フェイルオーバーグループ
このトピックでは、CelerData BYOC Cloud のフェイルオーバーグループ機能を紹介します。この機能は、v3.3.5 以降の CelerData クラシッククラスターでのみサポートされています。
概要
v3.3.5 以降、CelerData はフェイルオーバーグループ機能を通じて、複数のクラシッククラスター間でのシステムフェイルオーバーをサポートし、災害復旧、クラスター移行、システム高可用性、およびクロスクラウドデータ共有の要求に対応します。
現在、CelerData は指定されたテーブルのデータ、ロードタスク記録、および Routine Load タスク(新しいプライマリクラスターで再開可能)のレプリケーションのみをサポートしています。ユーザー、権限、マテリアライズドビューなどの他のオブジェクトはサポートされていません。
災害復旧戦略の作成、その戦略のテスト、およびレプリケーションの設定は各顧客の責任です。
利点
フェイルオーバーグループは、次の目的に役立ちます。
-
データ冗長性
フェイルオーバーグループは、プライマリクラスターからセカンダリクラスターへのデータの同期を通��じて重要なデータの冗長性を提供し、高可用性を確保します。プライマリクラスターが障害を起こした場合、サービスは迅速にセカンダリクラスターに切り替えることができます。
-
負荷分散
フェイルオーバーグループを使用すると、読み取り操作をセカンダリクラスターに分散させることができ、システム全体のスループットを向上させます。このアプローチは、読み書き分離のシナリオで有用です。
-
クロスクラウドまたはクロスリージョンのデータ同期
フェイルオーバーグループは、異なるクラウドサービスまたはリージョン間でのデータのリアルタイム同期を可能にし、通常は災害復旧や別のリージョンアクセスの要求に対応します。
-
クラスター移行
データはあるクラスターから別のクラスターに移行でき、古いクラスターのシームレスな廃止をゼロダウンタイムで実現します。
-
データ蓄積
様々な機能クラスターからのデータを単一のクラスターに集約し、データ収集と統一分析を可能にします。
-
データ統合
フェイルオーバーグループは、複数のソースからの異種データの統合を促進し、統一されたデータ利用を可能にします。
-
A/B テストのためのステージング環境
データはステージング環境と本番環境の間で同期され、A/B テストを可能にします。
概念
- フ�ェイルオーバーグループ: クラスター内で定義されたオブジェクトの集合で、レプリケートされるものです。この集合は全体として機能し、クラスター間で一方向のレプリケーションを行います。
- メンバー: フェイルオーバーグループ内のデータ同期におけるメンバー(クラスター)で、ソースクラスターがプライマリ、ターゲットクラスターがセカンダリです。
- プライマリ: データ同期のソースクラスター。フェイルオーバーグループにはプライマリクラスターが1つだけあり、そのデータは読み書き可能です。
- セカンダリ: データ同期のターゲットクラスター。フェイルオーバーグループには複数のセカンダリクラスターがあり、そのデータは読み取り専用です。
- フェイルオーバー: プライマリクラスターが障害を起こした際に、プライマリの役割を選択されたセカンダリクラスターに移すプロセスです。
- レプリケートオブジェクト: フェイルオーバーグループに含められ、クラスター間でレプリケートされるオブジェクトです。オブジェクトのタイプとインスタンスを指定する必要があります。
- レプリケーションスケジュール: 指定された間隔または時間にレプリケーションをトリガーするレプリケーションスケジューリング戦略です。SQL コマンドを実行することで手動でトリガーすることもできます。
アーキテクチャ

フェイルオーバーグループは複数のクラスターを含み、フェイルオーバーグループを使用してそれらの間に柔軟なレプリケーション関係を確立することができます。
フェイルオーバーグループは、クラスター内のカタログ、データベース、テーブルなどのオブジェクトの集合であり、この集合は全体として機能し、クラスター間で一方向のレプリケーションを行い、プライマリクラスターからセカンダリクラスターへのデータを同期します。
プライマリクラスターはフェイルオーバーグループ内のデータ同期のソースクラスターとして機能し、各フェイルオーバーグループには1つのプライマリクラスターがあり、そのデータは読み書き可能です。一方、セカンダリクラスターはデータ同期のターゲットクラスターとして機能し、フェイルオーバーグループには複数のセカンダリクラスターがあり、そのデータは読み取り専用です。
単一のクラスターは複数のフェイルオーバーグループに参加でき、あるフェイルオーバーグループではプライマリクラスターとして機能し、別のフェイルオーバーグループではセカンダリクラスターとして機能します。
プライマリクラスターが障害を起こした場合、フェイルオーバーを開始してセカンダリクラスターを新しいプライマリクラスターとして昇格させ、サービスの継続を確保します。
ワークフロー
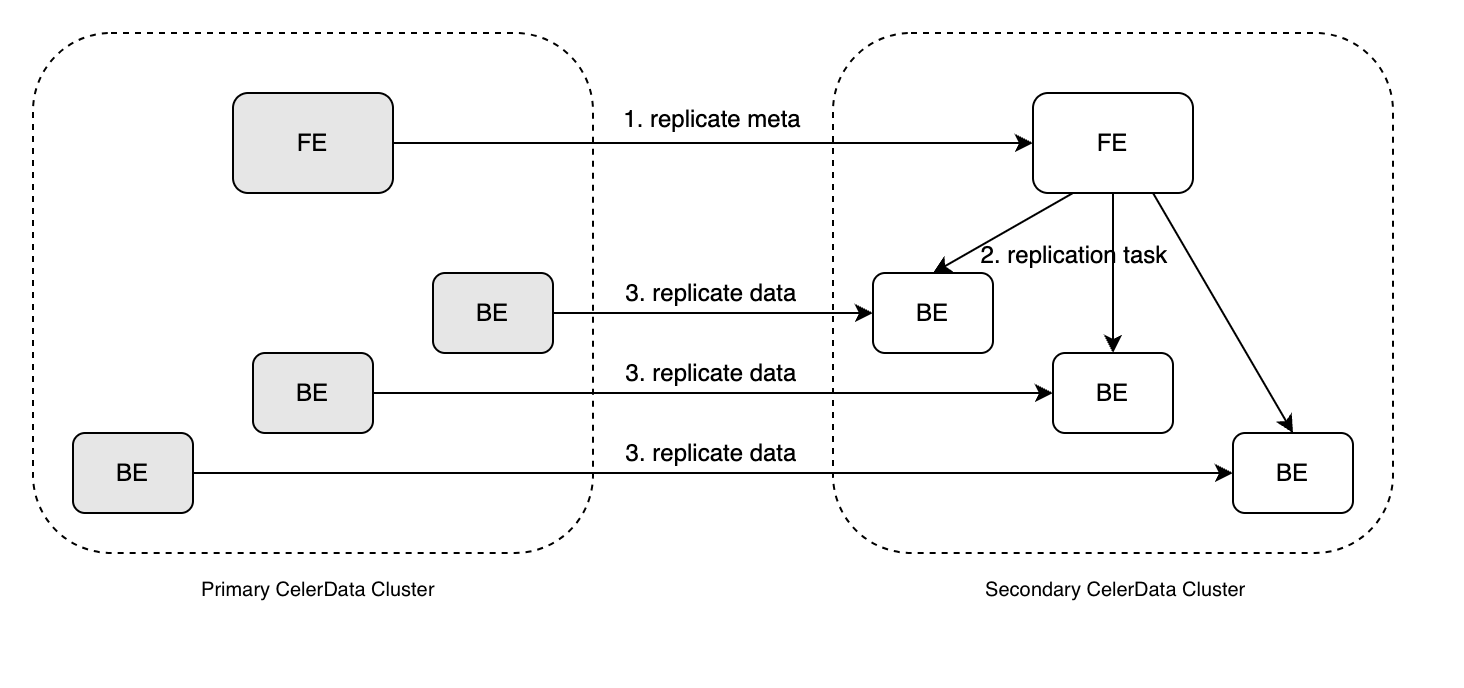
設定が完了すると、プライマリクラスターとセカンダリクラスター間のデータ同期が定期的に行われ、各同期は次の同期を開始する前に前の同期を完了する必要があります。データ同期はセカンダリクラスターによって開始され、プライマリクラスターからデータを取得し、次の特定のステップに従います。
- セカンダリクラスターの Leader FE は、プライマリクラスター内の任意の FE から最新の完全メタデータを要求します。このメタデータをローカルコピーと比較して差異を特定します。
- セカンダリクラスターの FE は、データが遅れている BE を選択し、レプリケーションタスクを発行します。このタスクには、対応するデータが存在するプライマリクラスターの BE のアドレスとレプリケートするターゲットバージョン番号が含まれます。セカンダリクラスターの対応するタブレットレプリカは、遅れているデータを検索し、ターゲットバージョンから欠落している部分のみをクローンします。
- セカンダリクラスターの BE は、プライマリクラスターの対応する BE にスナップショットのレプリケートを要求します。
- プライマリクラスターの BE は、スナップショットファイルをセカンダリクラスターの BE にレプリケートします。
- セカンダリクラスターの BE は、レプリケーションタスクが完了すると FE にタスク成功を返します。��報告を受け取ると、FE は対応するタブレットレプリカのバージョンを更新します。
フェイルオーバーグループの作成
フェイルオーバーグループを作成するには、プライマリクラスター側とセカンダリクラスター側の両方で作成する必要があります。
前提条件
フェイルオーバーグループを作成する前に、次のネットワークおよびセキュリティグループの要件が満たされていることを確認する必要があります。
ネットワーク:
- プライマリクラスターとセカンダリクラスターは同じ VPC 内にあります。
- プライマリクラスターとセカンダリクラスターが同じ VPC 内にない場合は、VPC ピアリング接続を作成する必要があります。詳細な手順については、 AWS - Create a VPC peering connection および Azure - Create a VPC peering connection を参照してください。
セキュリティグループ:
プライマリクラスターとセカンダリクラスターのすべての FE ノードが互いの http_port および rpc_port にアクセスでき、すべての BE ノードが互いの be_http_port および be_port にアクセスできることを確認する必要があります。
| コンポーネント | ポート | デフォルト |
|---|---|---|
| FE | http_port | 8030 |
| FE | rpc_port | 9020 |
| BE | be_http_port | 8040 |
| BE | be_port | 9060 |
プライマリクラスターでのフェイルオーバーグループの作成
機能的なフェイルオーバーグループを作成するには、まずプライマリクラスターで作成する必要があります。
次の構文を使用して、プライマリクラスターでフェイルオーバーグループを作成します。
CREATE FAILOVER GROUP [ IF NOT EXISTS ] <failover_group_name>
[ INCLUDE_TABLES =
[catalog_name].[database_name].<table_name>,
[catalog_name].[database_name].<table_name>, ... ]
[ EXCLUDE_TABLES =
[catalog_name].[database_name].<table_name>,
[catalog_name].[database_name].<table_name>, ... ]
MEMBERS =
'<member_name>:SELF', -- 'SELF' は現在のクラスターを示します。
'<member_name>:<fe_host>:<fe_port>'
[ , '<member_name>:<fe_host>:<fe_port>', ...]
SCHEDULE = '{<num>{s | m | h | d} | <cron_expr>'
[ COMMENT '<string_literal>' ]
[ PROPERTIES ("key"="value", ...) ]
パラメータ:
failover_group_name: 作成するフェイルオーバーグループの名前。INCLUDE_TABLES: フェイルオーバーグループに含めるテーブル。catalog_name: テーブルを含むカタログの名前。db_name: テーブルを含むデータベースの名前。ワイルドカードがサポートされています。table_name: レプリケートするテーブルの名前。ワイルドカードがサポートされています。
EXCLUDE_TABLES: フェイルオーバーグループから除外するテーブル。catalog_name: テーブルを含むカタログの名前。db_name: テーブルを含むデータベースの名前。ワイルドカードがサポートされています。table_name: 除外するテーブルの名前。ワイルドカードがサポートされています。
MEMBERS: フェイルオーバーグループのメンバー。プライマリクラスターは必須です。複数のセカンダリクラスターを定義できます。SELFを使用して現在のクラスター内の FE ノードを表すことができます。member_name: フェイルオーバーグループ内のメンバー(プライマリまたはセカンダリクラスター)の名前。fe_host: セカンダリクラスター内の任意の FE の IP アドレスまたは FQDN。fe_port: セカンダリクラスター内の任意の FE の Thrift サーバーポート(rpc_port)。
SCHEDULE: レプリケーションタスクのスケジュール。s(秒)、m(分)、h(時間)、d(日)などの単位を使用してタスク間の時間間隔を指定できます。たとえば、SCHEDULE = '15m'はレプリケーションタスクが15分ごとにトリガーされることを示します。COMMENT: フェイルオーバーグループのコメント。PROPERTIES: フェイルオーバーグループのプロパティ。
例:
CREATE FAILOVER GROUP test_failover_group
INCLUDE_TABLES = default_catalog.*.*
MEMBERS = 'test_1:SELF','test_2:xxx.xxx.xxx.xxx:xxxxx'
SCHEDULE = '10m';
セカンダリクラスターでのフェイルオーバーグループの作成
プライマリクラスターでフェイルオーバーグループが作成された後、セカンダリクラスターで対応するフェイルオーバーグループを作成する必要があります。セカンダリクラスターでフェイルオーバーグループを作成する際には、フェイルオーバーグループの名前とプライマリクラスター FE のアドレスを指定するだけで済みます。
次の構文を使用して、セカンダリクラスターでフェイルオーバーグループを作成します。
CREATE FAILOVER GROUP [ IF NOT EXISTS ] <failover_group_name>
AS REPLICA OF '<primary_fe_host>:<primary_fe_port>'
パラメータ:
failover_group_name: 作成するフェイルオーバーグループの名前。対応するプライマリクラスターで定義したものと同一でなければなりません。primary_fe_host: プライマリクラスター内の FE の IP アドレスまたは FQDN。対応するプライマリクラスターで定義したものと同一でなければなりません。primary_fe_port: プライマリクラスター内の FE の Thrift サーバーポート(rpc_port)。対応するプライマリクラスターで定義したものと同一でなければなりません。
例:
CREATE FAILOVER GROUP test_failover_group
AS REPLICA OF 'xxx.xxx.xxx.xxx:xxxxx';
プライマリクラスターでフェイルオーバーグループを作成した後、プライマリクラスターの FE はすべてのセカンダリクラスターの FE にハンドシェイクリクエストを開始します。これらのハンドシェイクリクエストはフェイルオーバーグループのメタデータを運びます。セカンダリクラスターで対応するフェイルオーバーグループが作成されていない場合、またはプライマリクラスターがセカンダリクラスターのフェイルオーバーグループのメンバーリストに含まれていない場合、ハンドシェイクリクエストは拒否されます。
拒否されると、プライマリクラスターはセカンダリクラスターがハンドシェイクを受け入れ、フェイルオーバーグループのメタデータを更新するまでハンドシェイクを送信し続けます。これが完了すると、フェイルオーバーグループは確立されたと見なされます。
フェイルオーバーグループの管理
フェイルオーバーグループの表示
-
次の構文を使用して、クラスター内で作成されたすべてのフェイルオーバーグループを表示できます。
SHOW FAILOVER GROUPS [ LIKE '<pattern>' ]例:
SHOW FAILOVER GROUPS; -
次の構文を使用して、指定されたフェイルオーバーグループの詳細を表示できます。
DESC[RIBE] FAILOVER GROUP <failover_group_name>例:
DESC FAILOVER GROUP test_failover_group;
フェイルオーバーグループの変更
フェイルオーバーグループの定義、オブジェクト、またはメンバーを変更するには、プライマリクラスターから次のステートメントを実行する必要があります。
-
フェイルオーバーグループの定義を変更するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> SET
[ INCLUDE_TABLES =
[catalog_name].[database_name].<table_name>,
[catalog_name].[database_name].<table_name>, ... ]
[ EXCLUDE_TABLES =
[catalog_name].[database_name].<table_name>,
[catalog_name].[database_name].<table_name>, ... ]
[ MEMBERS =
'<member_name>:SELF', -- 'SELF' は現在のクラスターを示します。
'<member_name>:<fe_host>:<fe_port>'
[ , '<member_name>:<fe_host>:<fe_port>', ...] ]
[ SCHEDULE = '{<num>{s | m | h | d} | <cron_expr>' ]
[ COMMENT '<string_literal>' ]
[ PROPERTIES ("key"="value", ...) ]例:
ALTER FAILOVER GROUP test_failover_group SET
INCLUDE_TABLES = default_catalog.*.*
MEMBERS = 'test_1:SELF','test_2:xxx.xxx.xxx.xxx:xxxxx'
SCHEDULE = '15m'; -
フェイルオーバーグループにオブジェクトまたはメンバーを追加するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> ADD
[ [catalog_name].[database_name].<table_name>, ... ] TO INCLUDE_TABLES ]
[ [catalog_name].[database_name].<table_name>, ... ] TO EXCLUDE_TABLES ]
[ '<member_name>:<fe_host>:<fe_port>'
[ , '<member_name>:<fe_host>:<fe_port>', ...] TO MEMBERS ]
[ ... ]例:
ALTER FAILOVER GROUP test_failover_group
ADD 'test_3:xxx.xxx.xxx.xxx:xxxxx' TO MEMBERS; -
フェイルオーバーグループからオブジェクトまたはメンバーを削除するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> REMOVE
[ [catalog_name].[database_name].<table_name>, ... ] FROM INCLUDE_TABLES ]
[ [catalog_name].[database_name].<table_name>, ... ] FROM EXCLUDE_TABLES ]
[ '<member_name>' [ , '<member_name>' , ... ] FROM MEMBERS ]
[ ... ]例:
ALTER FAILOVER GROUP test_failover_group
REMOVE 'test_2' FROM MEMBERS;
フェイルオーバーグループの操作
フェイルオーバーグループを操作して、一時停止、再開、レプリケーションの更新、またはプライマリクラスターのシフトを行うには、セカンダリクラスターから次のステートメントを実行する必要�があります。
レプリケーションの更新
セカンダリクラスターでデータレプリケーションを手動で更新するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> REFRESH
例:
ALTER FAILOVER GROUP test_failover_group REFRESH;
プライマリクラスターのシフト
現在のセカンダリクラスターを新しいプライマリクラスターとして設定するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> PRIMARY
例:
ALTER FAILOVER GROUP test_failover_group PRIMARY;
フェイルオーバーグループの一時停止
フェイルオーバーグループを一時停止するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> SUSPEND
例:
ALTER FAILOVER GROUP test_failover_group SUSPEND;
フェイルオーバーグループの再開
一時停止されたフェイルオーバーグループを再開するには、次の構文を使用します。
ALTER FAILOVER GROUP [ IF EXISTS ] <failover_group_name> RESUME
例:
ALTER FAILOVER GROUP test_failover_group RESUME;
フェイルオーバーグループの削除
フェイルオーバーグループを削除するには、次の構文を使用します。
DROP FAILOVER GROUP [ IF EXISTS ] <failover_group_name>
例:
DROP FAILOVER GROUP test_failover_group;
フェイルオーバーグループの設定
フェイルオーバーグループは、これらの FE および BE パラメータを使用して設定できます。
FE パラメータ
failover_group_interval_ms
- デフォルト: 100
- タイプ: Int
- 単位: ミリ秒
- 変更可能: いいえ
- 説明: フェイルオーバーグループタスクがスケジュールされる最小時間間隔。
- 導入バージョン: v3.3.5
failover_group_job_threads
- デフォルト: 4
- タイプ: Int
- 単位: -
- 変更可能: いいえ
- 説明: セカンダリクラスターでメタデータ同期タスクを実行するスレッドの数。
- 導入バージョン: v3.3.5
failover_group_pull_image_timeout_sec
- デフォルト: 30
- タイプ: Int
- 単位: 秒
- 変更可能: はい
- 説明: セカンダリクラスターがプライマリクラスターからイメージを取得するためのタイムアウト。
- 導入バージョン: v3.3.5
failover_group_trigger_new_image_interval_sec
- デフォルト: 600
- タイプ: Int
- 単位: 秒
- 変更可能: はい
- 説明: プライマリクラスターが積極的にイメージ生成をトリガーする最小時間間隔。
- 導入バージョン: v3.3.5
failover_group_allow_drop_extra_table
- デフォルト: false
- タイプ: Boolean
- 単位: -
- 変更可能: はい
- 説明: セカンダリクラスターで追加のテーブルやデータベースを削除することを許可するかどうか。
- 導入バージョン: v3.3.5
failover_group_allow_drop_extra_partition
- デフォルト: true
- タイプ: Boolean
- 単位: -
- 変更可能: はい
- 説明: セカンダリクラスターのテーブルで追加のパーティションを削除することを許可するかどうか。
- 導入バージョン: v3.3.5
failover_group_allow_drop_inconsistent_table
- デフォルト: true
- タイプ: Boolean
- 単位: -
- 変更可能: はい
- 説明: セカンダリクラスターで不一致のテーブルやデータベースを削除することを許可するかどうか。
- 導入バージョン: v3.3.5
failover_group_allow_drop_inconsistent_partition
- デフォルト: true
- タイプ: Boolean
- 単位: -
- 変更可能: はい
- 説明: セカンダリクラスターのテーブルで不一致のパーティションを削除することを許可するかどうか。
- 導入バージョン: v3.3.5
failover_group_error_message_keep_max_num
- デフォルト: 10
- タイプ: Int
- 単位: -
- 変更可能: いいえ
- 説明: フェイルオーバーグループで保持されるエラーメッセージの最大数。
- 導入バージョン: v3.3.5
replication_interval_ms
- デフォルト: 100
- タイプ: Int
- 単位: -
- 変更可能: いいえ
- 説明: レプリケーションタスクがスケジュールされる最小時間間隔。
- 導入バージョン: v3.3.5
replication_max_parallel_table_count
- デフォルト: 100
- タイプ: Int
- 単位: -
- 変更可能: はい
- 説明: 許可される同時データ同期タスクの最大数。システムは各テーブルに対して1つの同期タスクを作成します。
- 導入バージョン: v3.3.5
replication_max_parallel_replica_count
- デフォルト: 10240
- タイプ: Int
- 単位: -
- 変更可能: はい
- 説明: 同時同期が許可されるタブレットレプリカの最大数。
- 導入バージョン: v3.3.5
replication_max_parallel_data_size_mb
- デフォルト: 1048576
- タイプ: Int
- 単位: MB
- 変更可能: はい
- 説明: 同時同期が許可されるデータの最大サイズ。
- 導入バージョン: v3.3.5
replication_transaction_timeout_sec
- デフォルト: 86400
- タイプ: Int
- 単位: 秒
- 変更可能: はい
- 説明: 同期タスクのタイムアウト期間。
- 導入バージョン: v3.3.5
BE パラメータ
replication_threads
- デフォルト: 0
- タイプ: Int
- 単位: -
- 変更可能: はい
- 説明: レプリケーションに使用されるスレッドの最大数。
0はスレッド数を BE CPU コア数の4倍に設定することを示します。 - 導入バージョン: v3.3.5
replication_max_speed_limit_kbps
- デフォルト: 50000
- タイプ: Int
- 単位: KB/s
- 変更可能: はい
- 説明: 各レプリケーションスレッドの最大速度。
- 導入バージョン: v3.3.5
replication_min_speed_limit_kbps
- デフォルト: 50
- タイプ: Int
- 単位: KB/s
- 変更可能: はい
- 説明: 各レプリケーションスレッドの最小速度。
- 導入バージョン: v3.3.5
replication_min_speed_time_seconds
- デフォルト: 300
- タイプ: Int
- 単位: 秒
- 変更可能: はい
- 説明: レプリケーションスレッドが最小速度を下回ることが許可される時間。実際の速度が
replication_min_speed_limit_kbpsを下回る時間がこの値を超えると、レプリケーションは失敗します。 - 導入バージョン: v3.3.5
clear_expired_replication_snapshots_interval_seconds
- デフォルト: 3600
- タイプ: Int
- 単位: 秒
- 変更可能: はい
- 説明: 異常なレプリケーションによって残された期限切れスナップショットをシステムがクリアする時間間隔。
- 導入バージョン: v3.3.5
制限事項
- CelerData は、v3.3.5 以降のクラシッククラスターに対してのみフェイルオーバーグループをサポートしています。
- 現在、CelerData は次のオブジェクトのレプリケーションをサポートしています:
- 指定されたテーブルからのデータ
- ロードタスク記録
- Routine Load タスク(新しいプライマリクラスターで再開可能)
- 現在、CelerData は次のオブジェクトのレプリケーションをサポートしていませんが、これに限定されません:
- PIPE ロードタスク
- ユーザーと権限
- マテリアライズドビューなどの他のオブジェクト