ローカルファイルシステムからデータをロードする
CelerData を使用すると、Stream Load を利用してローカルファイルシステムからデータをロードできます。
Stream Load は HTTPS ベースの同期ロード方法です。ロードジョブを送信すると、CelerData はジョブを同期的に実行し、ジョブが完了した後にその結果を返します。ジョブの結果に�基づいて、ジョブが成功したかどうかを判断できます。
Stream Load は、ローカルファイルシステムから 10 GB 未満のデータをロードするのに適しています。
対応フォーマット
対応するファイルフォーマットは CSV と JSON です。
CSV データについては、以下の点に注意してください:
- テキスト区切り文字として、カンマ (,) やタブ、パイプ (|) などの UTF-8 文字列を使用できます。長さは 50 バイトを超えないようにしてください。
- Null 値は
\Nを使用して示します。例えば、データファイルが 3 列で構成されており、そのデータファイルのレコードが第 1 列と第 3 列にデータを持ち、第 2 列にデータがない場合、この状況では第 2 列に\Nを使用して Null 値を示す必要があります。つまり、レコードはa,\N,bとしてコンパイルする必要があり、a,,bではいけません。a,,bはレコードの第 2 列が空の文字列を持っていることを示します。
制限事項
Stream Load は、JSON フォーマットの列を含む CSV ファイルのデータロードをサポートしていません。
始める前に
ソースデータの準備
ローカルファイルシステム内のソースデータが準備されていることを確認し、ソースデータが保存されているパスを取得してください。
このトピックでは、2 つのサンプルデータファイルを例として使用します:
-
example1.csvという名前の CSV ファイル。このファイルは、ユーザー ID、ユーザー名、ユーザースコアを順に表す 3 列で構成されています。1,Lily,23
2,Rose,23
3,Alice,24
4,Julia,25 -
example2.jsonという名前の JSON ファイル。このファイルは、都市 ID と都市名を順に表す 2 列で構成されています。{"name": "Beijing", "code": 2}
権限の確認
CelerData クラスター内のテーブルにデータをロードするには、そのテーブルに対する INSERT 権限を持つユーザーである必要があります。INSERT 権限がない場合は、GRANT に従って、CelerData クラスターに接続するために使用するユーザーに INSERT 権限を付与してください。
CelerData クラスターのアカウント admin には、そのクラスター内で有効なすべての権限があります。このアカウントを使用してクラスターに接続する場合、GRANT 操作を実行する必要はありません。
CelerData に接続する
ロードジョブを開始する前に、以下を行う必要があります:
-
CelerData クラスターに接続します。
-
使用する catalog とデータベースを指定します。
このトピックでは、
mydatabaseという名前のデータベースを選択したと仮定します。このデータベースは、CREATE DATABASE ステートメントを使用して作成できます:CREATE DATABASE mydatabase; -
目的のテーブルが準備されていることを確認します。
指定したデータベースにテーブルがない場合は、CREATE TABLE ステートメントを使用してテーブルを作成できます。
このトピックでは、以下のように 2 つのテーブルを作成します:
-
table1という名前の主キーテーブル。このテーブルは、id、name、scoreの 3 列で構成されており、idが主キーです。CREATE TABLE `table1`
(
`id` int(11) NOT NULL COMMENT "user ID",
`name` varchar(65533) NULL COMMENT "user name",
`score` int(11) NOT NULL COMMENT "user score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`); -
table2という名前の主キーテーブル。このテーブルは、idとcityの 2 列で構成されており、idが主キーです。CREATE TABLE `table2`
(
`id` int(11) NOT NULL COMMENT "city ID",
`city` varchar(65533) NULL COMMENT "city name"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);
NOTE
CelerData は、テーブルを作成する際やパーティションを追加する際に、バケット (
BUCKETS) の数を自動的に設定できます。手動でバケットの数を設定する必要はありません。CelerData では、いくつかのリテラルが SQL 言語によって予約キーワードとして使用されています。これらのキーワードを SQL ステートメントで直接使用しないでください。SQL ステートメントでそのようなキーワードを使用する場合は、バッククォート (`) で囲んでください。詳細は Keywords を参照してください。
-
-
目的のクラスターがエラスティッククラスターである場合、使用するウェアハウスも指定してください。
指定したウェアハウスが稼働中であることを確認してください。
このトピックの以下の例では、目的のクラスターがエラスティッククラスターであり、
default_warehouseを目的のウェアハウスとして選択したと仮定します。
Stream Load を開始する
このセクションでは、curl を使用して、ローカルターミナルで CSV または JSON データをロードするための Stream Load ジョブを実行する方法を説明します。
基本的な構文は次のとおりです:
curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
# パラメータ warehouse は、エ��ラスティッククラスターへのデータロードにのみ使用されます。
-H "warehouse:<warehouse_name>" \
# パラメータ column_separator は、CSV データロードにのみ使用されます。
-H "column_separator:<column_separator>" \
# パラメータ jsonpaths は、JSON データロードにのみ使用されます。
-H "jsonpaths: [ \"<json_path1>\"[, \"<json_path2>\", ...] ]" \
-H "columns:<column1_name>[, <column2_name>, ... ]" \
-H "format: CSV | JSON" \
-T <file_path> -XPUT \
https://<fe_host>/api/<database_name>/<table_name>/_stream_load
ロードコマンドは主に以下の部分で構成されています:
-
HTTPS リクエストヘッダー
Expect: 値を"Expect:100-continue"と指定します。 -
<username>:<password>: CelerData クラスターに接続するために使用するアカウントのユーザー名とパスワードを指定します。 -
warehouse: 目的のウェアハウスを指定します。このパラメータは、エラスティッククラスターへのデータロードにのみ必要です。このパラメータを指定しない場合、デフォルトのウェアハウスdefault_warehouseがデータロードに使用されます。目的のウェアハウスが稼働中であることを確認してください。目的のウェアハウスが稼働していない場合、データロードは失敗します。 -
column_separator: CSV データファイルでフィールドを区切るために使用される文字を指定します。デフォルト値は\tで、タブを示します。CSV データファイルがフィールドを区切るためにタブを使用している場合、このパラメータを指定する��必要はありません。 -
jsonpaths: JSON データファイルからロードしたいキーの名前を指定します。このパラメータは、マッチングモードを使用して JSON データをロードする場合にのみ指定する必要があります。このパラメータの値は JSON フォーマットです。詳細は Configure column mapping for JSON data loading を参照してください。 -
columns: データファイルと目的のテーブル間のカラムマッピングを指定します。 -
format: データファイルのフォーマットを指定します。 -
file_path: データファイルの保存パスを指定します。ファイル名の拡張子を含めることができ、その場合はformatパラメータを指定する必要はありません。 -
HTTPS ライン: メソッド
-XPUTと、CelerData クラスター内の目的のテーブルへのパスを含む URL を含みます。
URL構文:
https://<fe_host>/api/<database_name>/<table_name>/_stream_load
以下の表は、URL内のパラメーターについて説明しています。
| パラメータ | 必須 | 説明 |
|---|---|---|
| fe_host | はい | クラスターのパブリックまたはプライベートエンドポイント。CelerData Cloud BYOC コンソールの Overview ページを開き、Connection セクションに移動してエンドポイントを見つけてコピーできます。 |
| database_name | はい | 目的のテーブルが属するデータベースの名前。 |
| table_name | はい | 目的のテーブルの名前。 |
詳細な構文とパラメータの説明については、STREAM LOAD を参照してください。
CSV データをロードする
CSV データファイル example1.csv のデータを、Connect to CelerData で選択したエラスティッククラスターの default_warehouse 内の table1 にロードするには、次のコマンドを実行します:
curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
-H "warehouse:default_warehouse" \
-H "column_separator:," \
-H "columns: id, name, score" \
-T example1.csv -XPUT \
https://<fe_host>/api/mydatabase/table1/_stream_load
example1.csv は 3 列で構成されており、カンマ (,) で区切られており、table1 の id、name、score 列に順番にマッピングされます。そのため、column_separator パラメータを使用してカンマ (,) をカラムセパレータとして指定する必要があります。また、columns パラメータを使用して、example1.csv の 3 列を一時的に id、name、score と名付け、table1 の 3 列に順番にマッピングする必要があります。
カラムマッピングの詳細については、Configure column mapping for CSV data loading を参照してください。
JSON データをロードする
JSON データファイル example2.json のデータを、Connect to CelerData で選択したエラスティッククラスターの default_warehouse 内の table2 にロードするには、次のコマンドを実行します:
curl -v --location-trusted -u <username>:<password> \
-H "strict_mode: true" \
-H "Expect:100-continue" \
-H "warehouse:default_warehouse" \
-H "format: json" \
-H "jsonpaths: [\"$.name\", \"$.code\"]" \
-H "columns: city,tmp_id, id = tmp_id * 100" \
-T example2.json -XPUT \
https://<fe_host>/api/mydatabase/table2/_stream_load
example2.json は name と code の 2 つのキーで構成されており、table2 の id と city 列にマッピングされます。以下の図に示されています。
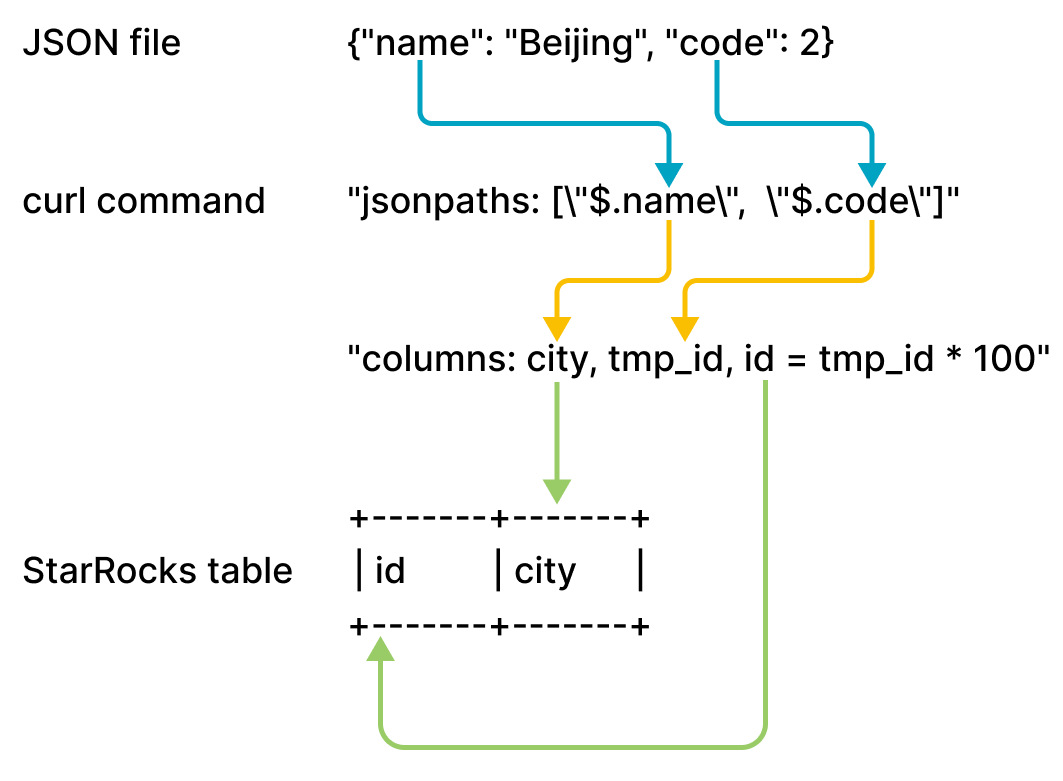
前述の図に示されたマッピングは次のように説明されます:
- CelerData は
example2.jsonのnameとcode�キーを抽出し、それらをjsonpathsパラメータで宣言されたnameとcodeフィールドにマッピングします。 - CelerData は
jsonpathsパラメータで宣言されたnameとcodeフィールドを抽出し、それらをcolumnsパラメータで宣言されたcityとtmp_idフィールドに順番にマッピングします。 - CelerData は
columnsパラメータで宣言されたcityとtmp_idフィールドを抽出し、それらをtable2のcityとid列に名前でマッピングします。
NOTE
前述の例では、
example2.jsonのcodeの値は、table2のid列にロードされる前に 100 倍されます。
カラムマッピングの詳細については、Configure column mapping for JSON data loading を参照してください。
Stream Load の進行状況を確認する
Stream Load ジョブが完了すると、CelerData はジョブの結果を JSON フォーマットで返します。詳細については、STREAM LOAD の「Return value」セクションを参照してください。
Stream Load では、SHOW LOAD ステ��ートメントを使用してロードジョブの結果をクエリすることはできません。
Stream Load ジョブをキャンセルする
Stream Load では、ロードジョブをキャンセルすることはできません。ロードジョブがタイムアウトしたりエラーが発生した場合、CelerData は自動的にジョブをキャンセルします。