GCP でのクイックデプロイ
このトピックでは、Google Cloud でのクイックデプロイの方法を説明します。プロダクション環境用のクラスターを作成したい場合は、代わりに 手動デプロイを設定して実行 する必要があります。
クイックデプロイは、Terraform テンプレートを起動して、必要な資格情報を作成し、必要な GCP リソースをプロビジョニングおよび設定するのに役立ちます。
クイックデプロイはプロダクション用途には適しておらず、非プロダクション用途にのみ推奨されます。
クイックデプロイは、手動デプロイで使用できるすべての構成オプションをサポートしていません。次のような場合は、手動デプロイ メソッドを使用してください:
- 既存のデータ資格情報を再利用する
- デプロイ資格情報を再利用する
- 新しいデータまたはデプロイ資格情報を作成する
- ネットワークアクセスを手動で設定する
前提条件
クイックデプロイを開始する前に、以下を行ってください:
- Google Cloud プロジェクトを作成し、必要な API を有効にする。プロジェクトダッシュボードの Project info セクションから Project ID をコピーし、後でアクセスできる場所に保存します。
- クイックデプロイ用の Cloud Storage バケットとサービスアカウントを作成する。
デプロイウィザードを開始する
デプロイウィザードを開始するには、次の手順に従います:
- CelerData Cloud BYOC コンソール にサインインします。
- Clusters ページで、Create cluster をクリックします。
- 表示されるダイアログボックスで、Classic cluster または Elastic cluster を選択し、クラウドプロバイダーとして GCP を選択し、Next をクリックします。
クイックデプロイを設定して実行する
デプロイウィザードを開始した後は、デプロイウィザードの STEP1 を完了し、必要な情報を提供するだけです。CelerData が残りのステップを完了します。
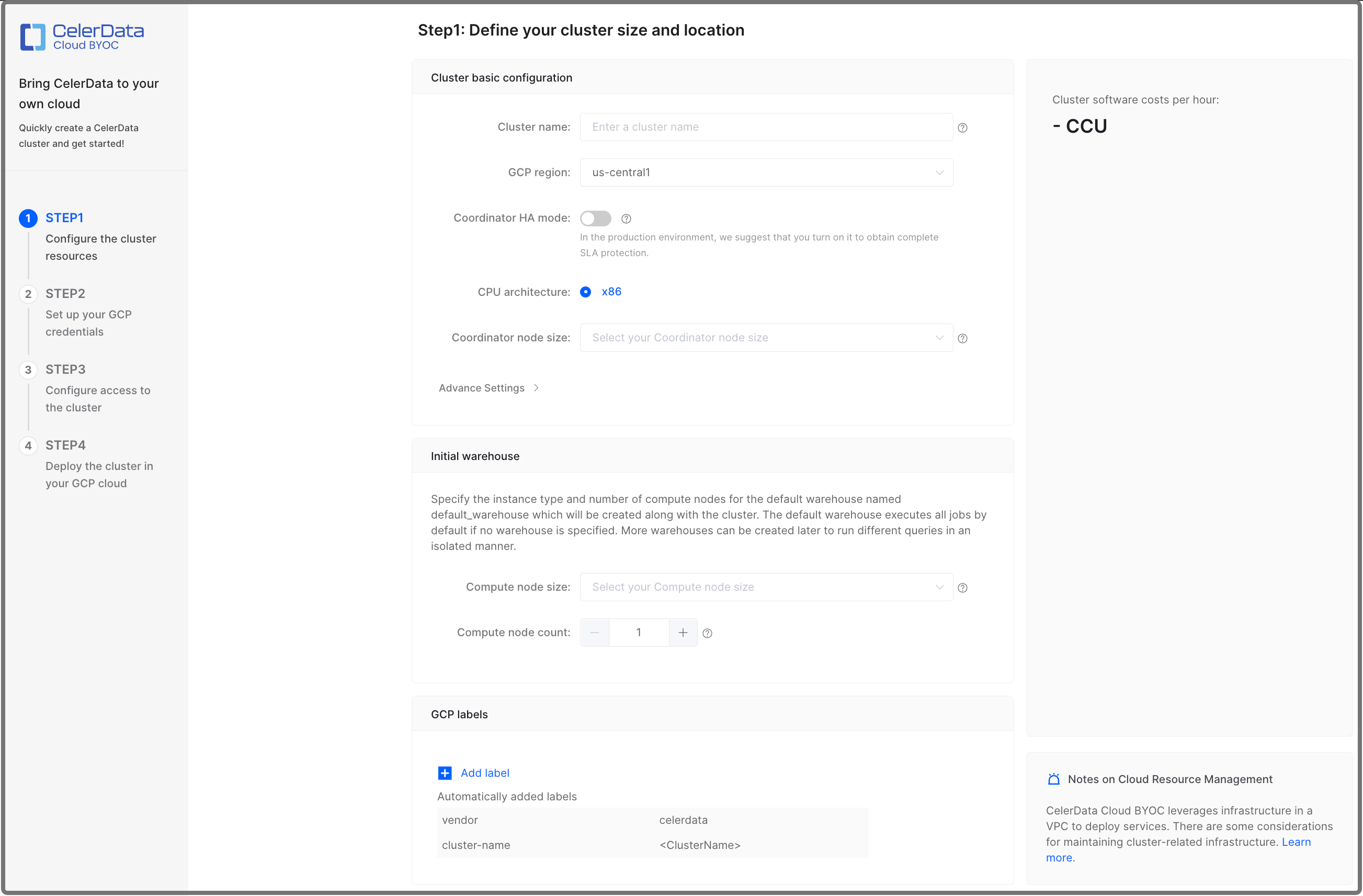
クラスターリソースを設定する
STEP1: クラスターリソースを設定する で、ビジネス要件に基づいてクラスターを設定し、オプションで Add label をクリックしてクラスターに1つ以上のラベルを追加します。その後、Quick deployment をクリックして続行します。ここで追加したラベルは、クラスターに関連付けられた GCP クラウドリソースに添付されます。
- CelerData は Free Developer Tier を提供しています。これを使用するには、4 CPU コアと 16-GB RAM を提供するインスタンスタイプを選択する必要があります。
- 4 CPU コアと 16-GB RAM は、CelerData ノードの最小構成パッケージでもあります。
以下の構成項目を設定します。
| パラメータ | 必須 | 説明 |
|---|---|---|
| Cluster name | はい | クラスターの名前を入力します。クラスターが作成された後、名前は変更できません。後でクラスターを簡単に識別できるように、情報を含む名前を入力することをお勧めします。 |
| GCP region | はい | クラスターをホストする GCP リージョンを選択します。CelerData がサポートするリージョンについては、Supported cloud platforms and regions を参照してください。 |
| CelerData enterprise version | はい | CelerData エンタープライズソフトウェア(データベースカーネル)のバージョンを選択してください。最新の安定版と最新のプレビュー版から選択できます。詳細については、Public Preview と Private Preview の機能をご覧ください。 |
| Coordinator HA mode | いいえ | コーディネータの HA モードを有効または無効にします。コーディネータの HA モードはデフォルトで無効になっています。
|
| Coordinator node size | はい | クラスター内のコーディネータノードのインスタンスタイプを選択します。CelerData がサポートするインスタンスタイプについては、Supported instance types を参照してください。 |
| Compute node size | はい | クラスター内のデフォルトウェアハウスのコンピュートノードのインスタンスタイプを選択します。CelerData がサポートするインスタンスタイプについては、Supported instance types を参照してください。 |
| Compute node count | はい | クラスター内のデフォルトウェアハウスのコンピュートノードの数を指定します。処理するデータ量に基づいてコンピュートノードの数を決定できます。デフォルト値は 1 です。 |
| Compute storage size | はい | デフォルトウェアハウスのコンピュートノードのストレージサイズを指定します。 |
| Compute disk IOPS | いいえ | デフォルトウェアハウスのコンピューティングノードのディスク IOPS を指定します。このフィールドは Hyperdisk Balanced インスタンスタイプでのみ利用可能です。範囲:[3000, 16000] |
| Compute disk throughput | いいえ | デフォルトのウェアハウスのコンピューティングノードのディスクスループットを指定します。このフィールドは Hyperdisk Balanced インスタンスタイプでのみ利用可能です。範囲:[125, 1000] |
Advance Settings では、次のことができます:
-
終了保護を有効にする。
終了保護を有効にすると、クラスターが誤って削除されるのを防ぎ、データ損失のリスクを排除できます。クラスターに対して終了保護が有効になっている場合、クラスターを削除しようとすると失敗し、エラーが返されます。クラスターを削除するには、まず手動で終了保護を無効にする必要があります。
クラスターが作成された後、この機能を有効または無効にすることができます。クラスター詳細ページの Cluster parameters タブの Cluster Configuration セクションで行います。
-
コーディネータノードのストレージ自動スケーリングポリシーを定義する。
ストレージの自動スケーリングはデフォルトで有効になっています。CelerData は、事前設定されたストレージ容量が不足していると検知した場合、ポリシーに基づいてストレージサイズを自動的に拡大します。
注記クラスターのワークロードが予測不能で、ストレージが急速に枯渇し重大なクラスター障害を引き起こす可能性がある場合、ストレージの自動スケーリングを有効にしておくことを強く推奨します。
ストレージ自動スケーリングポリシーを定義するには、以下の手順に従ってください:
-
自動スケーリング操作をトリガーするストレージ使用率のしきい値(パーセンテージ)を設定します。このしきい値は 80% から 90% の間で設定可能です。ノードのストレージ使用率がこのしきい値に達し、5分以上継続した場合、CelerData は次の手順で定義したステップサイズに従ってストレージをスケールアップします。
-
各自動スケーリング操作のステップサイズを設定します。ステップサイズは固定サイズ(GB)またはパーセンテージ(例:50GB または元のストレージサイズの 15%)で設定できます。
-
各ノードの最大ストレージサイズを設定します。CelerData は、ストレージサイズがこの閾値に達するとスケールアップを停止します。
注記- 2 回のスケーリング操作(手動スケーリングと自動スケーリングを含む)の間隔は、最低 4 時間以上を必須とします。
- 各ストレージの最大サイズは 64TB です。
- Elastic クラスター内のコンピュートノードはストレージ自動スケーリングをサポートしません。
-
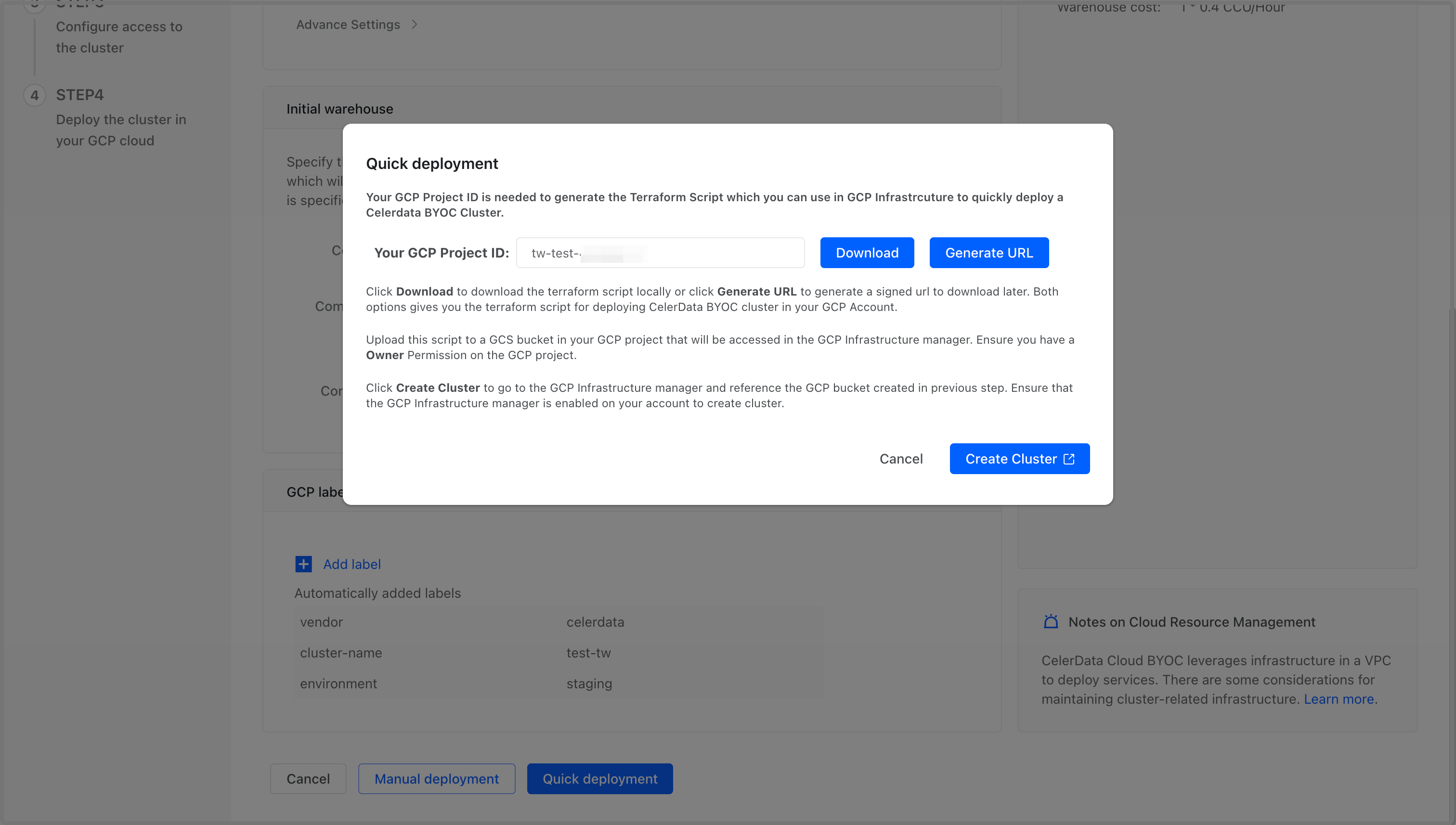
Google Cloud でリソースを起動する
Quick deployment ダイアログボックスで、次の手順に従います:
-
先ほどコピーした Google Cloud の Project ID を Your GCP Project ID フィールドに貼り付けます。
-
Download をクリックしてスクリプトパッケージファイルを直接ダウンロードするか、Generate URL をクリックして後でファイルをダウンロードするための署名付き URL を生成します。パッケージ内のスクリプトは、Google Could Infrastructure Manager がクラスターのために必要なリソースを起動および管理するためのテンプレートです。
-
Google Cloud console にサインインし、クイックデプロイ用に作成した Cloud Storage バケットにパッケージファイルをアップロードします。パッケージを解凍する必要はありません。Cloud Storage バケットにファイルをアップロードする詳細な手順については、Google Cloud Official Document - Upload an object to a bucket を参照してください。
-
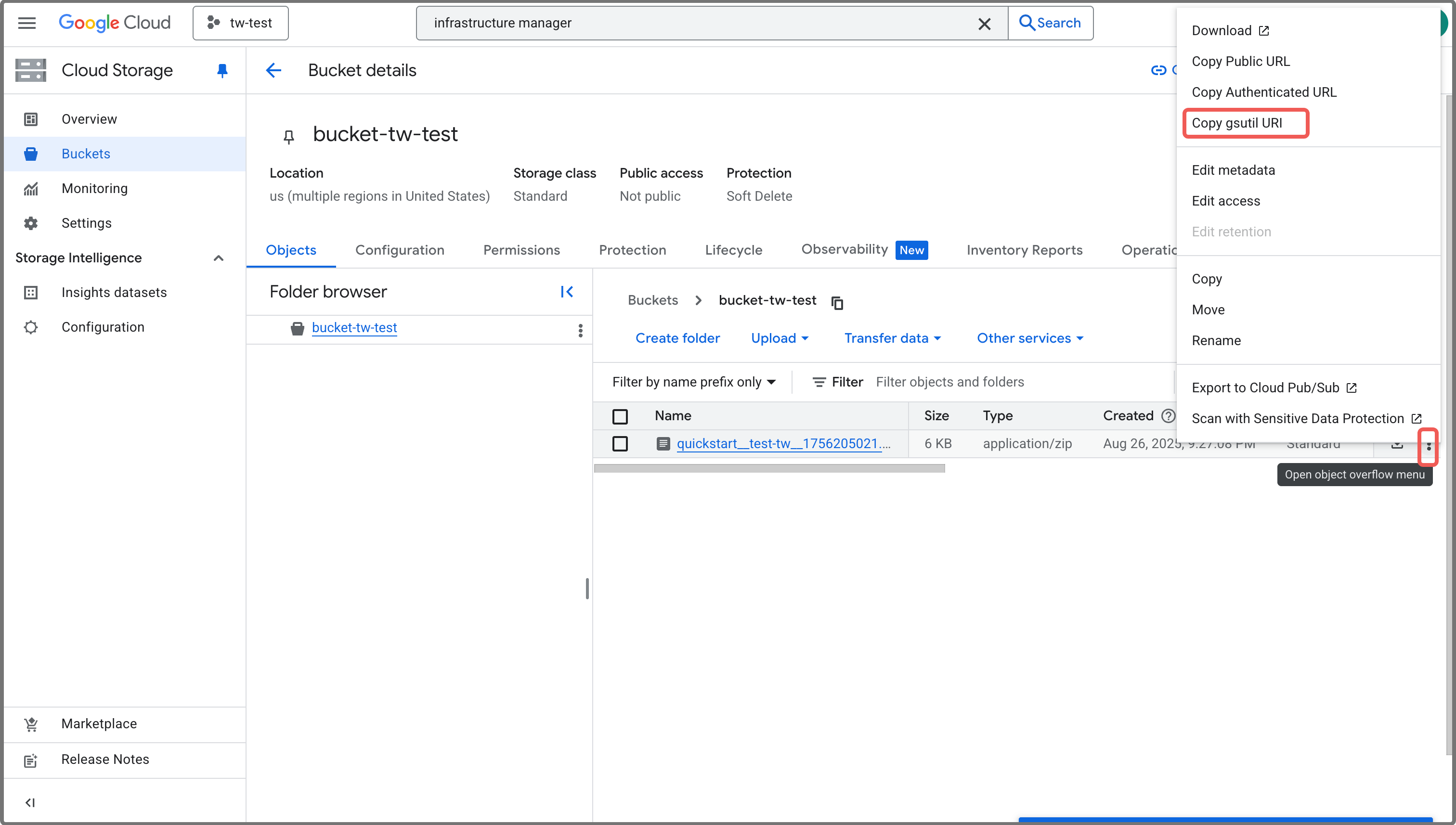
パッケージファイルが正常にアップロードされた後、アップロードしたパッケージファイルの gsutil URI をコピーし、後でアクセスできる場所に保存します。
注記gsutil URI は
gs://<BUCKET_NAME>/<FOLDER_NAME>/<FILE_NAME>の形式です。アップロードしたパッケージの gsutil URI がわからない場合は、Google Cloud console から URI を取得するために次の手順に従います:
- Google Cloud console にサインインします。
- 左側のナビゲーションメニューを展開し、Cloud Storage > Buckets を選択します。
- パッケージファイルをアップロードしたバケットをクリックします。
- Bucket details ページで、パッケージファイルのレコードを見つけます。
- レコードの右側にある More actions (⋮) ボタンをクリックし、Copy gsutil URI を選択して URI をコピーします。
-
Create Cluster をクリックします。
その後、Google Cloud console の Infrastructure Manager ページにリダイレクトされます。
リダイレクトされた後、CelerData Cloud BYOC コンソールを閉じないでください。後でデプロイを完了するためにコンソールに戻る必要があります。
Infrastructure Manager ページで、次の手順に従います:
-
Create new deployment をクリックして、Create new Terraform deployment ページに移動します。
-
Deployment details ステップで、次のように構成します:
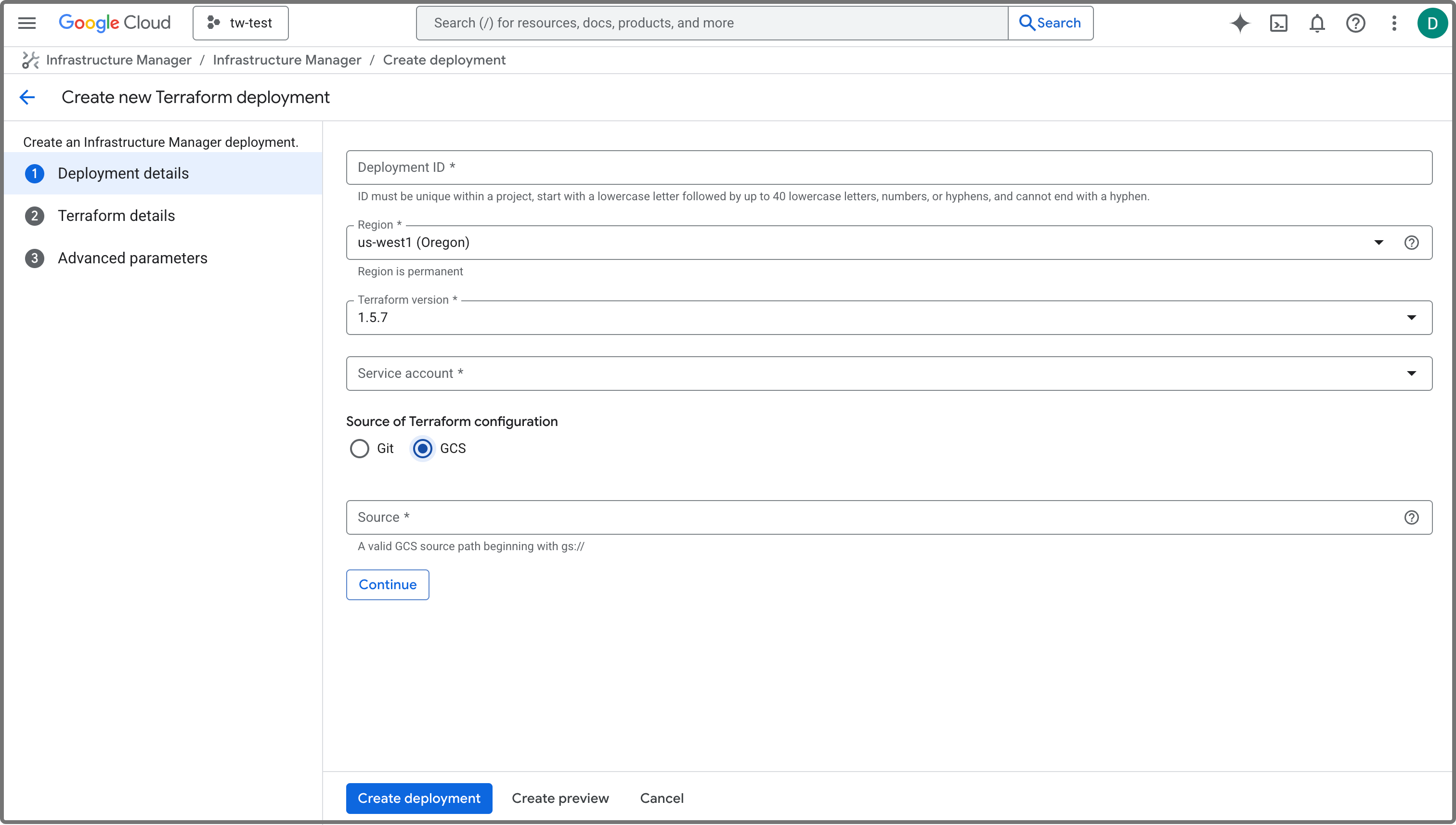
a. Deployment ID フィールドにデプロイの ID を指定します。ID は Google Cloud プロジェクト内で一意である必要があります。
b. Region ドロップダウンリストからデプロイのリージョンを選択します。クラスターをデプロイしたいリージョンに設定することをお勧めします。
c. Service account ドロップダウンリストから、クイックデプロイ用に作成したサービスアカウント を選択します。
d. Source of Terraform configuration として GCS を選択します。
e. 先ほどコピーしたパッケージファイルの gsutil URI を Source フィールドに貼り付けます。
-
Create deployment をクリックします。
その後、作成したデプロイの詳細ページにリダイレクトされます。デプロイの作成には数分かかります。デプロイが正常に作成されると、デプロイの State が Creating から Active に変わります。その後、次のステップに進むことができます。
クラスターをデプロイする
デプロイを完了するために次の手順に従います:
-
CelerData Cloud BYOC コンソールに戻ります。
-
表示されたメッセージで、Finish をクリックします。その後、コンソールの Cluster ページにリダイレクトされます。
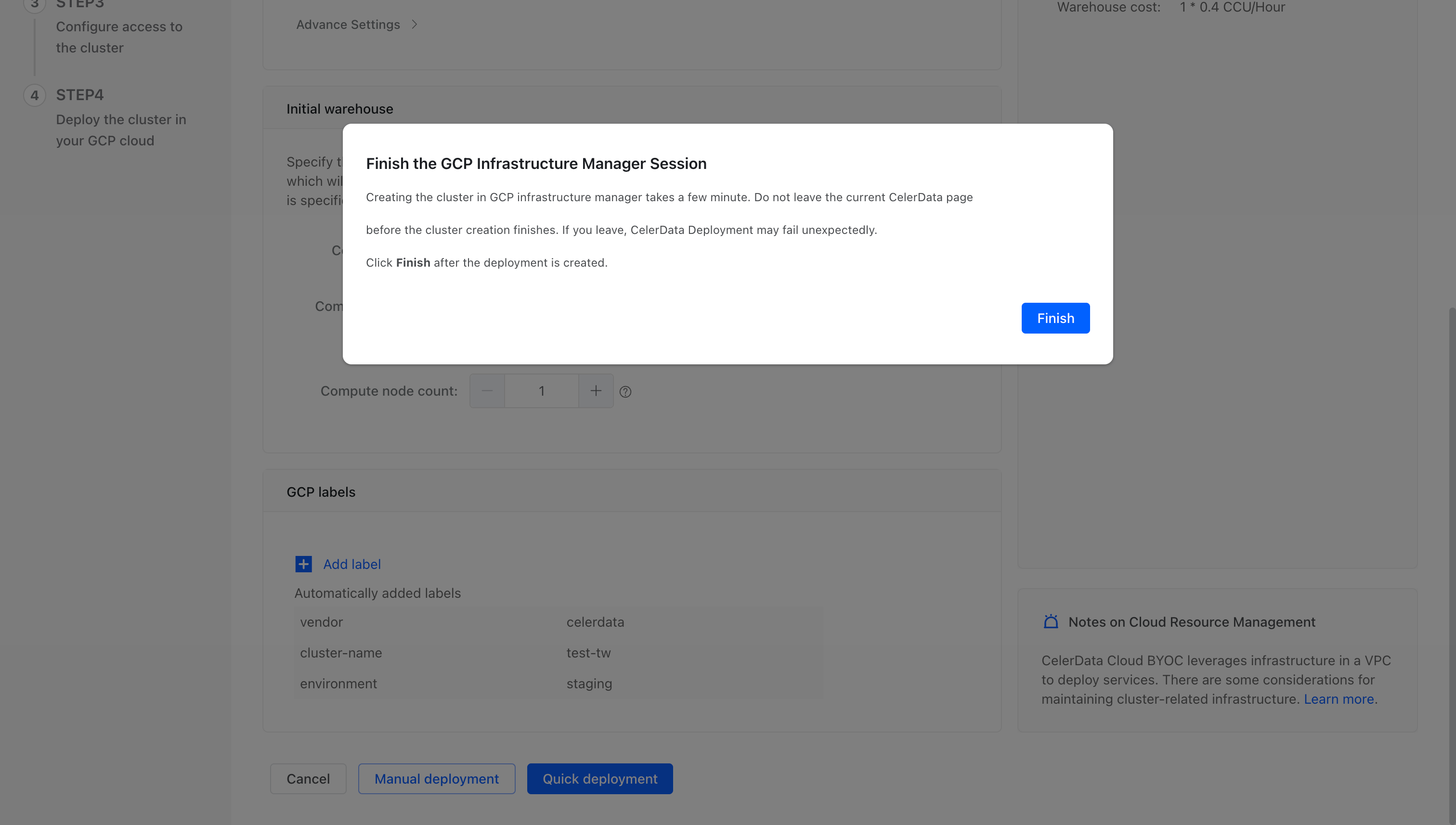
-
作成したクラスターをクリックします。
上記の手順を完了すると、CelerData が自動的にクラスターをデプロイします。これには数分かかります。
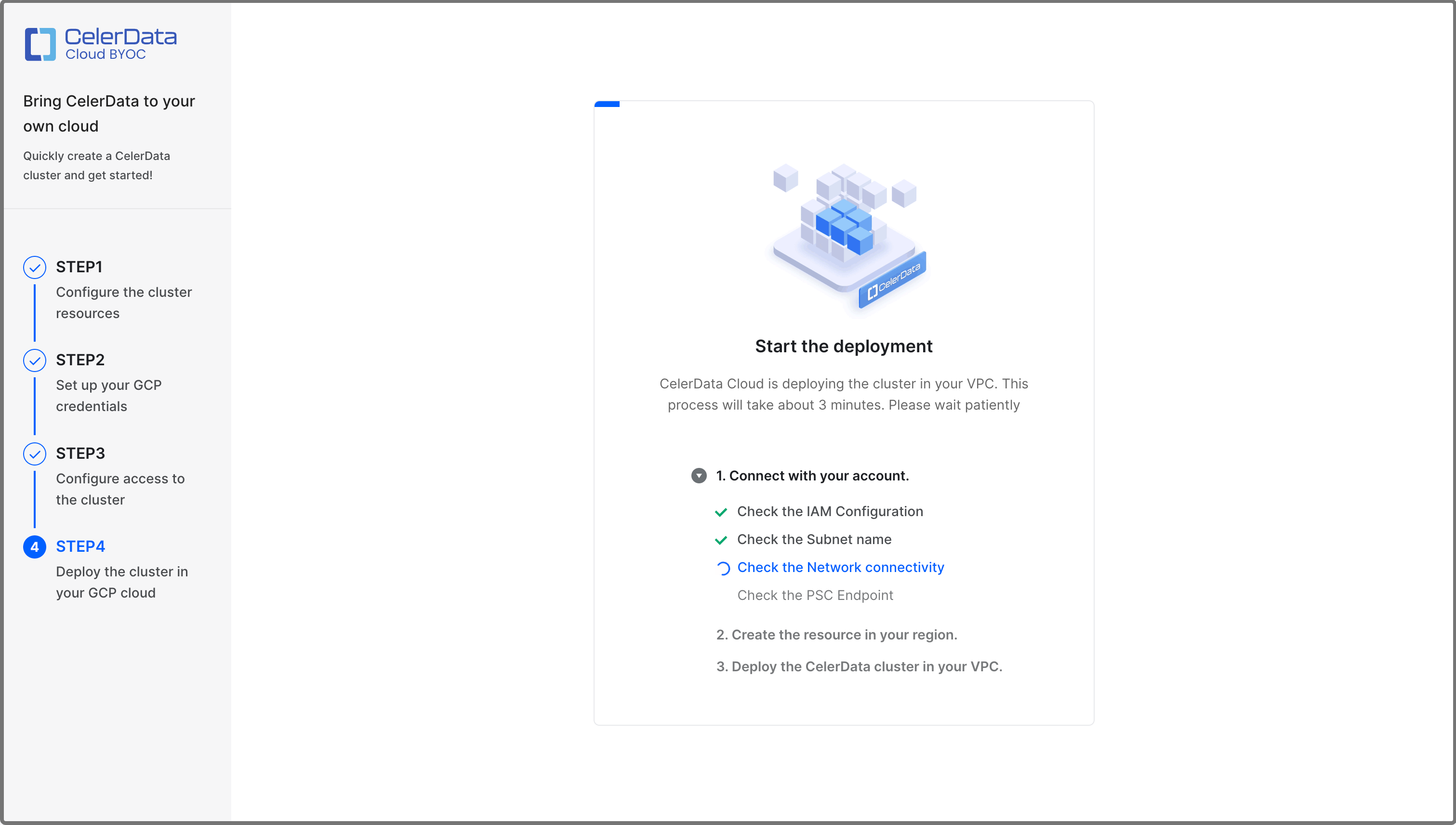
デプロイが完了すると、次の図に示すメッセージが表示されます。
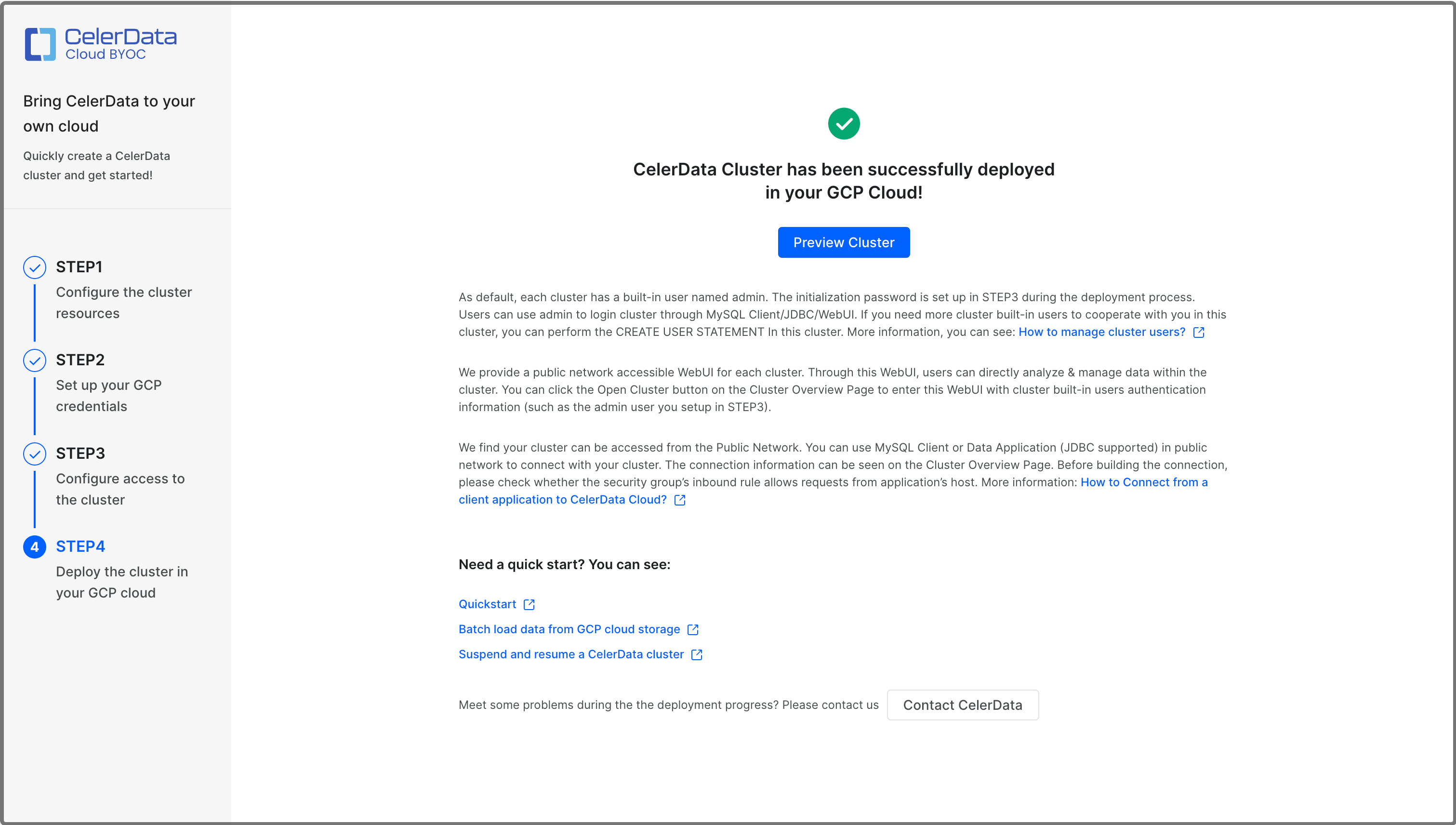
メッセージ内の Preview Cluster をクリックしてクラスターを表示できます。また、Clusters ページに戻ってクラスターを表示することもできます。クラスターは正常にデプロイされると Running 状態になります。
クラスターの資格情報とデプロイの詳細を取得する
将来の使用のために必要なクラスターの資格情報とデプロイの詳細を収集するために次の手順に従います:
-
クラスター用に作成したデプロイの詳細ページに戻ります。Output タブをクリックします。
-
Output タブで、次の情報を確認できます:
celerdata_cluster_preview_address: CelerData Cloud BYOC コンソールのクラスター詳細ページへのリンク。celerdata_cluster_storage_bucket: クラスターのクエリプロファイルを保存するために使用されるバケットの URI。celerdata_cluster_vm_service_account: クラスターにストレージバケットへのアクセス権を付与するために作成されたインスタンスサービスアカウントの名前。celerdata_cluster_network_tag: クラスターノード間および CelerData の VPC とクラスターの VPC 間の接続を TLS 経由で有効にするために使用されるファイアウォールルールのターゲットタグ。celerdata_cluster_network: クラスターがデプロイされている VPC ネットワークの URI。celerdata_cluster_subnetwork: クラスターがデプロイされているサブネットの URI。celerdata_cluster_initial_admin_password: クラスター内の admin アカウントの初期パスワード。
デフォルトのストレージボリュームを設定する - Elastic クラスターのみ
Classic クラスターをデプロイした場合、このステップをスキップしてください。
デフォルトでは、すべてのデータベースとテーブルはデフォルトのストレージボリュームに作成されます。
GCP 上の CelerData BYOC のプライベートプレビュー中に、デフォルトのストレージボリュームはクラスターを作成した後、データベースやテーブルを作成する前に手動で作成する必要があります。
XML API for interoperability は、GCS ストレージを S3 として操作するために使用されます。一般的に、S3 構成と GCS 構成の違いは次のとおりです:
- エンドポイント
https://storage.googleapis.comを使用する - 認証に HMAC キーとシークレットを使用する
interoperability XML API または HMAC キーに慣れていない場合は、このページの下部にリンクがあります。
GCS にストレージボリュームを作成する
次のものが必要です:
- クラスターが配置されている GCS リージョン(これは STEP1 で指定されました)
- STEP2 で指定された GCS バケット名
- バケット用の HMAC アクセスキーと HMAC シークレットキー
SQL クライアントを使用して admin ユーザーとしてクラスターに接続し、STORAGE VOLUME を作成します(バケットと認証の詳細を代入してください):
CREATE STORAGE VOLUME def_volume
TYPE = S3
LOCATIONS = ("s3://<GCS bucket name collected from the Outputs tab of the deployment details page in Google Cloud Console>")
PROPERTIES
(
"enabled" = "true",
"aws.s3.region" = "us-central1",
"aws.s3.endpoint" = "https://storage.googleapis.com",
"aws.s3.access_key" = "<HMAC access key>",
"aws.s3.secret_key" = "<HMAC secret key>"
);
新しいボリュームをデフォルトに設定します:
SET def_volume AS DEFAULT STORAGE VOLUME;
次に進むべきこと
いつでも、JDBC ドライバーや MySQL クライアントから、または CelerData Studio を使用してクラスターに接続できます。詳細については、Connect to a CelerData cluster を参照してください。
また、CelerData Cloud BYOC コンソールでクラスターを表示および管理し、ニーズに応じて調整することができます:
- View a CelerData cluster。
- Scale a CelerData cluster。
- Release a CelerData cluster。
- Suspend and resume a CelerData cluster。
- Open a CelerData cluster。