Unload data into AWS S3
This topic describes how to unload data from CelerData into an AWS S3 bucket.
Step 1: Configure an S3 bucket access policy
AWS access control requirements
CelerData requires the following permissions on an S3 bucket and folder to be able to access files in the folder and its sub-folders:
s3:GetObjects3:PutObjects3:DeleteObjects3:ListBucket
Creating an IAM policy
The following step-by-step instructions describe how to configure access permissions for CelerData in your AWS Management Console so that you can use an S3 bucket to unload data:
-
Log in to the AWS Management Console.
-
From the home dashboard, choose Identity & Access Management (IAM).
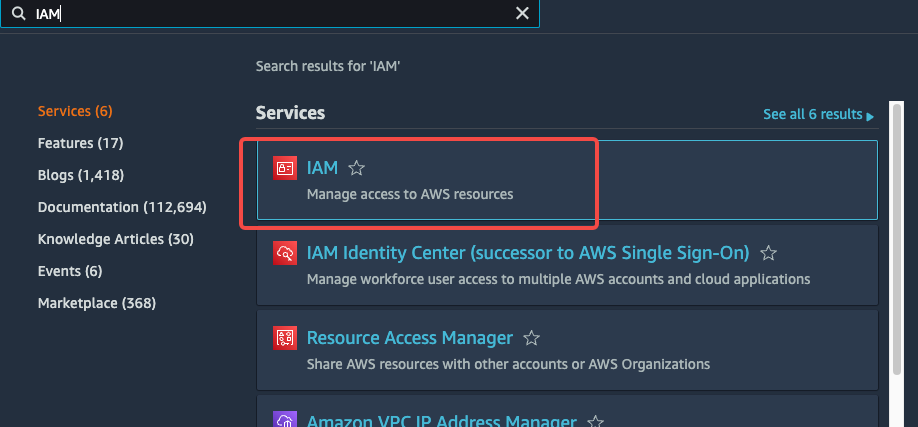
-
Choose Account settings from the left-hand navigation pane.
-
Expand the Security Token Service Regions list, find the AWS region in which your CelerData cluster is deployed, and choose Activate if the status is Inactive.
-
Choose Policies from the left-hand navigation pane.
-
Click Create Policy.

-
Click the JSON tab.
-
Add the policy document that will allow CelerData to access the S3 bucket and folder.
The following policy in JSON format provides CelerData with the required access permissions for the specified bucket and folder path. You can copy and paste the text into the policy editor:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket_name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
],
"Resource": [
"arn:aws:s3:::<bucket_name>/*"
]
}
]
}NOTE
Replace
<bucket_name>with the name of the S3 bucket that you want to access. For example, if your S3 bucket is namedbucket_s3, replace<bucket_name>withbucket_s3. -
Click Review policy.
-
Enter the policy name (for example,
celerdata_export_policy) and optionally a policy description. Then, click Create policy to create the policy.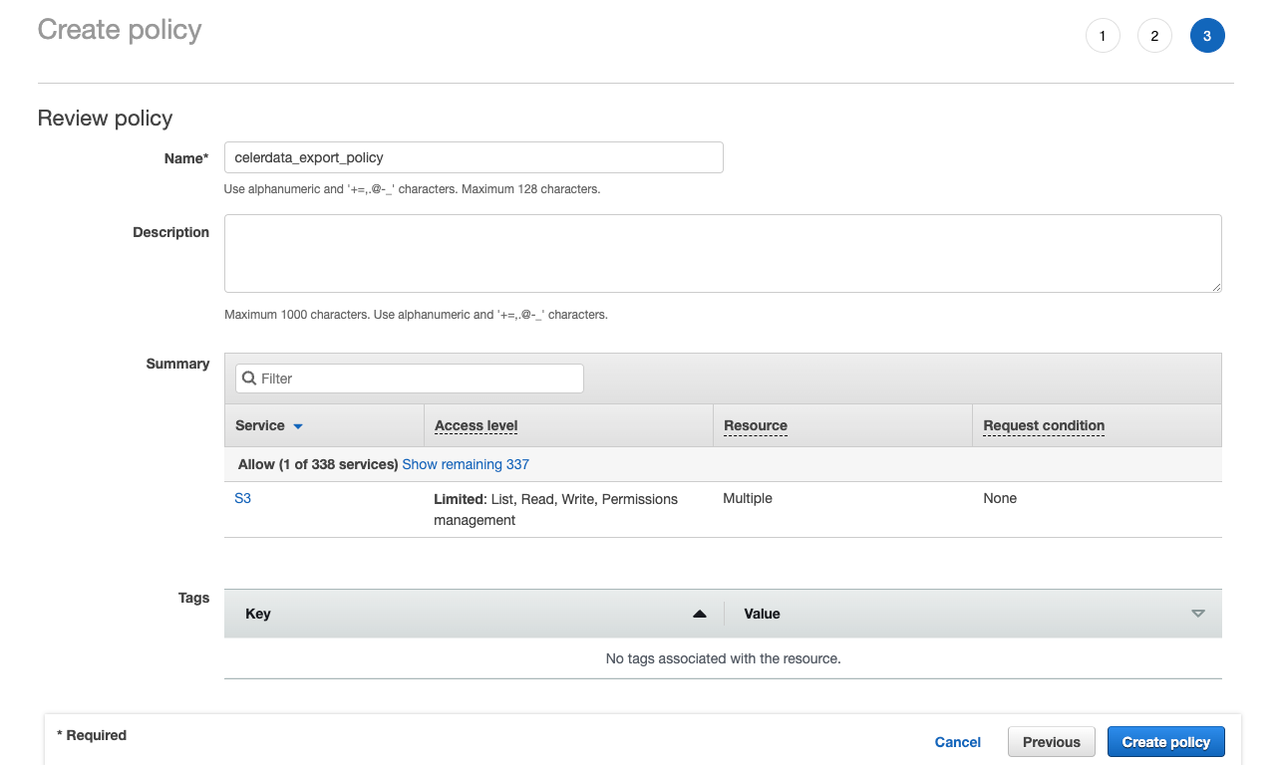
Step 2: Create an IAM user
-
Choose Users from the left-hand navigation pane and click Add user.
-
On the Add user page, enter a new user name (for example,
celerdata_export), select Access key - Programmatic access as the access type, and then click Next: Permissions.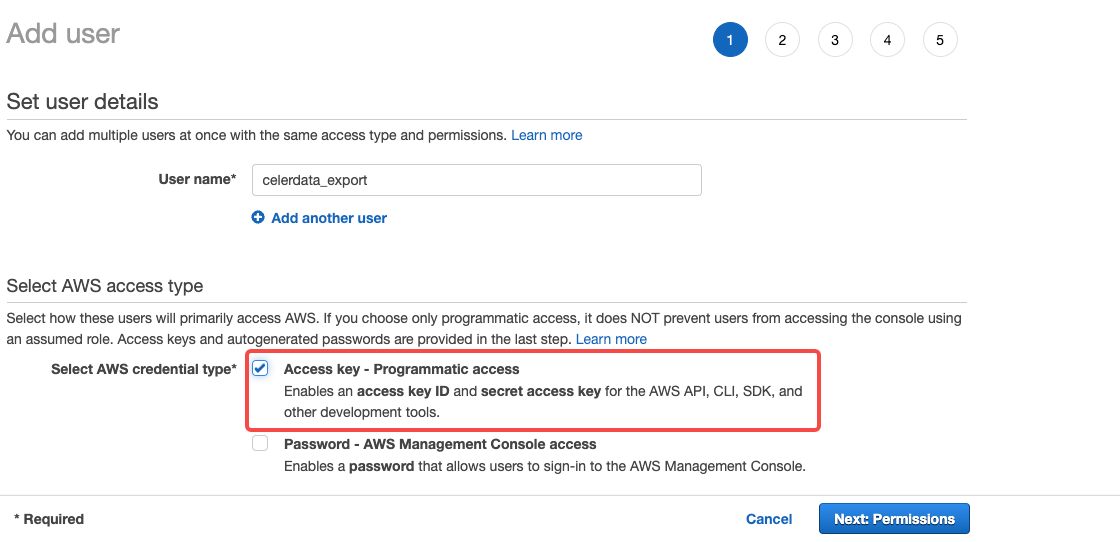
-
Click Attach existing policies directly, select the policy you created earlier, and then click Next: Tags.
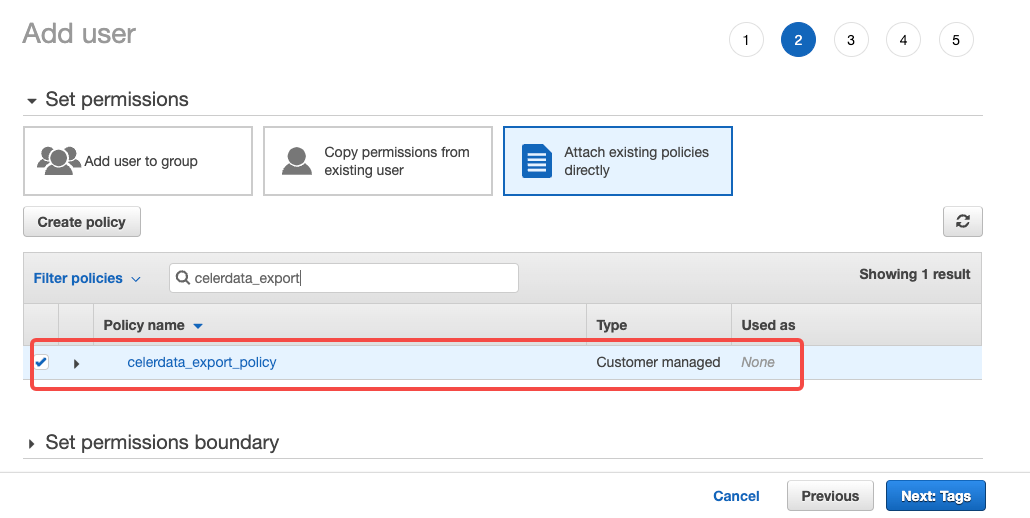
-
Review the user details. Then, click Create user.
-
Record the access credentials. The easiest way to record them is to click Download Credentials to write them to a file (for example,
credentials.csv).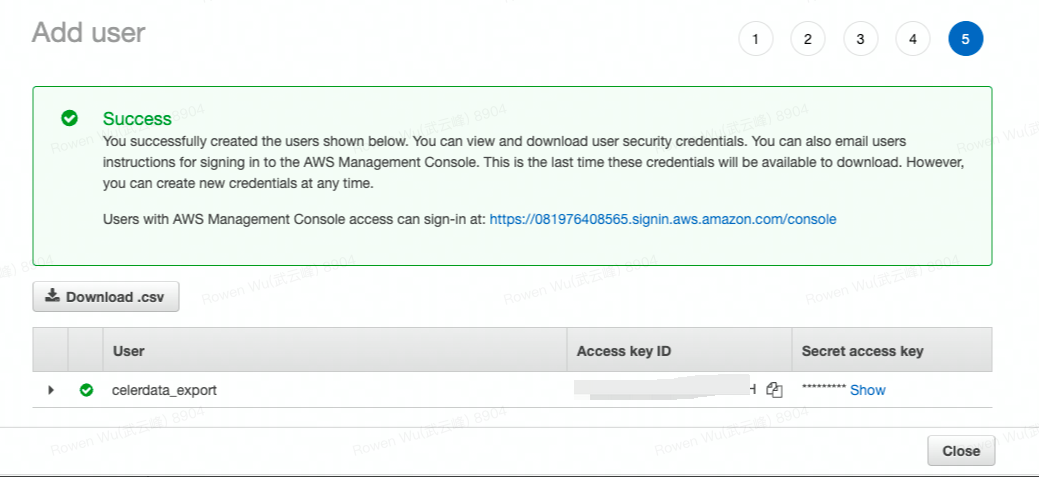
NOTICE
Once you leave this page, the Secret Access Key will no longer be available anywhere in the AWS Management Console. If you lose the key, you must generate a new set of credentials for the user.
You have now:
- Created an IAM policy for an S3 bucket.
- Created an IAM user and generated access credentials for the user.
- Attached the policy to the user.
With the AWS access key (AK) and secret key (SK) for the S3 bucket, you have the credentials necessary to access the bucket in CelerData using a broker load.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket_name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucket_name>/*"
]
}
]
}
Step 3: Unload data into AWS S3
From v3.2 onwards, CelerData supports using the table function FILES() to define a writable table in remote storage. You can then use INSERT INTO FILES to unload data from CelerData to your remote storage.
Compared to other data export methods supported by CelerData, unloading data with INSERT INTO FILES provides a more unified, easy-to-use, and rich-featured interface. You can unload the data directly into your remote storage using the same syntax you used to load data from it with a SELECT statement. In addition, it supports unloading data into Parquet, ORC, and CSV (from v3.3) format files. Therefore, in most cases, INSERT INTO FILES is recommended over EXPORT.
NOTE
The S3A protocol is used for data unloads from Amazon S3. Therefore, the file path that you specify must start with the prefix
s3a://.
Unload data using INSERT INTO FILES (Recommended)
Unloading data using INSERT INTO FILES supports different file formats (Parquet, ORC, and CSV (supported from v3.3 onwards)), compression algorithms, and a rich asset of helpful features such as Partition By Column and outputting a single data file.
With INSERT INTO FILES, you can unload the data of the entire table or the result of a complex query.
-
The following example unloads the data of the table
user_behaviorentirely into Parquet-formatted files.INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'parquet', -- Unload data as Parquet-formatted files.
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com'
)
SELECT * FROM user_behavior; -
The following example unloads the data between
2020-01-01and2024-01-01using a complex query with a WHERE clause and a JOIN. It stores data as ORC-formatted files with the LZ4 compression algorithm, partitions the data by month (based on thedtcolumn), and distributes it into different directories underuser_behavior/.INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'orc', -- Unload data as ORC-formatted files.
'compression' = 'lz4', -- Use the LZ4 compression algorithm.
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com',
'partition_by' = 'dt' -- Partition the data by month into different directories.
)
SELECT tb.*, tu.name FROM user_behavior tb
JOIN users tu on tb.user_id = tu.id
WHERE tb.dt >= '2020-01-01' and tb.dt < '2024-01-01';NOTE
The
partition_byparameter will partition the data based on the specified column, and store the data in sub-directories formatted asprefix/<column_name>=<value>/, for example,mybucket/path/to/user_behavior/dt=2020-01-01/. -
The following example unloads the data into a single CSV-formatted file with the column separator as a comma (
,).INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'csv', -- Unload data as a CSV-formatted file.
'csv.column_separator' = ',', -- Use `,` as the column separator.
'single' = 'true', -- Output the data into a single file.
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com'
)
SELECT * FROM user_behavior; -
The following example unloads the data in multiple Parquet-formatted files each with a maximum size of
100000000bytes.INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'parquet',
'target_max_file_size' = '100000000', -- Set the maximum file size as 100000000 bytes.
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com'
)
SELECT * FROM user_behavior;
| Parameter | Description |
|---|---|
| bucket_name | The name of the S3 bucket into which you want to unload data. |
| format | The format of the data files. Valid values: parquet, orc, and csv. |
| compression | The compression algorithm used for the data files. This parameter is only supported for Parquet and ORC file formats. Valid values: uncompressed (Default), gzip, snappy, zstd, and lz4. |
| aws.s3.access_key | The Access Key ID that you can use to access the S3 bucket. |
| aws.s3.secret_key | The Secret Access Key that you can use to access the S3 bucket. |
| aws.s3.endpoint | The endpoint that you can use to access the S3 bucket. region_id in the endpoint is the ID of the AWS region to which the S3 bucket belongs. |
| partition_by | The list of columns that are used to partition data files into different storage paths. Multiple columns are separated by commas (,). |
| csv.column_separator | The column separator used for the CSV-formatted data file. |
| single | Whether to unload the data into a single file. Valid values: true and false (Default). |
| target_max_file_size | The best-effort maximum size of each file in the batch to be unloaded. Unit: Bytes. Default value: 1073741824 (1 GB). When the size of data to be unloaded exceeds this value, the data will be divided into multiple files, and the size of each file will not significantly exceed this value. |
Refer to FILES() for detailed instructions and all parameters involved.
Unload data using EXPORT
You can use the EXPORT statement to unload all data from a table or only the data from specific partitions of a table into an S3 bucket.
EXPORT TABLE <table_name>
[PARTITION (<partition_name>[, <partition_name>, ...])]
TO "s3a://<bucket_name>/path/to"
WITH BROKER
(
"aws.s3.access_key" = "<your_access_key_id>",
"aws.s3.secret_key" = "<your_secret_access_key>",
"aws.s3.endpoint" = "s3.<region_id>.amazonaws.com"
);
The following table describes the parameters.
| Parameter | Description |
|---|---|
| table_name | The name of the table from which you want to unload data. |
| partition_name | The name of the partition from which you want to unload data. If you specify multiple partitions, separate the partition names with a comma (,) and a space. |
| bucket_name | The name of the S3 bucket into which you want to unload data. |
| aws.s3.access_key | The Access Key ID that you can use to access the S3 bucket. |
| aws.s3.secret_key | The Secret Access Key that you can use to access the S3 bucket. |
| aws.s3.endpoint | The endpoint that you can use to access the S3 bucket. region_id in the endpoint is the ID of the AWS region to which the S3 bucket belongs. |
For more information, see EXPORT.
Limits
- The AWS AK and SK used as credentials are necessary.
- For unloading data using INSERT INTO FILES:
- Outputting CSV-formatted files is supported only from v3.3 onwards.
- Setting compression algorithm is not supported for CSV-formatted files.