Iceberg catalog
Iceberg catalog は、StarRocks が v2.4 以降でサポートする外部 catalog の一種です。Iceberg catalog を使用すると、以下のことが可能です。
- Iceberg に保存されたデータを直接クエリし、手動でテーブルを作成する必要がありません。
- Iceberg に保存されたデータを処理し、StarRocks にデータをロードするために INSERT INTO または非同期マテリアライズドビュー(v2.5 以降でサポート)を使用します。
- StarRocks 上で操作を行い、Iceberg データベースやテーブルを作成または削除したり、StarRocks テーブルから Parquet 形式の Iceberg テーブルにデータをシンクするために INSERT INTO を使用します(この機能は v3.1 以降でサポート)。
Iceberg クラスターで SQL ワークロードを成功させるためには、StarRocks クラスターが Iceberg クラスターのストレージシステムとメタストアにアクセスできる必要があります。StarRocks は以下のストレージシステムとメタストアをサポートしています。
-
分散ファイルシステム(HDFS)または AWS S3、Microsoft Azure Storage、Google GCS、または他の S3 互換ストレージシステム(例: MinIO)
-
メタストアとして Hive metastore、AWS Glue、または Tabular
- ストレージとして AWS S3 を選択した場合、メタストアとして HMS または AWS Glue を使用できます。他のストレージシステムを選択した場合、メタストアとして HMS のみを使用できます。
- メタストアとして Tabular を選択した場合、Iceberg REST catalog を使用する必要があります。
使用上の注意
StarRocks を使用して Iceberg からデータをクエリする際には、以下の点に注意してください。
| ファイル形式 | 圧縮形式 | Iceberg テーブルバージョン |
|---|---|---|
| Parquet | SNAPPY, LZ4, ZSTD, GZIP, NO_COMPRESSION |
|
| ORC | ZLIB, SNAPPY, LZO, LZ4, ZSTD, NO_COMPRESSION |
|
統合準備
Iceberg catalog を作成する前に、StarRocks クラスターが Iceberg クラスターのストレージシステムとメタストアと統合できることを確認してください。
ストレージ
ストレージタイプに一致するタブを選択してください。
- AWS S3
- HDFS
Iceberg クラスターがストレージとして AWS S3 を使用している場合、またはメタストアとして AWS Glue を使用している場合、適切な認証方法を選択し、StarRocks クラスターが関連する AWS クラウドリソースにアクセスできるように必要な準備を行ってください。
以下の認証方法が推奨されます。
- インスタンスプロファイル
- 想定ロール
- IAM ユーザー
上記の 3 つの認証方法の中で、インスタンスプロファイルが最も広く使用されています。
詳細については、 AWS IAM での認証の準備 を参照してください。
ストレージとして HDFS を選択した場合、StarRocks クラスターを次のように構成します。
-
(オプション)HDFS クラスターおよび Hive metastore にアクセスするために使用するユーザー名を設定します。デフォルトでは、StarRocks は HDFS クラスターおよび Hive metastore にアクセスするために FE および BE または CN プロセスのユーザー名を使用します。また、各 FE の fe/conf/hadoop_env.sh ファイルの先頭、および各 BE の be/conf/hadoop_env.sh ファイルまたは各 CN の cn/conf/hadoop_env.sh ファイルの先頭に
export HADOOP_USER_NAME="<user_name>"を追加してユーザー名を設定することもできます。これらのファイルでユーザー名を設定した後、各 FE および各 BE または CN を再起動して、パラメーター設定を有効にします。StarRocks クラスターごとに 1 つのユーザー名のみを設定できます。 -
Iceberg データをクエリする際、StarRocks クラスターの FEs および BEs または CNs は HDFS クライアントを使用して HDFS クラスターにアクセスします。ほとんどの場合、その目的を達成するために StarRocks クラスターを構成する必要はなく、StarRocks はデフォルトの構成を使用して HDFS クライアントを起動します。次の状況でのみ StarRocks クラスターを構成する必要があります。
- HDFS クラスターに高可用性 (HA) が有効になっている場合: HDFS クラスターの hdfs-site.xml ファイルを各 FE の $FE_HOME/conf パス、および各 BE の $BE_HOME/conf パスまたは各 CN の $CN_HOME/conf パスに追加します。
- HDFS クラスターに View File System (ViewFs) が有効になっている場合: HDFS クラスターの core-site.xml ファイルを各 FE の $FE_HOME/conf パス、および各 BE の $BE_HOME/conf パスまたは各 CN の $CN_HOME/conf パスに追加します。
クエリを送信した際に不明なホストを示すエラーが返された場合、HDFS クラスターのノードのホスト名と IP アドレスのマッピングを /etc/hosts パスに追加する必要があります。
Kerberos 認証
HDFS クラスターまたは Hive metastore に Kerberos 認証が有効になっている場合、StarRocks クラスターを次のように構成します。
- 各 FE および各 BE または CN で
kinit -kt keytab_path principalコマンドを実行して、Key Distribution Center (KDC) から Ticket Granting Ticket (TGT) を取得します。このコマンドを実行するには、HDFS クラスターおよび Hive metastore にアクセスする権限が必要です。このコマンドを使用して KDC にアクセスすることは時間に敏感であるため、cron を使用してこのコマンドを定期的に実行する必要があります。 - 各 FE の $FE_HOME/conf/fe.conf ファイル、および各 BE の $BE_HOME/conf/be.conf ファイルまたは各 CN の $CN_HOME/conf/cn.conf ファイルに
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"を追加します。この例では、/etc/krb5.confは krb5.conf ファイルの保存パスです。必要に応じてパスを変更できます。
Iceberg catalog の作成
構文
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "iceberg",
[SecurityParams],
MetastoreParams,
StorageCredentialParams,
MetadataRelatedParams
)
パラメーター
catalog_name
Iceberg catalog の名前です。命名規則は次のとおりです。
- 名前には文字、数字 (0-9)、およびアンダースコア (_) を含めることができます。文字で始める必要があります。
- 名前は大文字と小文字を区別し、長さは 1023 文字を超えることはできません。
comment
Iceberg catalog の説明です。このパラメーターはオプションです。
type
データソースのタイプです。値を iceberg に設定します。
SecurityParams
StarRock sがカタログへのデータアクセスを管理する方法に関するパラメータ。
catalog.access.control
データアクセス制御ポリシー。有効な値:
native(デフォルト): StarRocks 組み込みのデータアクセス制御システムを使用します。allowall: すべてのデータアクセスチェックをカタログ自体に委譲します。ranger: データアクセスチェックを Apache Ranger に委譲します。
MetastoreParams
StarRocks がデータソースのメタストアと統合する方法に関する一連のパラメーターです。メタストアタイプに一致するタブを選択してください。
- Hive metastore
- AWS Glue
- REST
- JDBC
Hive metastore
データソースのメタストアとして Hive metastore を選択した場合、MetastoreParams を次のように構成します。
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
Iceberg データをクエリする前に、Hive metastore ノードのホスト名と IP アドレスのマッピングを /etc/hosts パスに追加する必要があります。そうしないと、クエリを開始する際に StarRocks が Hive metastore にアクセスできない可能性があります。
次の表は、MetastoreParams で構成する必要があるパラメーターを説明しています。
-
iceberg.catalog.type- 必須: はい
- 説明: Iceberg クラスターで使用するメタストアのタイプ。値を
hiveに設定します。
-
hive.metastore.uris- 必須: はい
- 説明: Hive metastore の URI。形式:
thrift://<metastore_IP_address>:<metastore_port>。
Hive metastore に高可用性 (HA) が有効になっている場合、複数のメタストア URI を指定し、カンマ (,) で区切ることができます。例:"thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>"。
AWS Glue
データソースのメタストアとして AWS Glue を選択した場合(ストレージとして AWS S3 を選択した場合にのみサポート)、次のいずれかの操作を行います。
-
インスタンスプロファイルベースの認証方法を選択するには、
MetastoreParamsを次のように構成します。"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
想定ロールベースの認証方法を選択するには、
MetastoreParamsを次のように構成します。"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
IAM ユーザーベースの認証方法を選択するには、
MetastoreParamsを次のように構成します。"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
AWS Glue 用の MetastoreParams:
-
iceberg.catalog.type- 必須: はい
- 説明: Iceberg クラスターで使用するメタストアのタイプ。値を
glueに設定します。
-
aws.glue.use_instance_profile- 必須: はい
- 説明: インスタンスプロファイルベースの認証方法と想定ロールベースの認証方法を有効にするかどうかを指定します。 有効な値:
trueおよびfalse。デフォルト値:false。
-
aws.glue.iam_role_arn- 必須: いいえ
- 説明: AWS Glue Data Catalog に対する権限を持つ IAM ロールの ARN。想定ロールベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。
-
aws.glue.region- 必須: はい
- 説明: AWS Glue Data Catalog が存在するリージョン。例:
us-west-1。
-
aws.glue.access_key- 必須: いいえ
- 説明: AWS IAM ユーザーのアクセスキー。IAM ユーザーベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。
-
aws.glue.secret_key- 必須: いいえ
- 説明: AWS IAM ユーザーのシークレットキー。IAM ユーザーベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。
-
aws.glue.catalog_id- 必須: いいえ
- 説明: 使用する AWS Glue Data Catalog の ID。指定しない場合、現在の AWS アカウントのカタログが使用されます。別の AWS アカウントの Glue Data Catalog にアクセスする(クロスアカウントアクセス)必要がある場合は、このパラメータを指定する必要があります。
AWS Glue へのアクセス認証方法の選択方法および AWS IAM コンソールでのアクセス制御ポリシーの構成方法については、 AWS Glue へのアクセス認証パラメーター を参照してください。
REST
S3 テーブル用の Iceberg REST catalog の作成に関する詳細な手順については、 AWS S3 テーブル用 Iceberg REST Catalog の作成 を参照してください。
メタストアとして REST を使用する場合、メタストアのタイプを REST ("iceberg.catalog.type" = "rest") として指定する必要があります。MetastoreParams を次のように構成します。
"iceberg.catalog.type" = "rest",
"iceberg.catalog.uri" = "<rest_server_api_endpoint>",
"iceberg.catalog.security" = "oauth2",
"iceberg.catalog.oauth2.credential" = "<credential>",
"iceberg.catalog.warehouse" = "<identifier_or_path_to_warehouse>"
REST catalog 用の MetastoreParams:
-
iceberg.catalog.type- 必須: はい
- 説明: Iceberg クラスターで使用するメタストアのタイプ。値を
restに設定します。
-
iceberg.catalog.uri- 必須: はい
- 説明: REST サービスエンドポイントの URI。例:
https://api.tabular.io/ws。
-
iceberg.catalog.view-endpoints-supported- 必須: いいえ
- 説明: 以前のバージョンの REST サービスが
CatalogConfigでエンドポイントを返さない場合に、ビュー関連の操作をサポートするためにビューエンドポイントを使用するかどうか。このパラメータは初期のバージョンの REST サーバとの下位互換性のために使用される。デフォルト:false。
-
iceberg.catalog.security- 必須: いいえ
- 説明: 使用する認証プロトコルのタイプ。デフォルト:
NONE。有効な値:OAUTH2。OAUTH2認証プロトコルにはtokenまたはcredentialが必要です。
-
iceberg.catalog.oauth2.token- 必須: いいえ
- 説明: サーバーとのやり取りに使用されるベアラートークン。
OAUTH2認証プロトコルにはtokenまたはcredentialが必要です。例:AbCdEf123456。
-
iceberg.catalog.oauth2.credential- 必須: いいえ
- 説明: サーバーとの OAuth2 クライアント資格情報フローでトークンと交換するための資格情報。
OAUTH2認証プロトコルにはtokenまたはcredentialが必要です。例:AbCdEf123456。
-
iceberg.catalog.oauth2.scope- 必須: いいえ
- 説明: REST Catalog と通信する際に使用するスコープ。
credentialを使用する場合にのみ適用されます。
-
iceberg.catalog.oauth2.server-uri- 必須: いいえ
- 説明: OAuth2 サーバーからアクセストークンを取得するためのエンドポイント。
-
iceberg.catalog.vended-credentials-enabled- 必須: いいえ
- 説明: ファイルシステムアクセスのために REST バックエンドによって提供される資格情報を使用するかどうか。デフォルト:
true。
-
iceberg.catalog.warehouse- 必須: いいえ
- 説明: Iceberg catalog のウェアハウスの場所または識別子。例:
s3://my_bucket/warehouse_locationまたはsandbox。
-
iceberg.catalog.rest.nested-namespace-enabled- 必須: いいえ
- 説明: 入れ子になった Namespace の下にあるオブジェクトのクエリをサポートするかどうか。デフォルト:
false。
次の例は、Tabular をメタストアとして使用する Iceberg catalog tabular を作成します。
CREATE EXTERNAL CATALOG tabular
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"iceberg.catalog.uri" = "https://api.tabular.io/ws",
"iceberg.catalog.oauth2.credential" = "t-5Ii8e3FIbT9m0:aaaa-3bbbbbbbbbbbbbbbbbbb",
"iceberg.catalog.warehouse" = "sandbox"
);
次の例は、Polaris をメタストアとして使用する Iceberg catalog smith_polaris を作成します。
CREATE EXTERNAL CATALOG smith_polaris
PROPERTIES (
"iceberg.catalog.uri" = "http://xxx.xx.xx.xxx:8181/api/catalog",
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"iceberg.catalog.warehouse" = "starrocks_catalog",
"iceberg.catalog.security" = "oauth2",
"iceberg.catalog.oauth2.credential" = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"iceberg.catalog.oauth2.scope"='PRINCIPAL_ROLE:ALL'
);
# `ns1.ns2.tpch_namespace` はネストされた名前空間です
create table smith_polaris.`ns1.ns2.tpch_namespace`.tbl (c1 string);
mysql> select * from smith_polaris.`ns1.ns2.tpch_namespace`.tbl;
+------+
| c1 |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.34 sec)
次の例は、Cloudflare R2 Data Catalog をメタストアとして使用する Iceberg catalog r2 を作成します。
CREATE EXTERNAL CATALOG r2
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"iceberg.catalog.uri" = "<r2_catalog_uri>",
"iceberg.catalog.security" = "oauth2",
"iceberg.catalog.oauth2.token" = "<r2_api_token>",
"iceberg.catalog.warehouse" = "<r2_warehouse_name>"
);
SET CATALOG r2;
CREATE DATABASE testdb;
SHOW DATABASES FROM r2;
+--------------------+
| Database |
+--------------------+
| information_schema |
| testdb |
+--------------------+
2 rows in set (0.66 sec)
<r2_warehouse_name>,<r2_api_token>, および <r2_catalog_uri> の値は、 Cloudflare ダッシュボードの詳細 から取得します。
JDBC
データソースのメタストアとして JDBC を選択した場合、MetastoreParams を次のように構成します。
"iceberg.catalog.type" = "jdbc",
"iceberg.catalog.uri" = "<jdbc_uri>",
"iceberg.catalog.warehouse" = "<warehouse_location>"
次の表は、MetastoreParams で構成する必要があるパラメーターを説明しています。
-
iceberg.catalog.type- 必須:はい
- 説明:Icebergクラスタで使用するメタストアのタイプ。値を
jdbcに設定します。
-
iceberg.catalog.uri- 必須:はい
- 説明:データベースのURI。フォーマット:
jdbc:[mysql\|postgresql]://<DB_IP_address>:<DB_PORT>/<DB_NAME>。
-
iceberg.catalog.warehouse- 必須:はい
- 説明:Iceberg カタログの Warehouse の場所または識別子。例:
s3://my_bucket/warehouse_location。
説明: データ�ベースのユーザー名。
-
iceberg.catalog.jdbc.user- 必須:いいえ
- 説明:データベースのユーザー名。
-
iceberg.catalog.jdbc.password- 必須:いいえ
- 説明:データベースのパスワード。
-
iceberg.catalog.jdbc.init-catalog-tables- 必須:いいえ
- 説明:
iceberg.catalog.uriで指定されたデータベースにメタデータを格納するためのテーブルiceberg_namespace_propertiesおよびiceberg_tablesを作成するかどうか。デフォルト値はfalseです。iceberg.catalog.uriで指定されたデータベースにこれらの 2 つのテーブルがまだ作成されていない場合はtrueを指定してください。
次の例は、Iceberg catalog iceberg_jdbc を作成し、メタストアとして JDBC を使用します。
CREATE EXTERNAL CATALOG iceberg_jdbc
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "jdbc",
"iceberg.catalog.warehouse" = "s3://my_bucket/warehouse_location",
"iceberg.catalog.uri" = "jdbc:mysql://ip:port/db_name",
"iceberg.catalog.jdbc.user" = "username",
"iceberg.catalog.jdbc.password" = "password",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
MySQL やその他のカスタム JDBC ドライバを使用する場合、対応する JAR ファイルを fe/lib ディレクトリおよび be/lib/jni-packages ディレクトリに配置する必要があります。
StorageCredentialParams
StarRocks がストレージシステムと統合する方法に関する一連のパラメーターです。このパラメーターセットはオプションです。
次の点に注意してください。
-
ストレージとして HDFS を使用する場合、
StorageCredentialParamsを構成する必要はなく、このセクションをスキップできます。ストレージとして AWS S3、他の S3 互換ストレージシステム、Microsoft Azure Storage、または Google GCS を使用する場合、StorageCredentialParamsを構成する必要があります。 -
メタストアとして Tabular を使用する場合、
StorageCredentialParamsを構成する必要はなく、このセクションをスキップできます。メタストアとして HMS または AWS Glue を使用する場合、StorageCredentialParamsを構成する必要があります。
ストレージタイプに一致するタブを選択してください。
- AWS S3
- HDFS
- MinIO
- Microsoft Azure Blob Storage
- Google GCS
AWS S3
Iceberg クラスターのストレージとして AWS S3 を選択した場合、次のいずれかの操作を行います。
-
インスタンスプロファイルベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
想定ロールベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
IAM ユーザーベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
AWS S3 用の StorageCredentialParams:
aws.s3.use_instance_profile
必須: はい
説明: インスタンスプロファイルベースの認証方法と想定ロールベースの認証方法を有効にするかどうかを指定します。 有効な値: true および false。 デフォルト値: false。
aws.s3.iam_role_arn
必須: いいえ 説明: AWS S3 バケットに対する権限を持つ IAM ロールの ARN です。想定ロールベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメーターを指定する必要があります。
aws.s3.region
必須: はい
説明: AWS S3 バケットが存在するリージョンです。例: us-west-1。
aws.s3.access_key
必須: いいえ 説明: IAM ユーザーのアクセスキーです。IAM ユーザーベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメーターを指定する必要があります。
aws.s3.secret_key
必須: いいえ 説明: IAM ユーザーのシークレットキーです。IAM ユーザーベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメーターを指定する必要があります。
AWS S3 へのアクセス認証方法の選択方法および AWS IAM コンソールでのアクセス制御ポリシーの構成方法については、 AWS S3 へのアクセス認証パラメーター を参照してください。
HDFS ストレージを使用する場合、ストレージ資格情報をスキップします。
S3 互換ストレージシステム
Iceberg catalog は v2.5 以降で S3 互換ストレージシステムをサポートしています。
S3 互換ストレージシステム(例: MinIO)を Iceberg クラスターのストレージとして選択した場合、StorageCredentialParams を次のように構成して、統合を成功させます。
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
MinIO およびその他の S3 互換システム用の StorageCredentialParams:
aws.s3.enable_ssl
必須: はい
説明: SSL 接続を有効にするかどうかを指定します。
有効な値: true および false。 デフォルト値: true。
aws.s3.enable_path_style_access
必須: はい
説明: パススタイルアクセスを有効にするかどうかを指定します。
有効な値: true および false。 デフォルト値: false。 MinIO の場合、値を true に設定する必要があります。
パススタイル URL は次の形式を使用します: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>。 例: US West (Oregon) リージョンに DOC-EXAMPLE-BUCKET1 というバケットを作成し、そのバケット内の alice.jpg オブジェクトにアクセスしたい場合、次のパススタイル URL を使用できます: https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg。
aws.s3.endpoint
必須: はい 説明: AWS S3 の代わりに S3 互換ストレージシステムに接続するために使用されるエンドポイント。
aws.s3.access_key
必須: はい 説明: IAM ユーザーのアクセスキー。
aws.s3.secret_key
必須: はい 説明: IAM ユーザーのシークレットキー。
Microsoft Azure Storage
Iceberg catalog は v3.0 以降で Microsoft Azure Storage をサポートしています。
Azure Blob Storage
Iceberg クラスターのストレージとして Blob Storage を選択した場合、次のいずれかの操作を行います。
-
共有キー認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>" -
SAS トークン認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"
Microsoft Azure 用の StorageCredentialParams:
azure.blob.storage_account
必須: はい 説明: Blob Storage アカウントのユーザー名。
azure.blob.shared_key
必須: はい 説明: Blob Storage アカウントの共有キー。
azure.blob.account_name
必須: はい 説明: Blob Storage アカウントのユーザー名。
azure.blob.container
必須: はい 説明: データを保存する blob コンテナの名前。
azure.blob.sas_token
必須: はい 説明: Blob Storage アカウントにアクセスするために使用される SAS トークン。
Azure Data Lake Storage Gen1
Iceberg クラスターのストレージとして Data Lake Storage Gen1 を選択した場合、次のいずれかの操作を行います。
-
マネージドサービスアイデンティティ認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.adls1.use_managed_service_identity" = "true"
または:
-
サービスプリンシパル認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
Azure Data Lake Storage Gen2
Iceberg クラスターのストレージとして Data Lake Storage Gen2 を選択した場合、次のいずれかの操作を行います。
-
マネージドアイデンティティ認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"または:
-
共有キー認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"または:
-
サービスプリンシパル認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
Google GCS
Iceberg catalog は v3.0 以降で Google GCS をサポートしています。
Iceberg クラスターのストレージとして Google GCS を選択した場合、次のいずれかの操作を行います。
-
VM ベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"gcp.gcs.use_compute_engine_service_account" = "true" -
サービスアカウントベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>" -
インパーソネーションベースの認証方法を選択するには、
StorageCredentialParamsを次のように構成します。-
VM インスタンスをサービスアカウントにインパーソネートさせる場合:
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>" -
サービスアカウント(仮にメタサービスアカウントと呼ぶ)が別のサービスアカウント(仮にデータサービスアカウントと呼ぶ)にインパーソネートする場合:
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
-
Google GCS 用の StorageCredentialParams:
gcp.gcs.service_account_email
デフォルト値: "" 例: "user@hello.iam.gserviceaccount.com" 説明: サービスアカウントの作成時に生成された JSON ファイル内のメールアドレス。
gcp.gcs.service_account_private_key_id
デフォルト値: "" 例: "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" 説明: サービスアカウントの作成時に生成された JSON ファイル内のプライベートキー ID。
gcp.gcs.service_account_private_key
デフォルト値: ""
例: "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n"
説明: サービスアカウントの作成時に生成された JSON ファイル内のプライベートキー。
gcp.gcs.impersonation_service_account
デフォルト値: ""
例: "hello"
説明: インパーソネートしたいサービスアカウント。
MetadataRelatedParams
StarRocks における Iceberg メタデータのキャッシュに関するパラメーターのセットです。このパラメーターセットはオプションです。
v3.3.3 以降、StarRocks は 定期的なメタデータリフレッシュ戦略 をサポートしています。ほとんどの場合、以下のパラメーターを無視し、そのポリシーパラメーターを調整する必要はありません。これらのパラメーターのデフォルト値は、すぐに使用できるパフォーマンスを提供します。システム変数 plan_mode を使用して Iceberg メタデータパースモードを調整できます。
| パラメーター | デフォルト | 説明 |
|---|---|---|
| enable_iceberg_metadata_cache | true | Iceberg 関連のメタデータ(Table Cache、Partition Name Cache、Manifest 内の Data File Cache および Delete Data File Cache を含む)をキャッシュするかどうか。 |
| iceberg_manifest_cache_with_column_statistics | false | 列の統計をキャッシュするかどうか。 |
| refresh_iceberg_manifest_min_length | 2 * 1024 * 1024 | Data File Cache のリフレッシュをトリガーする最小の Manifest ファイル長。 |
| iceberg_data_file_cache_memory_usage_ratio | 0.1 | Data File Manifest キャッシュの最大メモリ使用率。v3.5.6 以降でサポートされています。 |
| iceberg_delete_file_cache_memory_usage_ratio | 0.1 | Delete File Manifest キャッシュの最大メモリ使用率。v3.5.6 以降でサポートされています。 |
| iceberg_table_cache_refresh_interval_sec | 60 | Iceberg テーブルキャッシュの非同期更新がトリガーされる間隔(秒単位)。v3.5.7 以降でサポートされています。 |
v3.4 以降、StarRocks は、以下のパラメーターを設定することで、Iceberg メタデータを読み取ることで Iceberg テーブルの統計情報を取得できます。これにより、Iceberg テーブルの統計情報の収集を積極的にトリガーする必要はありません。
| パラメーター | デフォルト | 説明 |
|---|---|---|
| enable_get_stats_from_external_metadata | false | Iceberg メタデータ�から統計情報を取得するかどうか。この項目を true に設定すると、セッション変数 enable_get_stats_from_external_metadata を通じて、収集する統計情報の種類をさらに制御できます。 |
例
以下の例は、使用するメタストアのタイプに応じて、Iceberg クラスターからデータをクエリするための Iceberg catalog iceberg_catalog_hms または iceberg_catalog_glue を作成します。ストレージタイプに一致するタブを選択してください。
- AWS S3
- HDFS
- MinIO
- Microsoft Azure Blob Storage
- Google GCS
AWS S3
インスタンスプロファイルベースの資格情報を選択した場合
-
Iceberg クラスターで Hive metastore を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Iceberg クラスターで AWS Glue を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_glue
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
想定ロールベースの資格情報を選択した場合
-
Iceberg クラスターで Hive metastore を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Iceberg クラスターで AWS Glue を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_glue
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
IAM ユーザーベースの資格情報を選択した場合
-
Iceberg クラスターで Hive metastore を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Iceberg クラスターで AWS Glue を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_glue
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
HDFS
ストレージとして HDFS を使用する場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
S3 互換ストレージシステム
MinIO を例として使用します。次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
共有キー認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
SAS トークン認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
マネージドサービスアイデンティティ認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
サービスプリンシパル認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
マネージドアイデンティティ認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
共有キー認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
サービスプリンシパル認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
VM ベースの認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
サービスアカウントベースの認証方法を選択した場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
インパーソネーションベースの認証方法を選択した場合:
-
VM インスタンスをサービスアカウントにインパーソネートさせる場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
サービスアカウントが別のサービスアカウントにインパーソネートする場合、次のようなコマンドを実行します。
CREATE EXTERNAL CATALOG iceberg_catalog_hms
PROPERTIES
(
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
カタログの使用
Iceberg catalog の表示
現在の StarRocks クラスター内のすべての catalog をクエリするには、 SHOW CATALOGS を使用できます。
SHOW CATALOGS;
外部 catalog の作成ステートメントをクエリするには、 SHOW CREATE CATALOG を使用することもできます。次の例は、Iceberg catalog iceberg_catalog_glue の作成ステートメントをクエリします。
SHOW CREATE CATALOG iceberg_catalog_glue;
Iceberg Catalog とそのデータベースへの切り替え
Iceberg catalog とそのデータベースに切り替える�には、次のいずれかの方法を使用できます。
-
現在のセッションで Iceberg catalog を指定するには SET CATALOG を使用し、次にアクティブなデータベースを指定するには USE を使用します。
-- 現在のセッションで指定された catalog に切り替えます。
SET CATALOG <catalog_name>
-- 現在のセッションでアクティブなデータベースを指定します。
USE <db_name> -
Iceberg catalog とそのデータベースに直接切り替えるには USE を使用します。
USE <catalog_name>.<db_name>
Iceberg catalog の削除
外部 catalog を削除するには、 DROP CATALOG を使用できます。
次の例は、Iceberg catalog iceberg_catalog_glue を削除します。
DROP Catalog iceberg_catalog_glue;
Iceberg テーブルのスキーマを表示
Iceberg テーブルのスキーマを表示するには、次のいずれかの構文を使用できます。
-
スキーマを表示
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
CREATE ステートメントからスキーマと場所を表示
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
Iceberg テーブルをクエリ
-
Iceberg クラスター内のデータベースを表示するには、 SHOW DATABASES を使用します。
SHOW DATABASES FROM <catalog_name> -
指定されたデータベース内の宛先テーブルをクエリするには、 SELECT を使用します。
SELECT count(*) FROM <table_name> LIMIT 10
Iceberg データベースの作成
StarRocks の内部 catalog と同様に、Iceberg catalog に対して CREATE DATABASE 権限を持っている場合、 CREATE DATABASE ステートメントを使用して、その Iceberg catalog にデータベースを作成できます。この機能は v3.1 以降でサポートされています。
Iceberg catalog に切り替え、次にその catalog に Iceberg データベースを作成するために次のステートメントを使用します。
CREATE DATABASE <database_name>
[PROPERTIES ("location" = "<prefix>://<path_to_database>/<database_name.db>/")]
location パラメーターを使用して、データベースを作成するファイルパスを指定できます。HDFS とクラウドストレージの両方がサポートされています。location パラメーターを指定しない場合、StarRocks は Iceberg catalog のデフォルトのファイルパスにデータベースを作成します。
prefix は使用するストレージシステムに基づいて異なります。
HDFS
Prefix 値: hdfs
Google GCS
Prefix 値: gs
Azure Blob Storage
Prefix 値:
- ストレージアカウントが HTTP 経由でのアクセスを許可する場合、
prefixはwasbです。 - ストレージアカウントが HTTPS 経由でのアクセスを許可する場合、
prefixはwasbsです。
Azure Data Lake Storage Gen1
Prefix 値: adl
Azure Data Lake Storage Gen2
Prefix 値:
- ストレージアカウントが HTTP 経由でのアクセスを許可する場合、
prefixはabfsです。 - ストレージアカウントが HTTPS 経由でのアクセスを許可する場合、
prefixはabfssです。
AWS S3 または他の S3 互換ストレージ(例: MinIO)
Prefix 値: s3
Iceberg データベースの削除
StarRocks の内部データベースと同様に、Iceberg データベースに対して DROP 権限を持っている場合、 DROP DATABASE ステートメントを使用して、その Iceberg データベースを削除できます。この機能は v3.1 以降でサポートされています。空のデータベースのみを削除できます。
Iceberg データベースを削除すると、HDFS クラスターまたはクラウドストレージ上のデータベースのファイルパスはデータベースと共に削除されません。
Iceberg catalog に切り替え、次にその catalog に Iceberg データベースを削除するために次のステートメントを使用します。
DROP DATABASE <database_name>;
Iceberg テーブルの作成
StarRocks の内部データベースと同様に、Iceberg データベースに対して CREATE TABLE 権限を持っている場合、 CREATE TABLE または [CREATE TABLE AS SELECT ../../sql-reference/sql-statements/table_bucket_part_index/CREATE_TABLE_AS_SELECT.mdELECT.md) ステートメントを使用して、その Iceberg データベースにテーブルを作成できます。この機能は v3.1 以降でサポートされています。
Iceberg catalog とそのデータベースに切り替え、次にそのデータベースに Iceberg テーブルを作成するために次の構文を使用します。
構文
CREATE TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...
partition_column_definition1,partition_column_definition2...])
[partition_desc]
[PROPERTIES ("key" = "value", ...)]
[AS SELECT query]
パラメーター
column_definition
column_definition の構文は次のとおりです。
col_name col_type [COMMENT 'comment']
すべての非パーティション列はデフォルト値として NULL を使用する必要があります。つまり、テーブル作成ステートメントで各非パーティション列に対して DEFAULT "NULL" を指定する必要があります。さらに、パーティション列は非パーティション列の後に定義され、デフォルト値として NULL を使用することはできません。
partition_desc
partition_desc の構文は次のとおりです。
PARTITION BY (par_col1[, par_col2...])
現在、StarRocks は identity transforms のみをサポートしており、これは StarRocks が各一意のパーティション値に対してパーティションを作成することを意味します。
パーティション列は非パーティション列の後に定義される必要があります。パーティション列は FLOAT、DOUBLE、DECIMAL、および DATETIME を除くすべてのデータ型をサポートし、デフォルト値として NULL を使用することはできません。
PROPERTIES
PROPERTIES で "key" = "value" 形式でテーブル属性を指定できます。 Iceberg テーブル属性 を参照してください。
次の表は、いくつかの主要なプロパティを説明しています。
location
説明: Iceberg テーブルを作成するファイルパス。メタストアとして HMS を使用する場合、location パラメーターを指定する必要はありません。StarRocks は現在の Iceberg catalog のデフォルトのファイルパスにテーブルを作成します。メタストアとして AWS Glue を使用する場合:
- テーブルを作成するデータベースに対して
locationパラメーターを指定している場合、テーブルに対してlocationパラメーターを指定する必要はありません。そのため、テーブルは所属するデータベースのファイルパスにデフォルト設定されます。 - テーブルを作成するデータベースに対して
locationを指定していない場合、テーブルに対してlocationパラメーターを指定する必要があります。
file_format
説明: Iceberg テーブルのファイル形式。Parquet 形式のみがサポートされています。デフォルト値: parquet。
compression_codec
説明: Iceberg テーブルに使用される圧縮アルゴリズム。サポートされている圧縮アルゴリズムは SNAPPY、GZIP、ZSTD、および LZ4 です。デフォルト値: gzip。このプロパティは v3.2.3 で非推奨となり、それ以降のバージョンでは Iceberg テーブルにデータをシンクするために使用される圧縮アルゴリズムはセッション変数 connector_sink_compression_codec によって一元的に制御されます。
例
-
unpartition_tbl��という名前の非パーティションテーブルを作成します。このテーブルはidとscoreの 2 つの列で構成されています。CREATE TABLE unpartition_tbl
(
id int,
score double
); -
partition_tbl_1という名前のパーティションテーブルを作成します。このテーブルはaction、id、およびdtの 3 つの列で構成されており、そのうちidとdtはパーティション列として定義されています。CREATE TABLE partition_tbl_1
(
action varchar(20),
id int,
dt date
)
PARTITION BY (id,dt); -
既存のテーブル
partition_tbl_1をクエリし、そのクエリ結果に基づいてpartition_tbl_2という名前のパーティションテーブルを作成します。partition_tbl_2では、idとdtがパーティション列として定義されています。CREATE TABLE partition_tbl_2
PARTITION BY (id, dt)
AS SELECT * from employee;
Iceberg テーブルへのデータシンク
StarRocks の内部テーブルと同様に、Iceberg テーブルに対して INSERT 権限を持っている場合、 INSERT ステートメントを使用して、StarRocks テーブルのデータをその Iceberg テーブルにシンクできます(現在、Parquet 形式の Iceberg テーブルのみがサポートされています)。この機能は v3.1 以降でサポートされています。
Iceberg catalog とそのデータベースに切り替え、次にそのデータベース内の Parquet 形式の Iceberg テーブルに StarRocks テーブルのデータをシンクするために次の構文を使用します。
構文
INSERT {INTO | OVERWRITE} <table_name>
[ (column_name [, ...]) ]
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
-- 指定されたパーティションにデータをシンクする場合、次の構文を使用します。
INSERT {INTO | OVERWRITE} <table_name>
PARTITION (par_col1=<value> [, par_col2=<value>...])
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
パーティション列は NULL 値を許可しません。したがって、Iceberg テーブルのパーティション列に空の値がロードされないようにする必要があります。
パラメーター
INTO
StarRocks テーブルのデータを Iceberg テーブルに追加します。
OVERWRITE
StarRocks テーブルのデータで Iceberg テーブルの既存のデータを上書きします。
column_name
データをロードしたい宛先列の名前。1 つ以上の列を指定できます。複数の列を指定する場合、カンマ (,) で区切ります。Iceberg テーブルに実際に存在する列のみを指定できます。また、指定した宛先列には Iceberg テーブルのパーティション列を含める必要があります。指定した宛先列は、StarRocks テーブルの列と順番に 1 対 1 でマッピングされます。宛先列名が何であっても関係ありません。宛先列が指定されていない場合、データは Iceberg テーブルのすべての列にロードされます。StarRocks テーブルの非パーティション列が Iceberg テーブルの任意の列にマッピングできない場合、StarRocks は Iceberg テーブル列にデフォルト値 NULL を書き込みます。INSERT ステートメントに含まれるクエリステートメントの戻り列タイプが宛先列のデータタイプと異なる場合、StarRocks は不一致の列に対して暗黙の変換を行います。変換が失敗した場合、構文解析エラーが返されます。
expression
宛先列に値を割り当てる式。
DEFAULT
宛先列にデフォルト値を割り当てます。
query
Iceberg テーブルにロードされるクエリステートメントの結果。StarRocks がサポートする任意の SQL ステートメントである可能性があります。
PARTITION
データをロードしたいパーティション。Iceberg テーブルのすべてのパーティション列をこのプロパティで指定する必要があります。このプロパティで指定するパーティション列は、テーブル作成ステートメントで定義したパーティション列と異なる�順序であってもかまいません。このプロパティを指定する場合、column_name プロパティを指定することはできません。
例
-
partition_tbl_1テーブルに 3 行のデータを挿入します。INSERT INTO partition_tbl_1
VALUES
("buy", 1, "2023-09-01"),
("sell", 2, "2023-09-02"),
("buy", 3, "2023-09-03"); -
簡単な計算を含む SELECT クエリの結果を
partition_tbl_1テーブルに挿入します。INSERT INTO partition_tbl_1 (id, action, dt) SELECT 1+1, 'buy', '2023-09-03'; -
partition_tbl_1テーブルからデータを読み取る SELECT クエリの結果を同じテーブルに挿入します。INSERT INTO partition_tbl_1 SELECT 'buy', 1, date_add(dt, INTERVAL 2 DAY)
FROM partition_tbl_1
WHERE id=1; -
partition_tbl_2テーブルのdt='2023-09-01'およびid=1の条件を満たすパーティションに SELECT クエリの結果を挿入します。INSERT INTO partition_tbl_2 SELECT 'order', 1, '2023-09-01';または
INSERT INTO partition_tbl_2 partition(dt='2023-09-01',id=1) SELECT 'order'; -
partition_tbl_1テーブルのdt='2023-09-01'およびid=1の条件を満たすパーティション内のすべてのaction列の値をcloseで上書きします。INSERT OVERWRITE partition_tbl_1 SELECT 'close', 1, '2023-09-01';または
INSERT OVERWRITE partition_tbl_1 partition(dt='2023-09-01',id=1) SELECT 'close';
Iceberg テーブルの削除
StarRocks の内部テーブルと同様に、Iceberg テーブルに対して DROP 権限を持っている場合、 DROP TABLE ステートメントを使用して、その Iceberg テーブルを削除できます。この機能は v3.1 以降でサポートされています。
Iceberg テーブルを削除すると、HDFS クラスターまたはクラウドストレージ上のテーブルのファイルパスとデータはテー�ブルと共に削除されません。
Iceberg テーブルを強制的に削除する場合(つまり、DROP TABLE ステートメントで FORCE キーワードを指定した場合)、HDFS クラスターまたはクラウドストレージ上のテーブルのデータはテーブルと共に削除されますが、テーブルのファイルパスは保持されます。
Iceberg catalog とそのデータベースに切り替え、次にそのデータベース内の Iceberg テーブルを削除するために次のステートメントを使用します。
DROP TABLE <table_name> [FORCE];
Iceberg ビューの作成
StarRocks で Iceberg ビューを定義したり 、 既存の Iceberg ビューに StarRocks 方言を追加することがで き ます。このような Iceberg ビューに対するクエリは、これらのビューの StarRocks 方言の解析をサポートします。この機能は v3.5 以降でサポートされています。
CREATE VIEW [IF NOT EXISTS]
[<catalog>.<database>.]<view_name>
(
<column_name>[ COMMENT 'column comment']
[, <column_name>[ COMMENT 'column comment'], ...]
)
[COMMENT 'view comment']
AS <query_statement>
例
Iceberg テーブル iceberg_table に基づいて Iceberg ビュー iceberg_view1 を作成する。
CREATE VIEW IF NOT EXISTS iceberg.iceberg_db.iceberg_view1 AS
SELECT k1, k2 FROM iceberg.iceberg_db.iceberg_table;
既存の Iceberg ビューに StarRocks 方言を追加または変更する
Iceberg ビューが Apache Spark などの他のシステムから作成されており、StarRocks からこれらのビューにクエリを実行したい場合、これらのビューに StarRocks 方��言を追加できます。この機能は v3.5 以降でサポートされています。
- ビューの両方の方言の本質的な意味が同一であることを保証する必要があります。StarRocks や他のシステムでは、異なる定義間の一貫性は保証されません。
- 各 Iceberg ビューに対して定義できる StarRocks 方言は 1 つだけです。方言の定義は MODIFY 句を使用して変更できます。
ALTER VIEW
[<catalog>.<database>.]<view_name>
(
<column_name>
[, <column_name>]
)
{ ADD | MODIFY } DIALECT
<query_statement>
例
- 既存の Iceberg ビュー
iceberg_view2に StarRocks 方言を追加する。
ALTER VIEW iceberg.iceberg_db.iceberg_view2 ADD DIALECT SELECT k1, k2 FROM iceberg.iceberg_db.iceberg_table;
- 既存の Iceberg ビュー
iceberg_view2の StarRocks 方言を変更する。
ALTER VIEW iceberg.iceberg_db.iceberg_view2 MODIFY DIALECT SELECT k1, k2, k3 FROM iceberg.iceberg_db.iceberg_table;
メタデータキャッシュの構成
Iceberg クラスターのメタデータファイルは、AWS S3 や HDFS などのリモートストレージに保存されている場合があります。デフォルトでは、StarRocks はメモリ内に Iceberg メタデータをキャッシュします。クエリを高速化するために、StarRocks はメモリとディスクの両方にメタデータをキャッシュできる 2 レベルのメタデータキャッシングメカニズムを採用しています。初期クエリごとに、StarRocks はその計算結果をキャッシュします。以前のクエリと意味的に等価な後続のクエリが発行された場合、StarRocks は最初にそのキャッシュから要求されたメタデータを取得しようとし、キャッシュでメタデータがヒットしない場合にのみリモートストレージからメタデータを取得します。
StarRocks は、データをキャッシュおよび削除するために最も最近使用されたものを優先する(LRU)アルゴリズムを使用します。基本的なルールは次のとおりです。
- StarRocks は最初にメモリから要求されたメタデータを取得しようとします。メモリでメタデータがヒットしない場合、StarRocks はディスクからメタデータを取得しようとします。StarRocks がディスクから取得したメタデータはメモリにロードされます。ディスクでもメタデータがヒットしない場合、StarRocks はリモートストレージからメタデータを取得し、取得したメタデータをメモリにキャッシュします。
- StarRocks はメモリから削除されたメタデータをディスクに書き込みますが、ディスクから削除されたメタデータは直接破棄します。
v3.3.3 以降、StarRocks は 定期的なメタデータリフレッシュ戦略 をサポートしています。システム変数 plan_mode を使用して Iceberg メタデータキャッシュプランを調整できます。
Iceberg メタデータキャッシュに関する FE の設定
enable_iceberg_metadata_disk_cache
- 単位: N/A
- デフォルト値:
false - 説明: ディスクキャッシュを有効にするかどうかを指定します。
iceberg_metadata_cache_disk_path
- 単位: N/A
- デフォルト値:
StarRocksFE.STARROCKS_HOME_DIR + "/caches/iceberg" - 説明: ディスク上のキャッシュされたメタデータファイルの保存パス。
iceberg_metadata_disk_cache_capacity
- 単位: バイト
- デフォルト値:
2147483648、2 GB に相当 - 説明: ディスク上で許可されるキャッシュされたメタデータの最大サイズ。
iceberg_metadata_memory_cache_capacity
- 単位: バイト
- デフォルト値:
536870912、512 MB に相当 - 説明: メモリ内で許可されるキャッシュされたメタデータの最大サイズ。
iceberg_metadata_memory_cache_expiration_seconds�
- 単位: 秒
- デフォルト値:
86500 - 説明: メモリ内のキャッシュエントリが最後にアクセスされてから期限切れになるまでの時間。
iceberg_metadata_disk_cache_expiration_seconds
- 単位: 秒
- デフォルト値:
604800、1 週間に相当 - 説明: ディスク上のキャッシュエントリが最後にアクセスされてから期限切れになるまでの時間。
iceberg_metadata_cache_max_entry_size
- 単位: バイト
- デフォルト値:
8388608、8 MB に相当 - 説明: キャッシュできるファイルの最大サイズ。このパラメーターの値を超えるサイズのファイルはキャッシュできません。クエリがこれらのファイルを要求する場合、StarRocks はリモートストレージからそれらを取得します。
enable_background_refresh_connector_metadata
- 単位: -
- デフォルト値: true
- 説明: 定期的な Iceberg メタデータキャッシュのリフレッシュを有効にするかどうか。これが有効になると、StarRocks は Iceberg クラスターのメタストア(Hive Metastore または AWS Glue)をポーリングし、頻繁にアクセスされる Iceberg catalog のキャッシュされたメタデータをリフレッシュしてデータの変更を認識します。
trueは Iceberg メタデータキャッシュのリフレッシュを有効にし、falseはそれを無効にします。
background_refresh_metadata_interval_millis
- 単位: ミリ秒
- デフォルト値: 600000
- 説明: 2 つの連続した Iceberg メタデータキャッシュリフレッシュの間隔。- 単位: ミリ秒。
background_refresh_metadata_time_secs_since_last_access_sec
- 単位: 秒
- デフォルト値: 86400
- 説明: Iceberg メタデータキャッシュリフレッシュタスクの有効期限�。アクセスされた Iceberg catalog に対して、指定された時間を超えてアクセスされていない場合、StarRocks はそのキャッシュされたメタデータのリフレッシュを停止します。アクセスされていない Iceberg catalog に対して、StarRocks はそのキャッシュされたメタデータをリフレッシュしません。
付録 A: 定期的なメタデータリフレッシュ戦略
Appendix A: Periodic Metadata Refresh Strategy
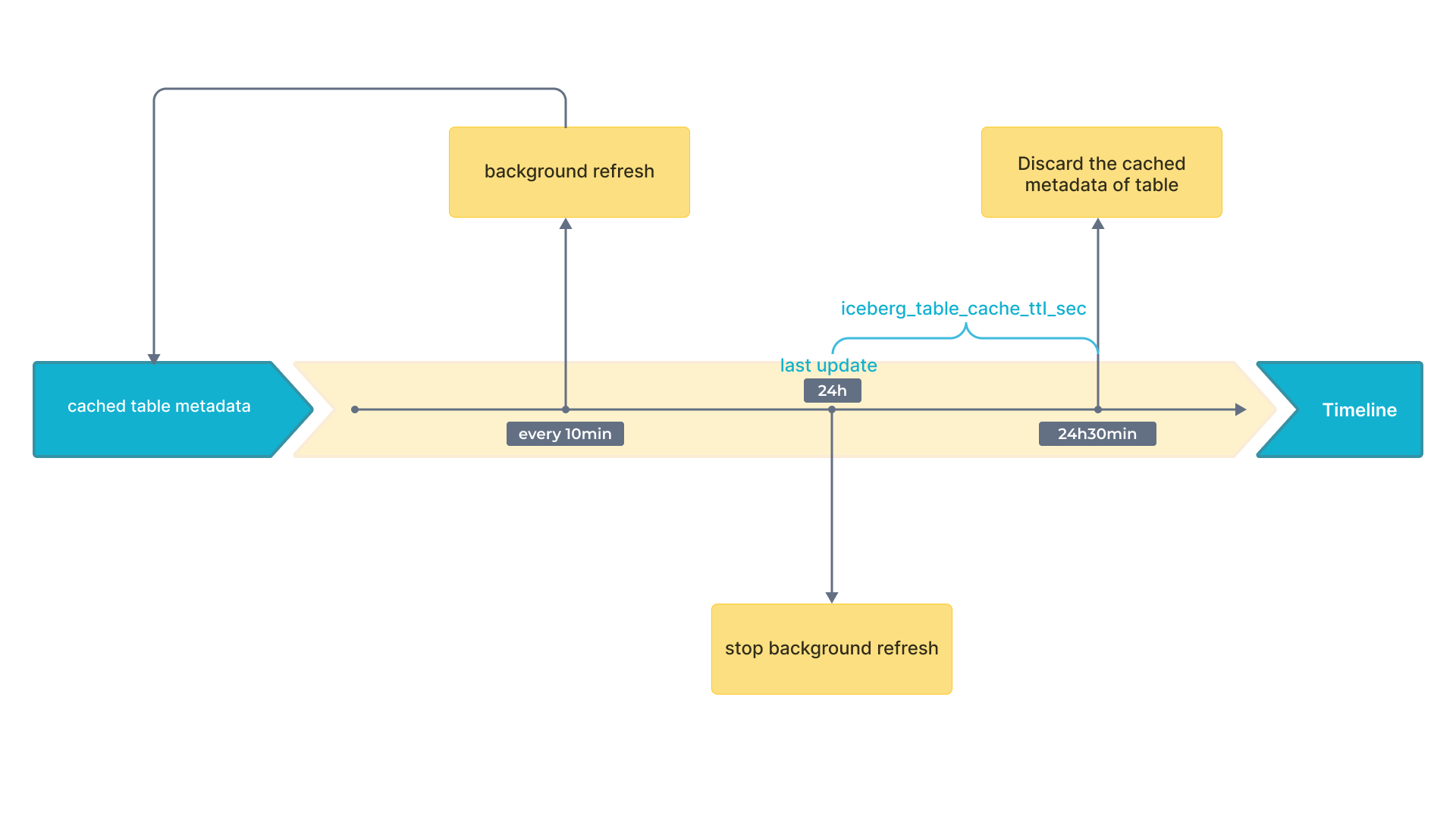
Iceberg は スナップショット をサポートしています。最新のスナップショットでは、最新の結果を得ることができる。したがって、キャッシュされたスナップショットのみがデータの鮮度に影響を与える。その結果、スナップショットを含むキャッシュのリフレッシュ戦略にのみ注意を払う必要がある。
以下のフローチャートは、時間間隔をタイムライン上に示している。
付録 B: メタデータファイルのパース
-
大量のメタデータに対する分散プラン
大量のメタデータを効果的に処理するために、StarRocks は複数の BE および CN ノードを使用して分散アプローチを採用しています。この方法は、現代のクエリエンジンの並列計算能力を活用し、マニフェストファイルの読み取り、解凍、フィルタリングなどのタスクを複数のノードに分散させます。これにより、これらのマニフェストファイルを並列に処理することで、メタデータの取得にかかる時間が大幅に短縮され、ジョブプランニングが迅速化されます。これは、多数のマニフェストファイルを含む大規模なクエリに特に有益であり、単一ポイントのボトルネックを排除し、全体的なクエリ実行効率を向上させます。
-
少量のメタデータに対するローカルプラン
小規模なクエリでは、マニフェストファイルの繰り返しの解凍と解析が不要な遅延を引き起こす可能性があるため、異なる戦略が採用されます。StarRocks は、特に Avro ファイルのデシリアライズされたメモリオブジェクトをキャッシュすることで、この問題に対処します。これらのデシリアライズされたファイルをメモリに保存することで、後続のクエリでは解凍と解析の��段階をバイパスできます。このキャッシングメカニズムにより、必要なメタデータに直接アクセスでき、取得時間が大幅に短縮されます。その結果、システムはより応答性が高くなり、高いクエリ要求やマテリアライズドビューの書き換えニーズにより適しています。
-
適応型メタデータ取得戦略(デフォルト)
StarRocks は、FE および BE/CN ノードの数、CPU コア数、現在のクエリに必要なマニフェストファイルの数など、さまざまな要因に基づいて適切なメタデータ取得方法を自動的に選択するように設計されています。この適応型アプローチにより、メタデータ関連のパラメーターを手動で調整することなく、システムが動的にメタデータ取得を最適化します。これにより、StarRocks はシームレスなエクスペリエンスを提供し、分散プランとローカルプランのバランスを取り、さまざまな条件下で最適なクエリパフォーマンスを実現します。
システム変数 plan_mode を使用して Iceberg メタデータキャッシュプランを調整できます。