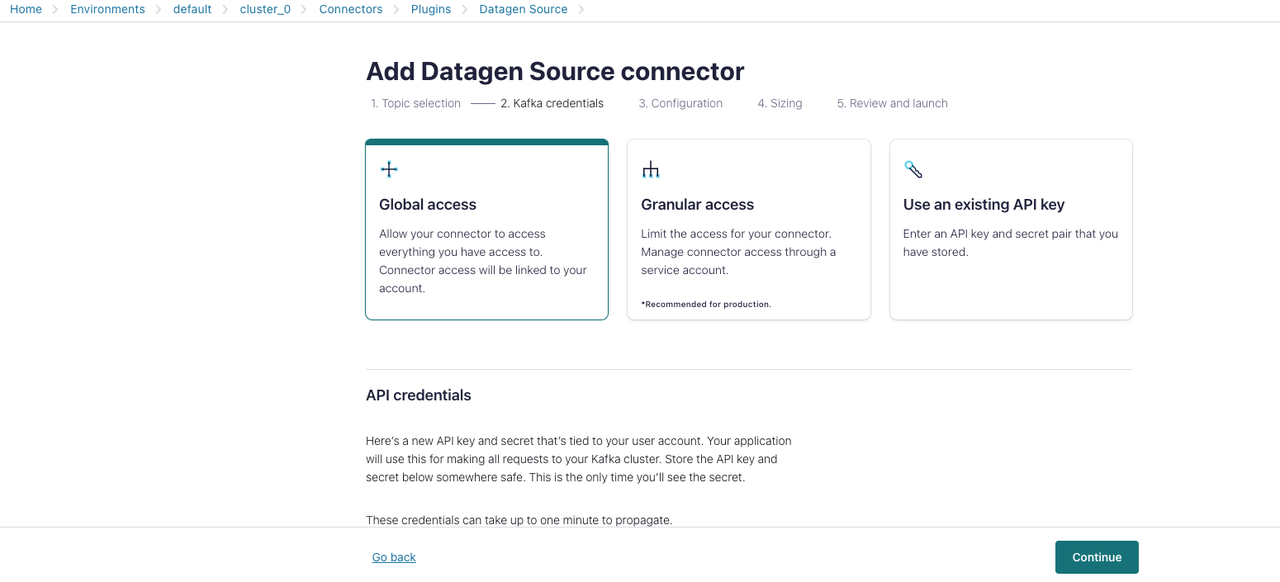
-
Configuration セクションで:
出力レコードの値の形式とテンプレートを選択します。この例では、形式を
AVRO、テンプレートをordersと指定します。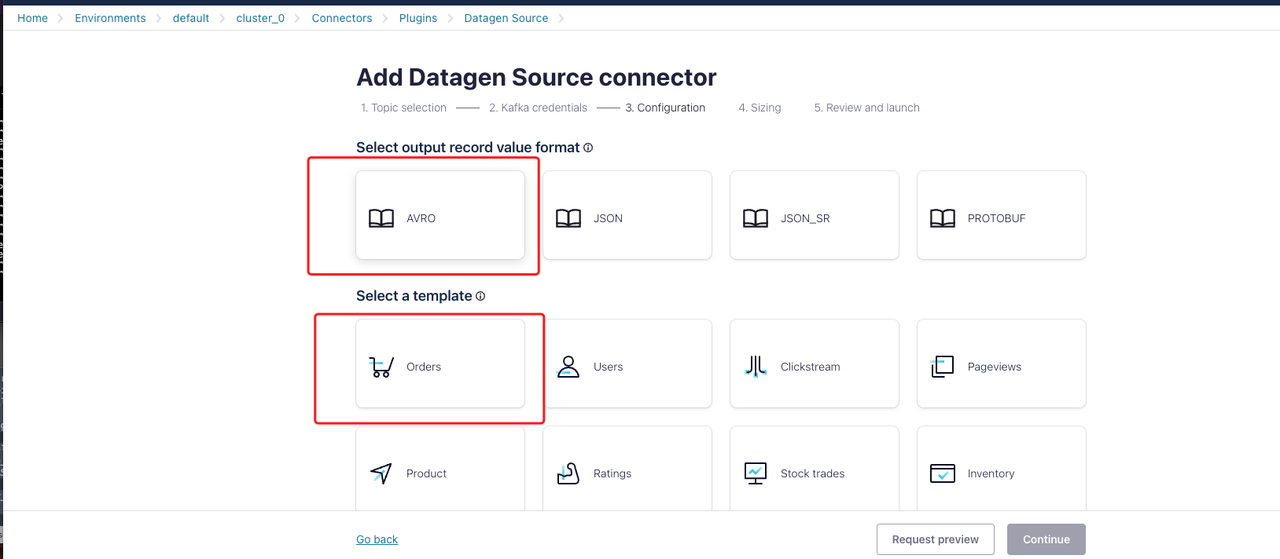
-
Sizing セクションで:
デフォルトの設定を使用します。
-
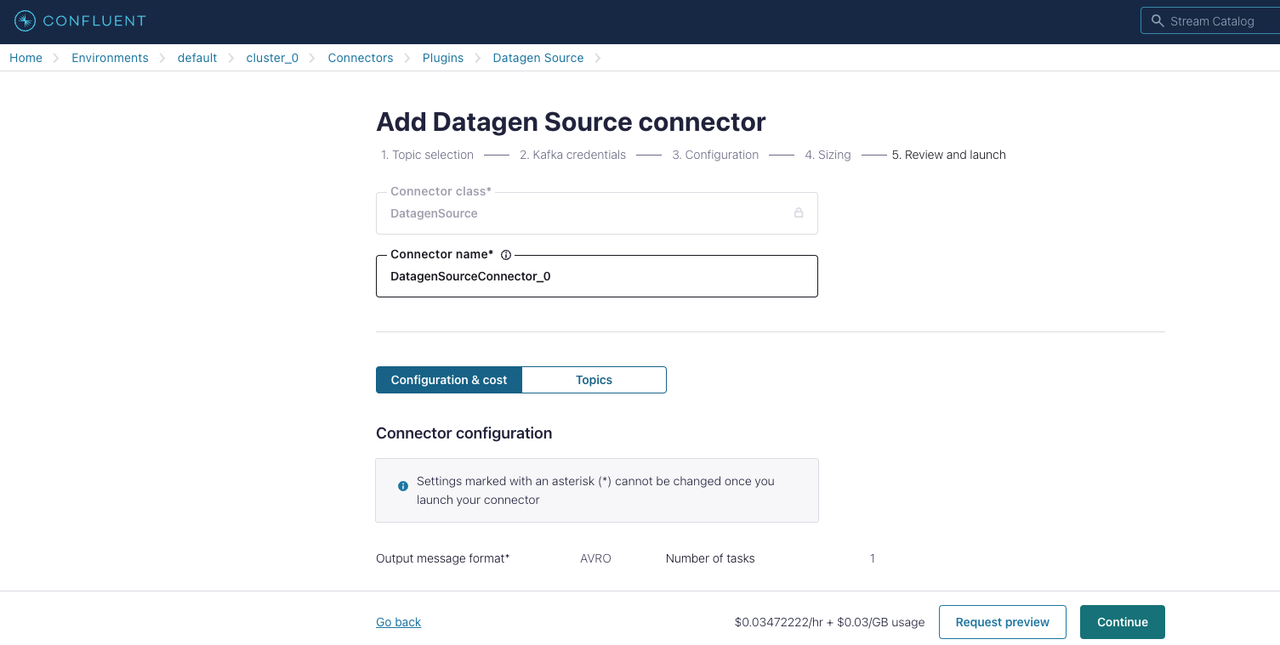
Review and launch セクションで:
Datagen ソースコネクタの設定を確認し、すべての設定を検証したら Continue をクリックします。
-
-
Connectors ページで、追加した Datagen ソースコネクタを確認します。
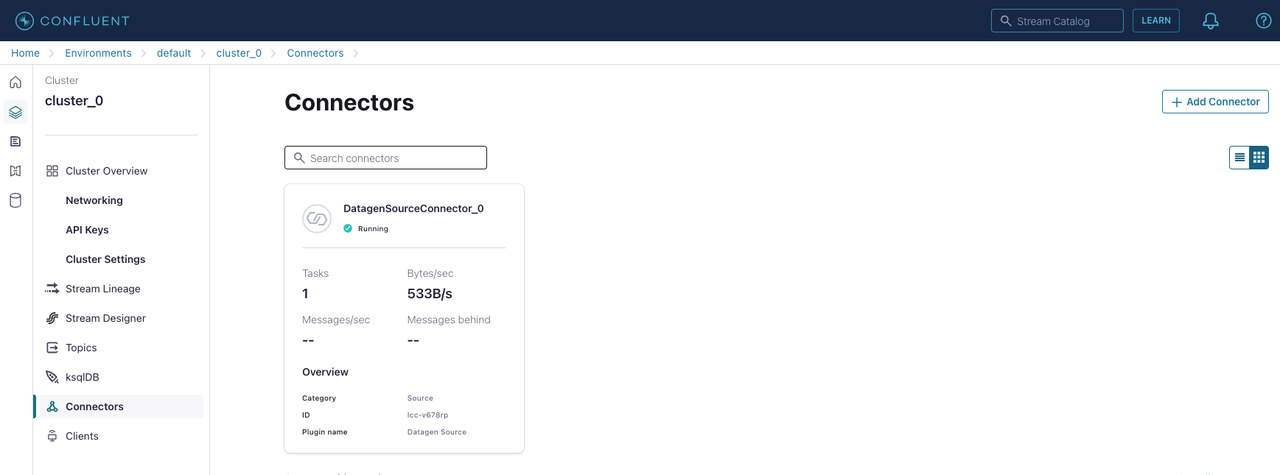
Datagen ソースコネクタが稼働すると、トピック
datagen_topicにメッセージが入力されていることを確認できます。
CelerData クラスターにテーブルを作成する
トピック datagen_topic の Avro 形式のレコードのスキーマに従って、CelerData クラスターにテーブルを作成します。
CREATE TABLE test123 (
ordertime LARGEINT,
orderid int,
itemid string,
orderunits string,
city string,
state string,
zipcode bigint
)
DISTRIBUTED BY HASH(orderid);
CelerData テーブルにデータをロードする
この例では、シンクコネクタ(Kafka コネクタである starrocks-kafka-connector)を使用して、Confluent トピックから CelerData テーブルに Avro 形式のレコードをロードします。
NOTE
starrocks-kafka-connector という名前の Kafka コネクタはカスタムコネクタであり、カスタムコネクタは Confluent Cloud がサポートする AWS リージョン でのみ作成できます。カスタムコネクタの機能と制限についての詳細は、Confluent Documentation を参照してください。
-
Confluent クラスターの Connectors ページに入り、+ Add Connector をクリックし、Add plugin をクリックします。
-
Kafka コネクタのアーカイブをアップロードします。
-
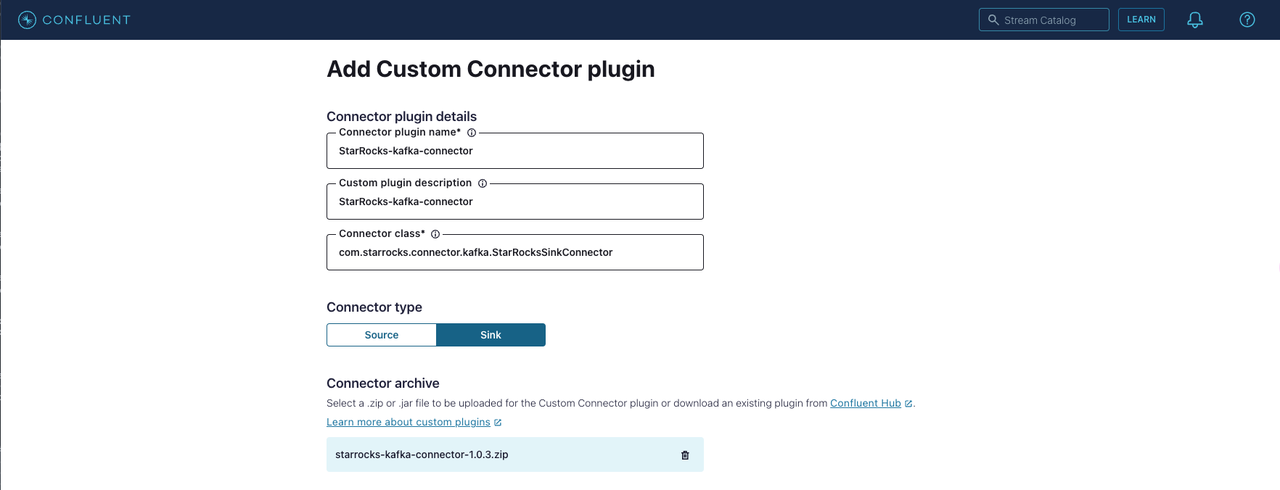
Connector plugin detail:
- Connector plugin name: Kafka コネクタの名前を入力します。例えば
StarRocks-kafka-connector。 - Custom plugin description: Kafka コネクタの説明を入力します。
- Connector class: Kafka コネクタの Java クラスを入力します。これは
com.starrocks.connector.kafka.StarRocksSinkConnectorです。
- Connector plugin name: Kafka コネクタの名前を入力します。例えば
-
Connector type: コネクタタイプを Sink として選択します。
-
Connector archive: Select connector archive をクリックし、Kafka コネクタの ZIP ファイルをアップロードします。
Kafka コネクタの TAR ファイルを Github からダウンロードし、TAR ファイルを解凍します。すべてのファイルを ZIP ファイルに圧縮し、その ZIP ファイルをアップロードする必要があります。
-
-
Kafka コネクタを構成して起動します。
-
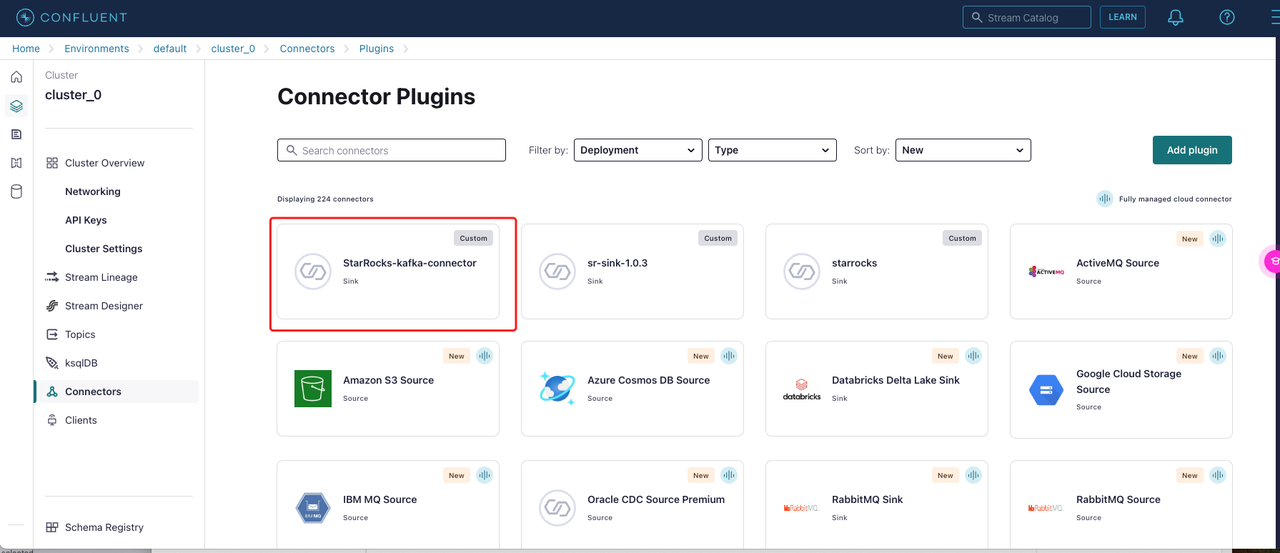
Confluent クラスターの Connectors ページに入り、+ Add Connector をクリックし、StarRocks-kafka-connector を選択します。
-
Kafka credentials セクションで:
この例はロードプロセスに素早く慣れるための簡単なガイドなので、Global access を選択し、Generate API key & download をクリックします。
-
Configuration セクションで:
キーと値のペアまたは JSON 形式で設定を追加します。この例では、JSON 形式で設定を追加します。
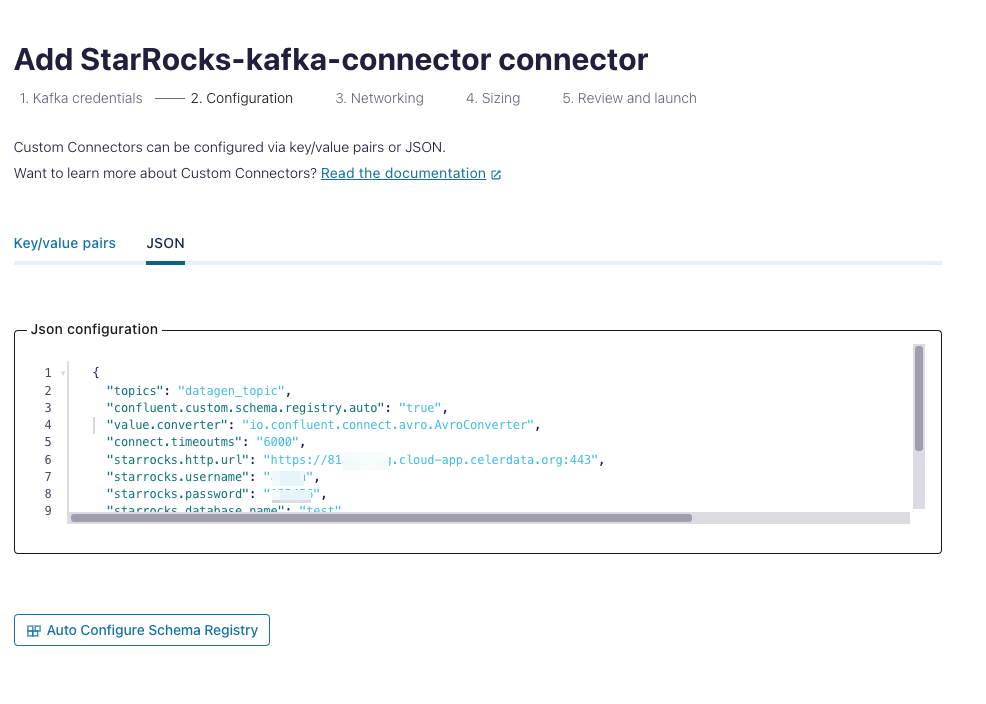
完全な JSON 形式の設定は以下の通りです:
{
"topics": "datagen_topic",
"confluent.custom.schema.registry.auto": "true",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"connect.timeoutms": "6000",
"starrocks.http.url": "https://81xxxxxxx.cloud-app.celerdata.org:443",
"starrocks.username": "xxxxxx",
"starrocks.password": "xxxxxx",
"starrocks.database.name": "test",
"starrocks.topic2table.map": "datagen_topic:test123",
"sink.properties.strip_outer_array": "true",
"sink.properties.jsonpaths": "[\"$.ordertime\",\"$.orderid\",\"$.itemid\",\"$.orderunits\",\"$.address.city\",\"$.address.state\",\"$.address.zipcode\"]"
}設定:
サポートされている設定と説明については、Parameters を参照してください。以下の設定に特に注意してください:
-
starrocks.http.url: CelerData クラスターの HTTP URL をhttps://<endpoint>:443の形式で入力します。エンドポイントは CelerData クラスターの Overview ページの接続セクションで見つけることができます。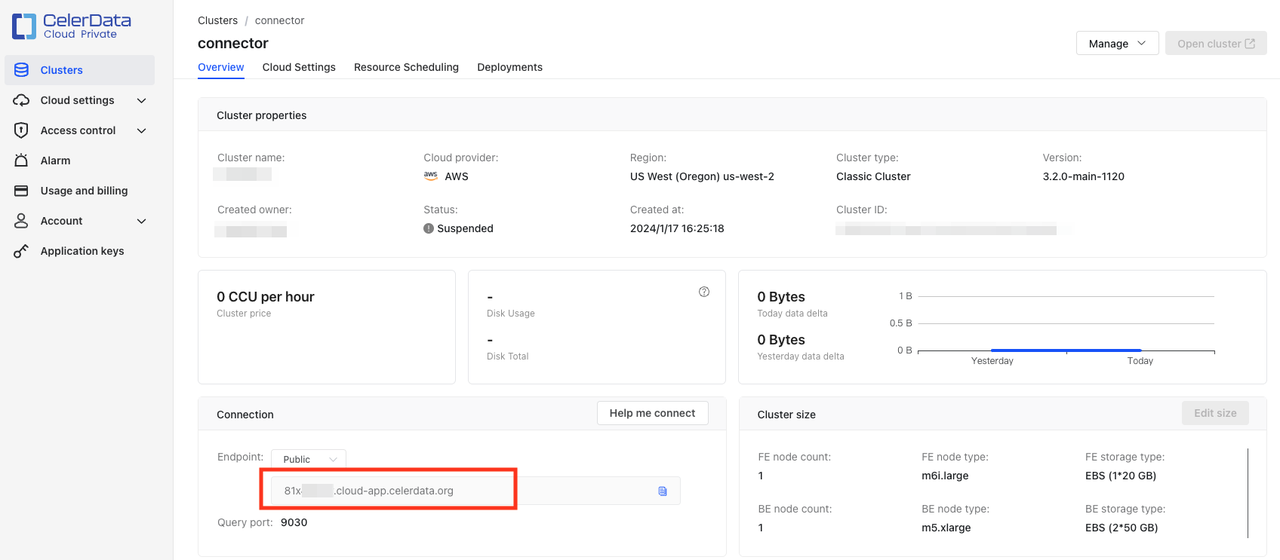
-
また、ソースデータ形式に応じて追加する必要がある設定もあります。
この例では、ソースデータは AVRO レコードであり、Confluent Cloud Schema Registry が使用されているため、必要な設定には
confluent.custom.schema.registry.autoとvalue.converterも含める必要があります。詳細については、Confluent Documentation を参照してください。{
"topics": "datagen_topic",
"confluent.custom.schema.registry.auto": "true",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"connect.timeoutms": "6000",
"starrocks.http.url": "https://81xxxxxxx.cloud-app.celerdata.org:443",
"starrocks.username": "xxxxxx",
"starrocks.password": "xxxxxx",
"starrocks.database.name": "test",
"starrocks.topic2table.map": "datagen_topic:test123",
"sink.properties.strip_outer_array": "true",
"sink.properties.jsonpaths": "[\"$.ordertime\",\"$.orderid\",\"$.itemid\",\"$.orderunits\",\"$.address.city\",\"$.address.state\",\"$.address.zipcode\"]"
}ソースデータが Schema Registry を使用しない JSON レコードの場合、必要な設定には以下も含める必要があります:
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",完全な設定は以下のようになります:
{
"topics": "datagen_topic",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"connect.timeoutms": "6000",
"starrocks.http.url": "https://81xxxxxxx.cloud-app.celerdata.org:443",
"starrocks.username": "xxxxxx",
"starrocks.password": "xxxxxx",
"starrocks.database.name": "test",
"starrocks.topic2table.map": "datagen_topic:test123",
"sink.properties.strip_outer_array": "true",
"sink.properties.jsonpaths": "[\"$.ordertime\",\"$.orderid\",\"$.itemid\",\"$.orderunits\",\"$.address.city\",\"$.address.state\",\"$.address.zipcode\"]"
}
-
-
Networking セクションで:
接続エンドポイントの形式を
<endpoint>:443:TCPとして入力します。エンドポイントはstarrocks.http.urlのエンドポイントと同じで、形式はhttps://<endpoint>:443です。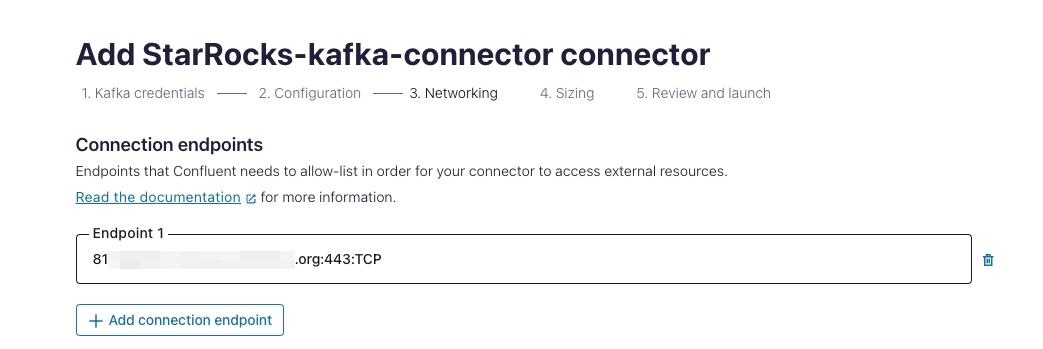
-
Sizing セクションで:
デフォルトの設定を使用します。
-
Review and launch セクションで:
Kafka コネクタの設定を確認し、すべての設定を検証したら Continue をクリックします。
-
-
Connectors ページで、起動した Kafka コネクタを確認します。
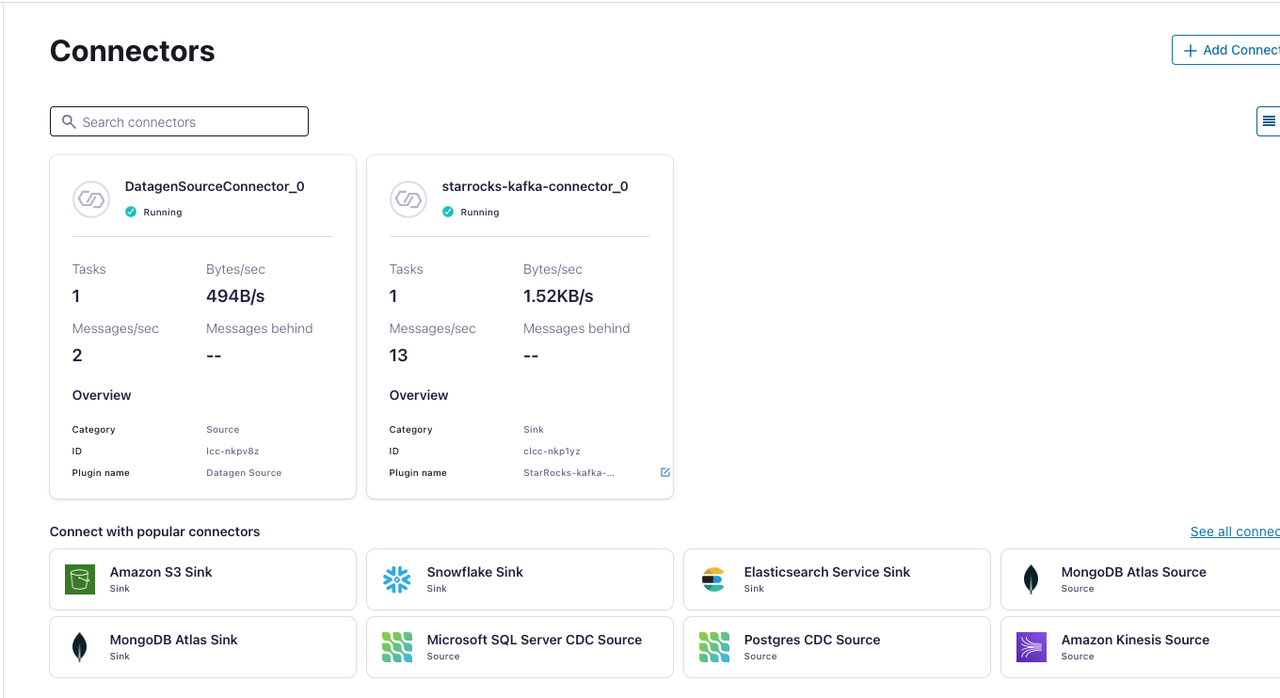
Kafka コネクタがプロビジョニングを完了すると、ステータスが稼働中に変わります。
-
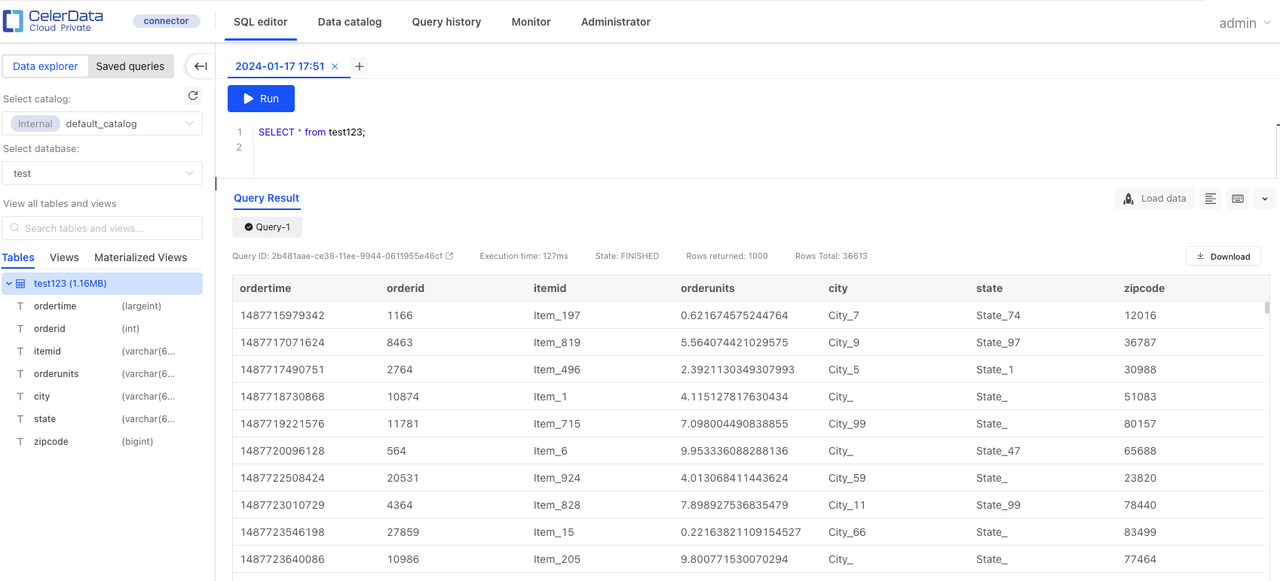
両方のコネクタが稼働した後、CelerData テーブルのデータを確認します。
パラメータ
name
- 必須: YES
- デフォルト値:
- 説明: この Kafka コネクタの名前。Kafka Connect クラスター内のすべての Kafka コネクタ間でグローバルに一意である必要があります。例えば、starrocks-kafka-connector。
connector.class
- 必須: YES
- デフォルト値: com.starrocks.connector.kafka.SinkConnector
- 説明: この Kafka コネクタのシンクで使用されるクラス。
topics
- 必須: YES
- デフォルト値:
- 説明: 購読する 1 つ以上のトピックで、各トピックは CelerData テーブルに対応します。デフォルトでは、CelerData はトピック名が CelerData テーブルの名前と一致すると仮定します。そのため、CelerData はトピック名を使用してターゲット CelerData テーブルを決定します。
topicsまたはtopics.regex(下記)のいずれかを選択して入力してください。ただし、CelerData テーブル名がトピック名と異なる場合は、オプションのstarrocks.topic2table.mapパラメータ(下記)を使用してトピック名からテーブル名へのマッピングを指定してください。
topics.regex
- 必須:
- デフォルト値:
- 説明: 購読する 1 つ以上のトピックに一致する正規表現。詳細については、
topicsを参照してください。topics.regexまたはtopics(上記)のいずれかを選択して入力してください。
starrocks.topic2table.map
- 必須: NO
- デフォルト値:
- 説明: トピック名が CelerData テーブル名と異なる場合の CelerData テーブル名とトピック名のマッピング。形式は
<topic-1>:<table-1>,<topic-2>:<table-2>,...です。
starrocks.http.url
- 必須: YES
- デフォルト値:
- 説明: CelerData クラスターの HTTP URL。形式は
https://<endpoint>:443です。エンドポイントは CelerData クラスターの Overview ページの接続セクションで見つけることができます。
starrocks.database.name
- 必須: YES
- デフォルト値:
- 説明: CelerData データベースの名前。
starrocks.username
- 必須: YES
- デフォルト値:
- 説明: CelerData クラスターアカウントのユーザー名。ユーザーは CelerData テーブルに対する INSERT 権限を持っている必要があります。
starrocks.password
- 必須: YES
- デフォルト値:
- 説明: CelerData クラスターアカウントのパスワード。
key.converter
- 必須: NO
- デフォルト値: Kafka Connect クラスターで使用されるキーコンバータ
- 説明: シンクコネクタ(Kafka-connector-starrocks)用のキーコンバータで、Kafka データのキーをデシリアライズするために使用されます。デフォ��ルトのキーコンバータは Kafka Connect クラスターで使用されるものです。
value.converter
- 必須: NO
- デフォルト値: Kafka Connect クラスターで使用される値コンバータ
- 説明: シンクコネクタ(kafka-connector-starrocks)用の値コンバータで、Kafka データの値をデシリアライズするために使用されます。デフォルトの値コンバータは Kafka Connect クラスターで使用されるものです。
key.converter.schema.registry.url
- 必須: NO
- デフォルト値:
- 説明: キーコンバータのスキーマレジストリ URL。
value.converter.schema.registry.url
- 必須: NO
- デフォルト値:
- 説明: 値コンバータのスキーマレジストリ URL。
tasks.max
- 必須: NO
- デフォルト値: 1
- 説明: Kafka コネクタが作成できるタスクスレッドの最大数で、通常は Kafka Connect クラスターのワーカーノードの CPU コア数と同じです。このパラメータを調整してロードパフォーマンスを制御できます。
bufferflush.maxbytes
- 必須: NO
- デフォルト値: 94371840(90M)
- 説明: 一度に CelerData に送信される前にメモリに蓄積できるデータの最大サイズ。最大値は 64 MB から 10 GB の範囲です。Stream Load SDK バッファはデータをバッファするために複数の Stream Load ジョブを作成する場合があ�ることに注意してください。したがって、ここで言及されているしきい値は、総データサイズを指します。
bufferflush.intervalms
- 必須: NO
- デフォルト値: 300000
- 説明: データのバッチを送信する間隔で、ロードの遅延を制御します。範囲:[1000, 3600000]。
connect.timeoutms
- 必須: NO
- デフォルト値: 1000
- 説明: HTTP URL への接続のタイムアウト。範囲:[100, 60000]。
sink.properties.*
- 必須:
- デフォルト値:
- 説明: ロード動作を制御するための Stream Load パラメータ。例えば、パラメータ
sink.properties.formatは Stream Load に使用される形式を指定し、CSV や JSON などがあります。サポートされているパラメータとその説明のリストについては、STREAM LOAD を参照してください。
sink.properties.format
- 必須: NO
- デフォルト値: json
- 説明: Stream Load に使用される形式。Kafka コネクタは、データの各バッチを CelerData に送信する前にその形式に変換します。有効な値:
csvおよびjson。詳細については、CSV パラメータと JSON パラメータを参照してください。
制限事項
- Kafka トピックからの単一メッセージを複数のデータ行にフラット化して CelerData にロードすることはサポートされていません。
- Kafka コネクタのシンクは、少なくとも一度のセマンティクスを保証します。