Data Cache
このトピックでは、Data Cache の動作原理と、外部データに対するクエリパフォーマンスを向上させるための Data Cache の有効化方法について説明します。v3.3.0 から、Data Cache はデフォルトで有効になっています。
データレイク分析において、StarRocks は OLAP エンジンとして外部ストレージシステム(HDFS や Amazon S3 など)に保存されたデータファイルをスキャンします。スキャンするファイル数が増えると、I/O オーバーヘッドが増加します。さらに、一部のアドホックなシナリオでは、同じデータへの頻繁なアクセスが I/O オーバーヘッドを倍増させます。
これらのシナリオでクエリパフォーマンスを最適化するために、StarRocks 2.5 は Data Cache 機能を提供します。この機能は、外部ストレージシステムのデータを事前定義されたポリシーに基づいて複数のブロックに分割し、StarRocks のバックエンド (BEs) にキャッシュします。これにより、各アクセス要求ごとに外部システムからデータを取得する必要がなくなり、ホットデータに対するクエリと分析が高速化されます。Data Cache は、外部カタログや外部テーブル(JDBC 互換データベース用の外部テーブルを除く)を使用して外部ストレージシステムからデータをクエリする場合にのみ機能します。StarRocks 内部テーブルをクエリする場合には機能しません。
動作原理
StarRocks は外部ストレージシステムのデータを同じサイズ(デフォルトで 1 MB)の複数のブロックに分割し、BEs にキャッシュします。ブロックはデータキャッシュの最小単位であり、設定可能です。
例えば、ブロックサイズを 1 MB に設定し、Amazon S3 から 128 MB の Parquet ファイルをクエリする場合、StarRocks はファイルを 128 ブロックに分割します。ブロックは [0, 1 MB), [1 MB, 2 MB), [2 MB, 3 MB) ... [127 MB, 128 MB) となります。StarRocks は各ブロックにグローバルに一意の ID を割り当て、これをキャッシュキーと呼びます。キャッシュキーは次の 3 つの部分で構成されます。
hash(filename) + fileModificationTime + blockId
次の表は各部分の説明を提供します。
| コンポーネント項目 | 説明 |
|---|---|
| filename | データファイルの名前。 |
| fileModificationTime | データファイルの最終変更時刻。 |
| blockId | データファイルを分割する際に StarRocks がブロックに割り当てる ID。同じデータファイル内では一意ですが、StarRocks クラスター内では一意ではありません。 |
クエリが [1 MB, 2 MB) ブロックにヒットした場合、StarRocks は次の操作を行います。
- ブロックがキャッシュに存在するかどうかを確認します。
- ブロックが存在する場合、StarRocks はキャッシュからブロックを読み込みます。ブロックが存在しない場合、StarRocks は Amazon S3 からブロックを読み込み、BE にキャッシュします。
Data Cache が有効になると、StarRocks は外部ストレージシステムから読み込んだデータブロックをキャッシュします。
ブロックのストレージメディア
StarRocks は BE マシンのメモリとディスクを使用してブロックをキャッシュします。メモリのみ、またはメモリとディスクの両方にキャッシュをサポートしています。
ディスクをストレージメディアとして使用する場合、キャッシュ速度はディスクの性能に直�接影響されます。したがって、データキャッシュには NVMe ディスクなどの高性能ディスクを使用することをお勧めします。高性能ディスクがない場合は、ディスクを追加してディスク I/O 圧力を軽減できます。
キャッシュ置換ポリシー
StarRocks はメモリとディスクの階層キャッシュをサポートしています。ビジネス要件に応じて、メモリキャッシュのみ、またはディスクキャッシュのみを構成することもできます。
メモリキャッシュとディスクキャッシュの両方が使用される場合:
- StarRocks は最初にメモリからデータを読み込みます。メモリにデータが見つからない場合、StarRocks はディスクからデータを読み込み、ディスクから読み込んだデータをメモリにロードしようとします。
- メモリから破棄されたデータはディスクに書き込まれます。ディスクから破棄されたデータは削除されます。
メモリキャッシュとディスクキャッシュは、それぞれのエビクションポリシーに基づいてキャッシュアイテムをエビクトします。StarRocks は現在、データをキャッシュおよびエビクトするために LRU(最も最近使用されていない)と SLRU(セグメント化された LRU)ポリシーをサポートしています。デフォルトのポリシーは SLRU です。
SLRU ポ�リシーが使用される場合、キャッシュスペースはエビクションセグメントとプロテクションセグメントに分割され、どちらも LRU ポリシーによって制御されます。データが初めてアクセスされると、エビクションセグメントに入ります。エビクションセグメントのデータは、再度アクセスされたときにのみプロテクションセグメントに入ります。プロテクションセグメントのデータがエビクトされると、再びエビクションセグメントに入ります。エビクションセグメントのデータがエビクトされると、キャッシュから削除されます。LRU と比較して、SLRU は突然のスパーストラフィックに対してよりよく耐え、プロテクションセグメントのデータが一度しかアクセスされていないデータによって直接エビクトされるのを防ぎます。
Data Cache の有効化
現在、Data Cache はデフォルトで有効になっており、システムは次の方法でデータをキャッシュします:
- システム変数
enable_scan_datacacheと BE パラメータdatacache_enableはデフォルトでtrueに設定されています。 - datacache ディレクトリが
storage_root_pathの下にキャッシュディレクトリとして作成されます。v3.4.0 以降、ディスクキャッシュパスを直接変更することはサポートされなくなりました。パスを設定したい場合は、シンボリックリンクを作成できます。 - メモリとディスクの制限が構成されていない場合、システムは次のルールに従って自動的にメモリとディスクの制限を設定します:
- システムは Data Cache の自動ディスクスペース調整を有効にします。全体のディスク使用率が約 80% になるように制限を設定し、その後のディスク使用に応じて動的に調整します。(この動作は BE パラメータ
datacache_disk_high_level、datacache_disk_safe_level、およびdatacache_disk_low_levelで変更できます。) - Data Cache のデフォルトのメモリ制限は
0です。(これは BE パラメータdatacache_mem_sizeで変更できます。)
- システムは Data Cache の自動ディスクスペース調整を有効にします。全体のディスク使用率が約 80% になるように制限を設定し、その後のディスク使用に応じて動的に調整します。(この動作は BE パラメータ
- システムはデフォルトで非同期キャッシュポピュレーションを採用し、データ読み取り操作への影響を最小限に抑えます。
- I/O アダプタ機能はデフォルトで有効になっています。ディスク I/O 負荷が高い場合、システムは自動的に一部の要求をリモートストレージにルーティングしてディスク圧力を軽減します。
Data Cache を無効化するには、次のステートメントを実行します:
SET GLOBAL enable_scan_datacache=false;
データキャッシュのポピュレーション
ポピュレーションルール
v3.3.2 以降、Data Cache のキャッシュヒット率を向上させるために、StarRocks は次のルールに従って Data Cache をポピュレートします:
SELECTでないステートメント、例えばANALYZE TABLEやINSERT INTO SELECTではキャッシュはポピュレートされません。- テーブルのすべてのパーティションをスキャンするクエリはキャッシュをポピュレートしません。ただし、テーブルにパーティションが 1 つしかない場合は、デフォルトでポピュレーションが行われます。
- テーブルのすべてのカラムをスキャンするクエリはキャッシュをポピュレートしません。ただし、テーブルにカラムが 1 つしかない場合は、デフォルトでポピュレーションが行われます。
- Hive、Paimon、Delta Lake、Hudi、Iceberg 以外のテーブルではキャッシュはポピュレートされません。
特��定のクエリに対するポピュレーションの動作を EXPLAIN VERBOSE コマンドで確認できます。
例:
mysql> explain verbose select col1 from hudi_table;
| 0:HudiScanNode |
| TABLE: hudi_table |
| partitions=3/3 |
| cardinality=9084 |
| avgRowSize=2.0 |
| dataCacheOptions={populate: false} |
| cardinality: 9084 |
+-----------------------------------------+
dataCacheOptions={populate: false} は、クエリがすべてのパーティションをスキャンするため、キャッシュがポピュレートされないことを示しています。
Data Cache のポピュレーションの動作をセッション変数 populate_datacache_mode を使用して微調整することもできます。
ポピュレーションモード
StarRocks は Data Cache を同期または非同期モードでポピュレートすることをサポートしています。
-
同期キャッシュポピュレーション
同期ポピュレーションモードでは、現在のクエリによって読み取られたすべてのリモートデータがローカルにキャッシュされます。同期ポピュレーションは効率的ですが、データ読み取り中に発生するため、初期クエリのパフォーマンスに影響を与える可能性があります。
-
非同期キャッシュポピュレーション
非同期ポピュレーションモードでは、システムは読み取りパ�フォーマンスへの影響を最小限に抑えるために、バックグラウンドでアクセスされたデータをキャッシュしようとします。非同期ポピュレーションは、初期読み取りに対するキャッシュポピュレーションのパフォーマンスへの影響を軽減できますが、ポピュレーションの効率は同期ポピュレーションよりも低くなります。通常、単一のクエリでは、アクセスされたすべてのデータをキャッシュすることは保証されません。すべてのアクセスされたデータをキャッシュするには、複数回の試行が必要になる場合があります。
v3.3.0 から、非同期キャッシュポピュレーションがデフォルトで有効になっています。セッション変数 enable_datacache_async_populate_mode を設定してポピュレーションモードを変更できます。
永続性
ディスクにキャッシュされたデータはデフォルトで永続化され、BE の再起動後に再利用できます。
クエリがデータキャッシュにヒットしたかどうかの確認
クエリプロファイルの次のメトリクスを分析することで、クエリがデータキャッシュにヒットしたかどうかを確認できます:
DataCacheReadBytes: StarRocks がメモリとディスクから直接読み取ったデータのサイズ。DataCacheWriteBytes: 外部ストレージシステムから StarRocks のメモリとディスクにロードされたデータのサイズ。BytesRead: 読み取られたデータの総量。外部ストレージシステムから、または StarRocks のメモリとディスクから読み取られたデータを含みます。
例 1: この例では、StarRocks は外部ストレージシステムから大量のデータ(7.65 GB)を読み取り、メモリとディスクからはわずかなデータ(518.73 MB)を読み取っています。これは、データキャッシュがほとんどヒットしなかったことを意味します。
- Table: lineorder
- DataCacheReadBytes: 518.73 MB
- __MAX_OF_DataCacheReadBytes: 4.73 MB
- __MIN_OF_DataCacheReadBytes: 16.00 KB
- DataCacheReadCounter: 684
- __MAX_OF_DataCacheReadCounter: 4
- __MIN_OF_DataCacheReadCounter: 0
- DataCacheReadTimer: 737.357us
- DataCacheWriteBytes: 7.65 GB
- __MAX_OF_DataCacheWriteBytes: 64.39 MB
- __MIN_OF_DataCacheWriteBytes: 0.00
- DataCacheWriteCounter: 7.887K (7887)
- __MAX_OF_DataCacheWriteCounter: 65
- __MIN_OF_DataCacheWriteCounter: 0
- DataCacheWriteTimer: 23.467ms
- __MAX_OF_DataCacheWriteTimer: 62.280ms
- __MIN_OF_DataCacheWriteTimer: 0ns
- BufferUnplugCount: 15
- __MAX_OF_BufferUnplugCount: 2
- __MIN_OF_BufferUnplugCount: 0
- BytesRead: 7.65 GB
- __MAX_OF_BytesRead: 64.39 MB
- __MIN_OF_BytesRead: 0.00
例 2: この例では、StarRocks はデータキャッシュから大量のデータ(46.08 GB)を読み取り、外部ストレージシステムからはデータを読み取っていません。これは、StarRocks がデータキャッシュからのみデータを読み取ったことを意味します。
Table: lineitem
- DataCacheReadBytes: 46.08 GB
- __MAX_OF_DataCacheReadBytes: 194.99 MB
- __MIN_OF_DataCacheReadBytes: 81.25 MB
- DataCacheReadCounter: 72.237K (72237)
- __MAX_OF_DataCacheReadCounter: 299
- __MIN_OF_DataCacheReadCounter: 118
- DataCacheReadTimer: 856.481ms
- __MAX_OF_DataCacheReadTimer: 1s547ms
- __MIN_OF_DataCacheReadTimer: 261.824ms
- DataCacheWriteBytes: 0.00
- DataCacheWriteCounter: 0
- DataCacheWriteTimer: 0ns
- BufferUnplugCount: 1.231K (1231)
- __MAX_OF_BufferUnplugCount: 81
- __MIN_OF_BufferUnplugCount: 35
- BytesRead: 46.08 GB
- __MAX_OF_BytesRead: 194.99 MB
- __MIN_OF_BytesRead: 81.25 MB
Footer Cache
データレイクに対するクエリ中にリモートストレージからファイルのデータをキャッシュすることに加えて、StarRocks はファイルから解析されたメタデータ(Footer)のキャッシュもサポートしています。Footer Cache は解析された Footer オブジェクトをメモリに直接キャッシュします。後続のクエリで同じファイルの Footer にアクセスする際、オブジェクトディスクリプタをキャッシュから直接取得でき、繰り返しの解析を回避できます。
現在、StarRocks は Parquet Footer オブジェクトのキャッシュをサポートしています。
次のシステム変数を設定することで Footer Cache を有効にできます:
SET GLOBAL enable_file_metacache=true;
注意
Footer Cache はデータキャッシュのメモリモジュールを使用してデータをキャッシュします。したがって、BE パラメータ
datacache_enableがtrueに設定されていることを確認し、datacache_mem_sizeに適切な値を設定する必要があります。
I/O アダプタ
キャッシュディスクの I/O 負荷が高いためにディスクアクセスの待ち時間が大幅に増加し、キャッシュシステムの最適化が逆効果になるのを防ぐために、Data Cache は I/O アダプタ機能を提供します。この機能は、ディスク負荷が高い場合に一部のキャッシュ要求をリモートストレージにルーティングし、ロ�ーカルキャッシュとリモートストレージの両方を利用して I/O スループットを向上させます。この機能はデフォルトで有効になっています。
次のシステム変数を設定することで I/O アダプタを有効にできます:
SET GLOBAL enable_datacache_io_adaptor=true;
動的スケーリング
Data Cache は、BE プロセスを再起動せずにキャッシュ容量を手動で調整することをサポートし、キャッシュ容量の自動調整もサポートしています。
手動スケーリング
BE の設定項目を動的に調整することで、Data Cache のメモリ制限やディスク容量を変更できます�。
例:
-- 特定の BE インスタンスの Data Cache メモリ制限を調整します。
UPDATE be_configs SET VALUE="10G" WHERE NAME="datacache_mem_size" and BE_ID=10005;
-- すべての BE インスタンスの Data Cache メモリ比率制限を調整します。
UPDATE be_configs SET VALUE="10%" WHERE NAME="datacache_mem_size";
-- すべての BE インスタンスの Data Cache ディスク制限を調整します。
UPDATE be_configs SET VALUE="2T" WHERE NAME="datacache_disk_size";
注意
- この方法で容量を調整する際は注意が必要です。WHERE 句を省略して、関連のない設定項目を変更しないようにしてください。
- この方法で行ったキャッシュ容量の調整は永続化されず、BE プロセスの再起動後に失われます。したがって、上記のようにパラメータを動的に調整した後、BE 設定ファイルを手動で変更して、次回の再起動後に変更が有効になるようにすることができます。
自動スケーリング
StarRocks は現在、ディスク容量の自動スケーリングをサポートしています。BE 設定でキャッシュディスクパスと容量制限を指定しない場合、自動スケーリングがデフォルトで有効になります。
次の設定項目を BE 設定ファイルに追加し、BE プロセスを再起動することで自動スケーリングを有効にすることもできます:
datacache_auto_adjust_enable=true
自動スケーリ��ングが有効になると:
- ディスク使用量が BE パラメータ
datacache_disk_high_level(デフォルト値は80、つまりディスクスペースの 80%)で指定されたしきい値を超えると、システムは自動的にキャッシュデータをエビクトしてディスクスペースを解放します。 - ディスク使用量が BE パラメータ
datacache_disk_low_level(デフォルト値は60、つまりディスクスペースの 60%)で指定されたしきい値を一貫して下回り、Data Cache によって使用されている現在のディスクスペースがいっぱいの場合、システムは自動的にキャッシュ容量を拡張します。 - キャッシュ容量を自動的にスケーリングする際、システムは BE パラメータ
datacache_disk_safe_level(デフォルト値は70、つまりディスクスペースの 70%)で指定されたレベルにキャッシュ容量を調整することを目指します。
キャッシュ共有
Data Cache は BE ノードのローカルディスクに依存するため、クラスタがスケーリングされる際、データルーティングの変更によりキャッシュミスが発生する可能性があり、エラスティックなスケーリング中にパフォーマンスが大幅に低下する可能性があります。
キャッシュ共有は、ネットワークを介したノード間のキャッシュデータへのアクセスをサポートするために使用されます。クラスタスケーリング中、ローカルキャッシュミスが発生すると�、システムはまず同じクラスタ内の他のノードからキャッシュデータのフェッチを試みます。すべてのキャッシュがミスした場合にのみ、システムはリモートストレージからデータを再取得します。この機能により、エラスティックなスケーリング中にキャッシュが無効になることによるパフォーマンスのジッタが効果的に低減され、安定したクエリパフォーマンスが保証されます。
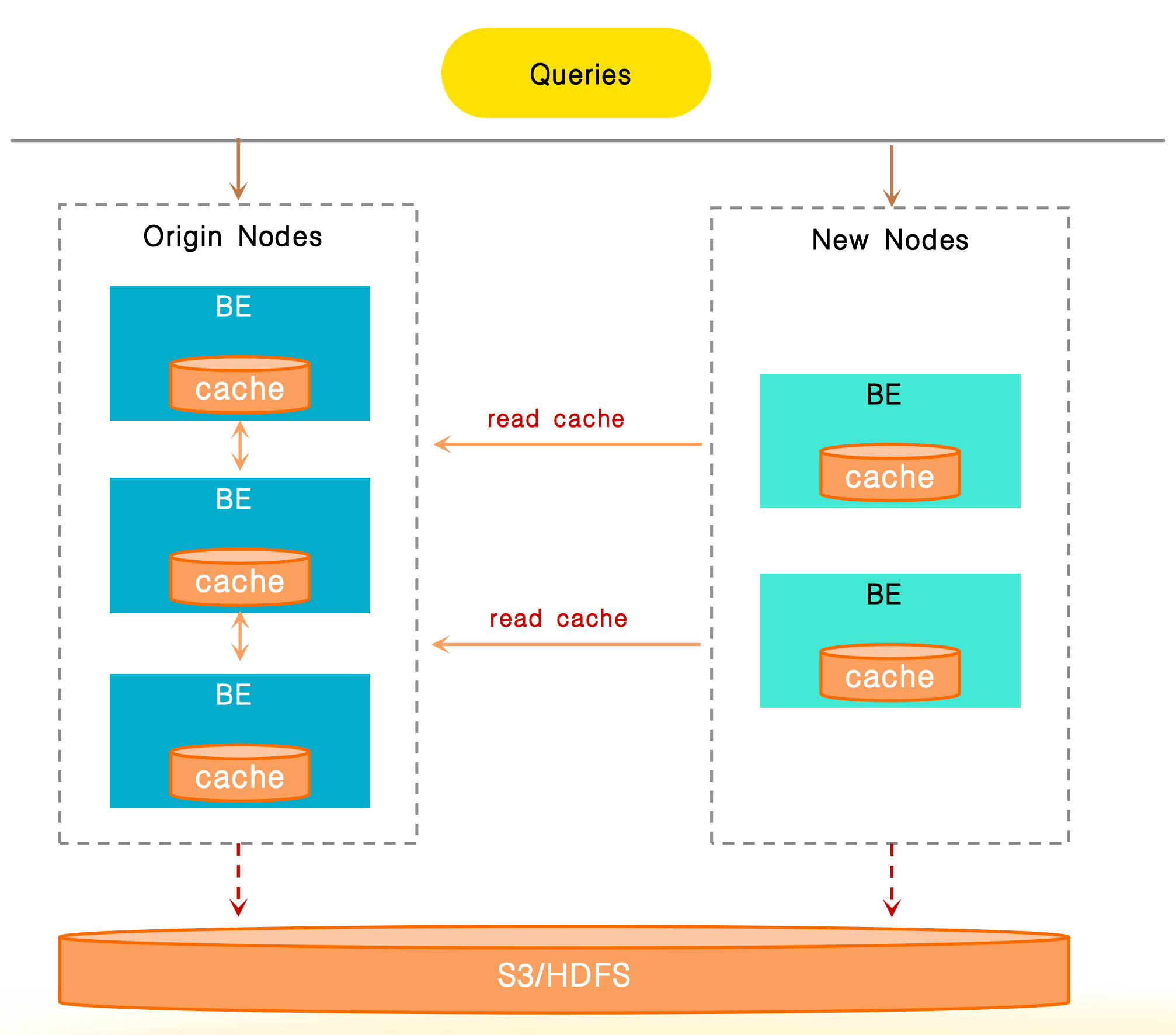
以下の2つの項目を設定することで、キャッシュ共有機能を有効にすることができます:
- FE 設定項目
enable_trace_historical_nodeをtrueに設定する。 - システム変数
enable_datacache_sharingをtrueに設定する。
さらに、Query Profile で以下のメトリクスをチェックすることで、キャッシュ共有を監視することができる:
DataCacheReadPeerCounter:他のキャッシュノードからの読み取り回数。DataCacheReadPeerBytes:他のキャッシュノードからの読み取りバイト数。DataCacheReadPeerTimer:他のキャッシュノードからキャッシュデータにアクセスするのに使用される時間。
設定と変数
次のシステム変数とパラメータを使用して Data Cache を構成できます。
システム変数
- populate_datacache_mode
- enable_datacache_io_adaptor
- enable_file_metacache
- enable_datacache_async_populate_mode
- enable_datacache_sharing
FE パラメータ
BE パラメータ
- datacache_enable
- datacache_mem_size
- datacache_disk_size
- datacache_auto_adjust_enable
- datacache_disk_high_level
- datacache_disk_safe_level
- datacache_disk_low_level
- datacache_disk_adjust_interval_seconds
- datacache_disk_idle_seconds_for_expansion
- datacache_min_disk_quota_for_adjustment
- datacache_eviction_policy
- datacache_inline_item_count_limit