Load data from Confluent Cloud using Kafka connector
This topic introduces how to use a Kafka connector, starrocks-kafka-connector, to stream messages (events) from Confluent into CelerData. The Kafka connector guarantees at-least-once semantics.
The Kafka connector can seamlessly integrate with Kafka Connect, which allows CelerData better integrated with the Kafka ecosystem. It is a wise choice if you want to load real-time data into CelerData. Compared with Routine Load, the Kafka connector is recommended in the following scenarios:
- Load data in various other formats such as Protobuf than Routine Load which supports only CSV, JSON, and Avro formats. As long as data can be converted into JSON and CSV formats using Kafka Connect's converters, data can be loaded into CelerData via the Kafka connector.
- Customize data transformation, such as Debezium-formatted CDC data.
- Load data from multiple Kafka topics.
- Load data from Confluent Cloud.
- Need finer control over load batch sizes, parallelism, and other parameters to achieve a balance between load speed and resource utilization.
Before you begin
Make sure the Confluent cluster can connect to the CelerData cluster over the Internet.
Configure the networking for the CelerData cluster
-
Make sure the CelerData cluster can be connected from the Internet, especially when the CelerData cluster is in a private subnet. If the CelerData cluster is in a public subnet, the CelerData cluster can be connected over the Internet by default. This topic uses a CelerData cluster in a public subnet as an example.
-
Make sure that the security group with which the CelerData cluster resources are associated allows traffic from the Confluent cluster.
-
Sign in to the CelerData Cloud BYOC console and find the Security Group ID with which the CelerData cluster is associated:

-
Sign in to the Amazon VPC console.
-
In the left-side navigation pane, choose Security Groups. On the page that appears, find the security group with which the CelerData cluster resources are associated.
-
On the Inbound Rules tab, choose Edit inbound rules.
-
Add the following rules highlighted in the red box:
You must add ports
443and9030.
-
Basic steps
The following example demonstrates how to load Avro-formatted records from Confluent Cloud into CelerData.
- Use a source connector to generate data into a topic of the Confluent cluster. In the following example, the source connector is Datagen Source and the data format is Avro.
- Create a CelerData table.
- Use a sink connector (a custom connector, starrocks-kafka-connector, needs to be used) to load data from the topic of the Confluent cluster into the CelerData table.
Generate data into a topic of a Confluent cluster
-
Choose the Confluent cluster, enter its Connectors page, and click + Add Connector. Then choose Datagen Source as the source connector.
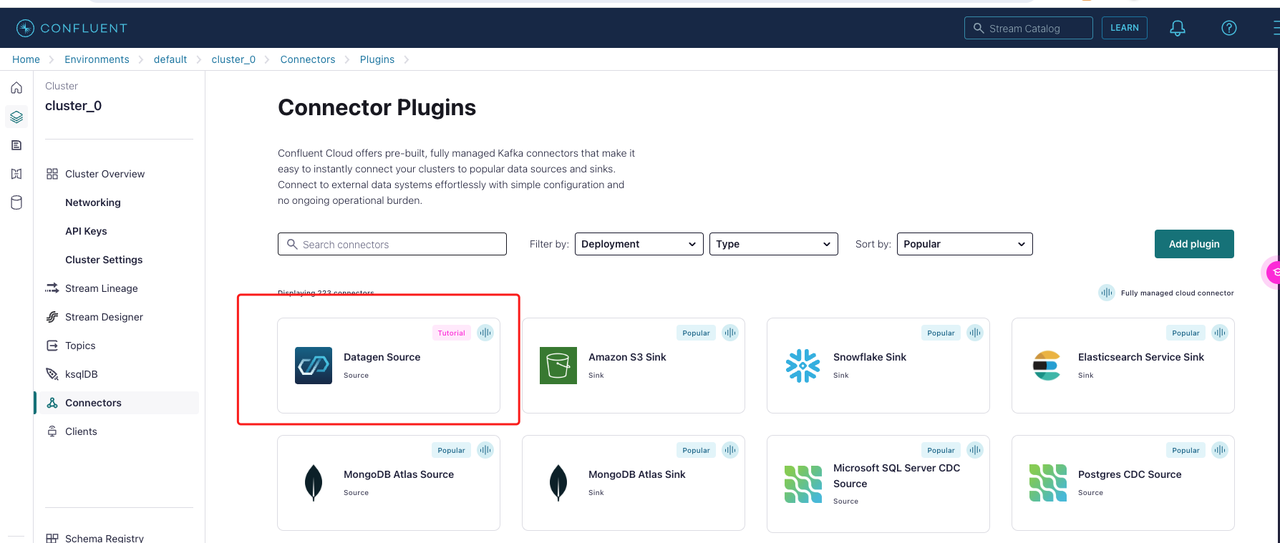
-
Configure the Datagen Source connector.
-
In the Topic selection section:
Click + Add new topic and specify the name and the partition number of the topic. In this example, the name of the topic is specified as
datagen_topic.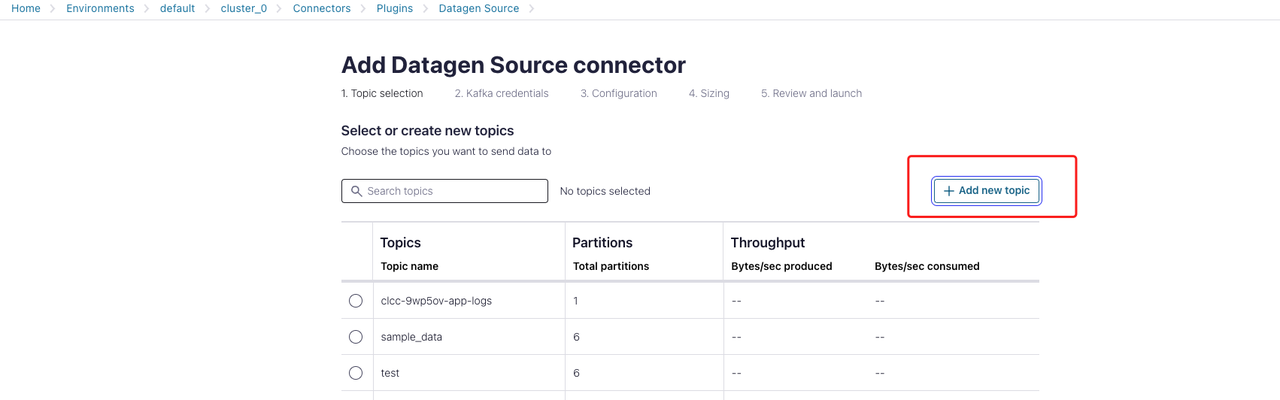
-
In the Kafka credentials section:
This example is a simple guide to quickly familiarize you with the loading process, so you can choose Global access and then click Generate API key & download.
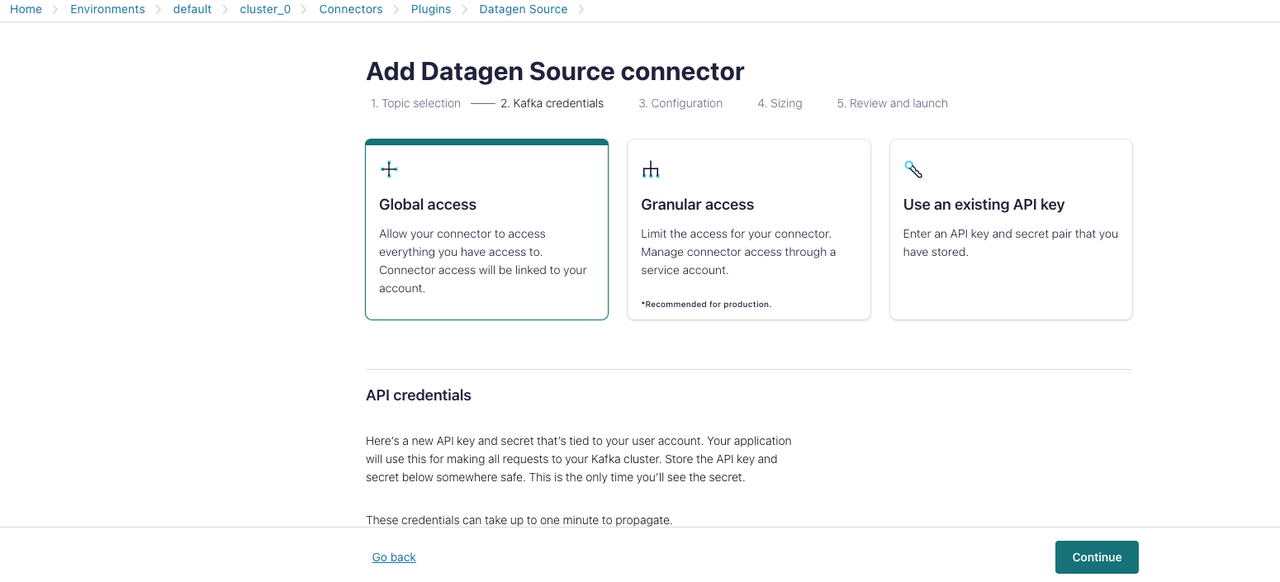
-
In the Configuration section:
Select the output record value format and template. In this example, specify the format as
AVROand the template asorders.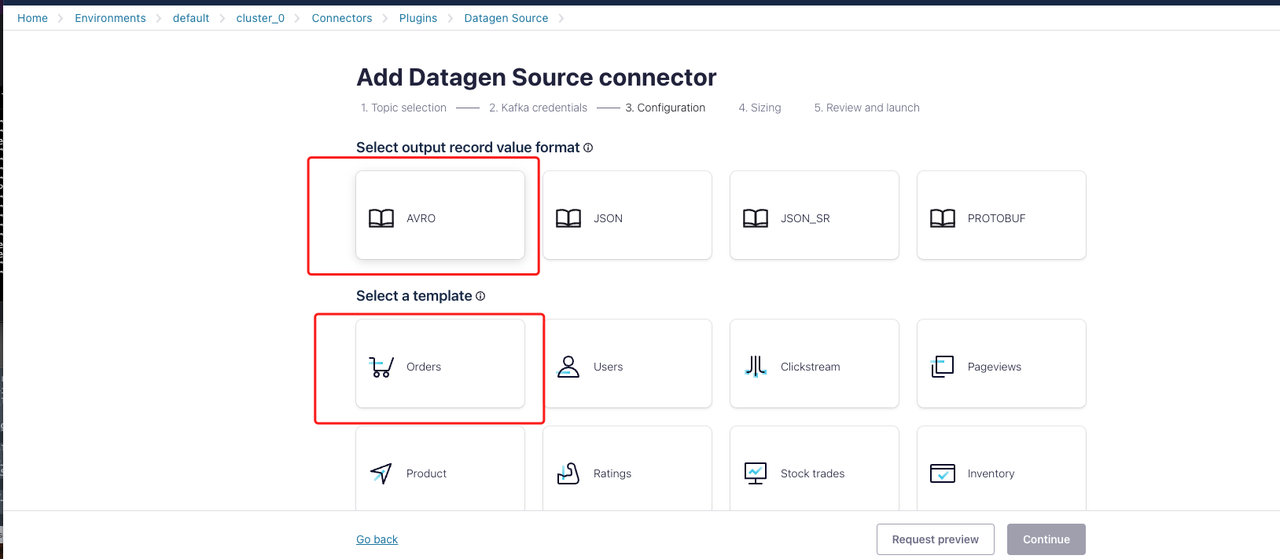
-
In the Sizing section:
Use the default configurations.
-
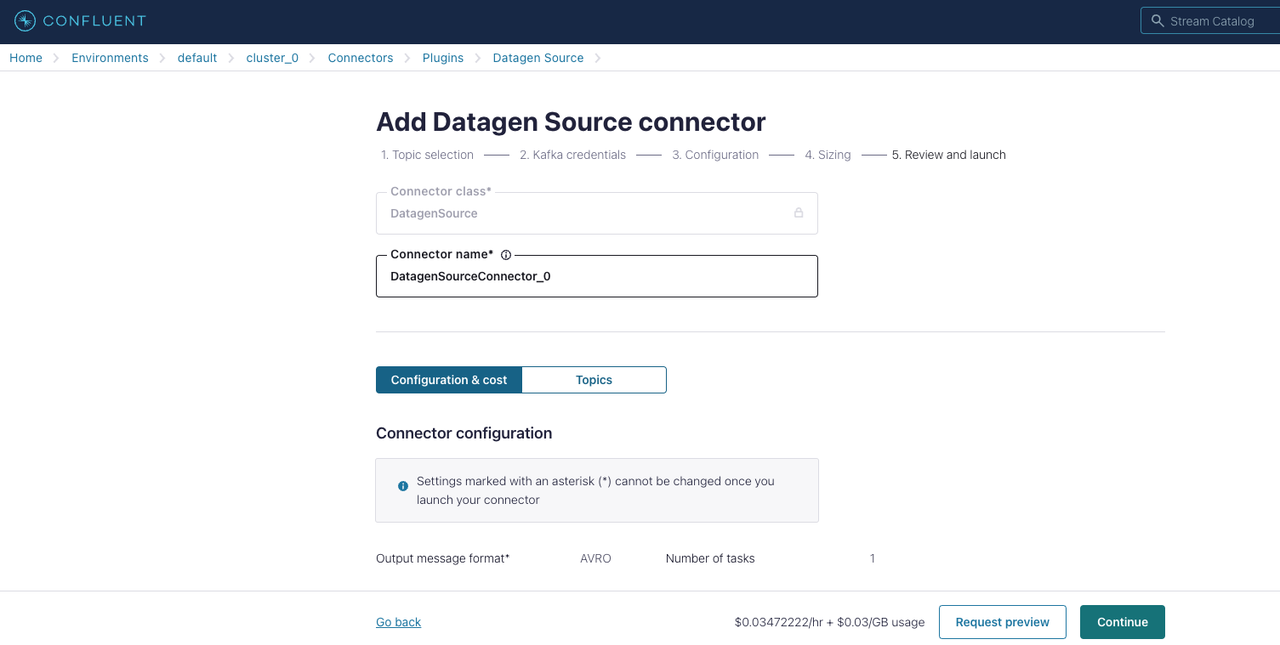
In the Review and launch section:
Check the configurations for the Datagen source connector, and click Continue once you validate all the configurations.
-
-
On the Connectors page, check the Datagen source connector you have added.
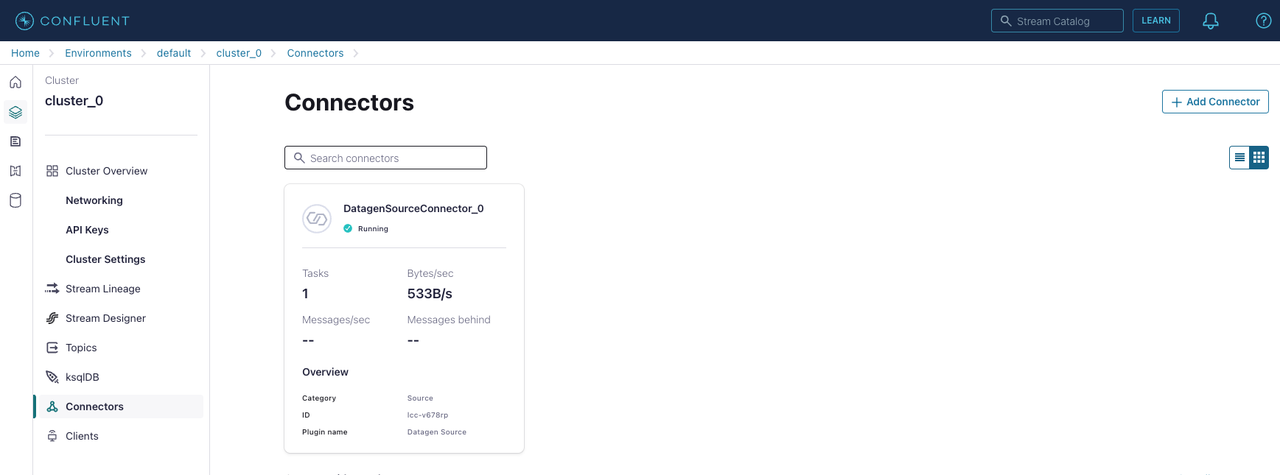
After the Datagen source connector is running, you can verify that messages are populating the topic
datagen_topic.
Create a table in the Celerdata cluster
Create a table in the Celerdata cluster according to the schema of Avro-formatted records in the topic datagen_topic.
CREATE TABLE test123 (
ordertime LARGEINT,
orderid int,
itemid string,
orderunits string,
city string,
state string,
zipcode bigint
)
DISTRIBUTED BY HASH(orderid);
Load data into the Celerdata table
In this example, the sink connector, which is a custom connector (Kafka connector named starrocks-kafka-connector), is used to load Avro-formatted records from the Confluent topic into the CelerData table.
NOTE
The Kafka connector named starrocks-kafka-connector is a custom connector, and custom connectors can only be created in AWS regions supported by Confluent Cloud. For more information about the abilities and limitations of custom connectors, see Confluent Documentation.
-
Enter the Connectors page of the Confluent cluster, click + Add Connector and click Add plugin.
-
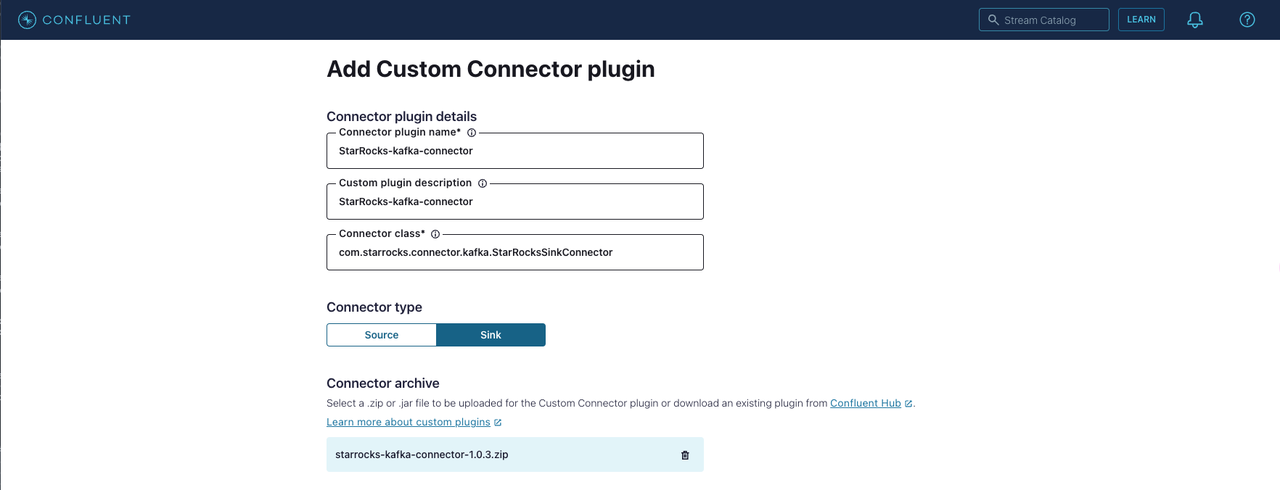
Upload the archive of Kafka connector.
-
Connector plugin detail:
- Connector plugin name: Enter the name of the Kafka connector, such as
StarRocks-kafka-connector. - Custom plugin description: Enter a description for the Kafka connector.
- Connector class: Enter the Java class for the Kafka connector, which is
com.starrocks.connector.kafka.StarRocksSinkConnector.
- Connector plugin name: Enter the name of the Kafka connector, such as
-
Connector type: Select the connector type as Sink.
-
Connector archive: Click Select connector archive and upload the ZIP file of the Kafka connector.
You can download the TAR file of the Kafka connector from Github and extract the TAR file. You need to compress all the files into a ZIP file and then upload the ZIP file.
-
-
Configure and launch the Kafka connector.
-
Enter the Connectors page of the Confluent cluster, click + Add Connector and select the StarRocks-kafka-connector.
-
In the Kafka credentials section:
This example is a simple guide to quickly familiarize you with the loading process, so you can choose Global access and click Generate API key & download.
-
In the Configuration section:
Add the configurations in key-value pair or JSON format. This example adds configurations in the JSON format.
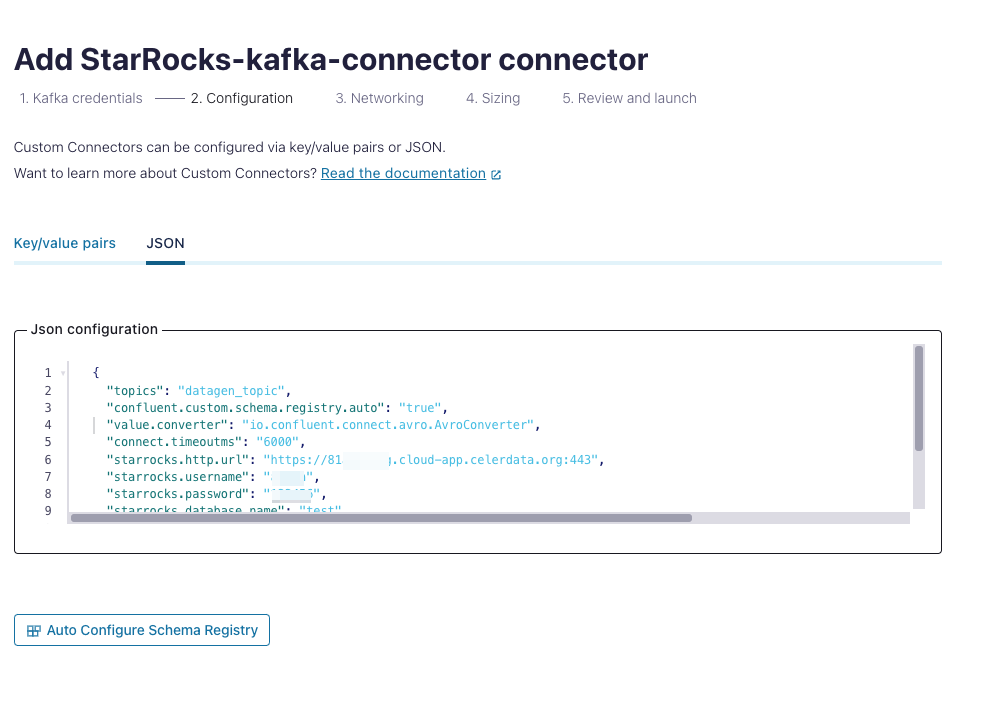
The complete JSON-formatted configurations are as follows:
{
"topics": "datagen_topic",
"confluent.custom.schema.registry.auto": "true",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"connect.timeoutms": "6000",
"starrocks.http.url": "https://81xxxxxxx.cloud-app.celerdata.org:443",
"starrocks.username": "xxxxxx",
"starrocks.password": "xxxxxx",
"starrocks.database.name": "test",
"starrocks.topic2table.map": "datagen_topic:test123",
"sink.properties.strip_outer_array": "true",
"sink.properties.jsonpaths": "[\"$.ordertime\",\"$.orderid\",\"$.itemid\",\"$.orderunits\",\"$.address.city\",\"$.address.state\",\"$.address.zipcode\"]"
}Configurations:
For the supported configurations and descriptions, see Parameters. Take special notice of the following configurations:
-
starrocks.http.url: Enter the HTTP URL of your CelerData cluster in the format ofhttps://<endpoint>:443. The endpoint can be found in the connection section on the Overview page of the CelerData cluster.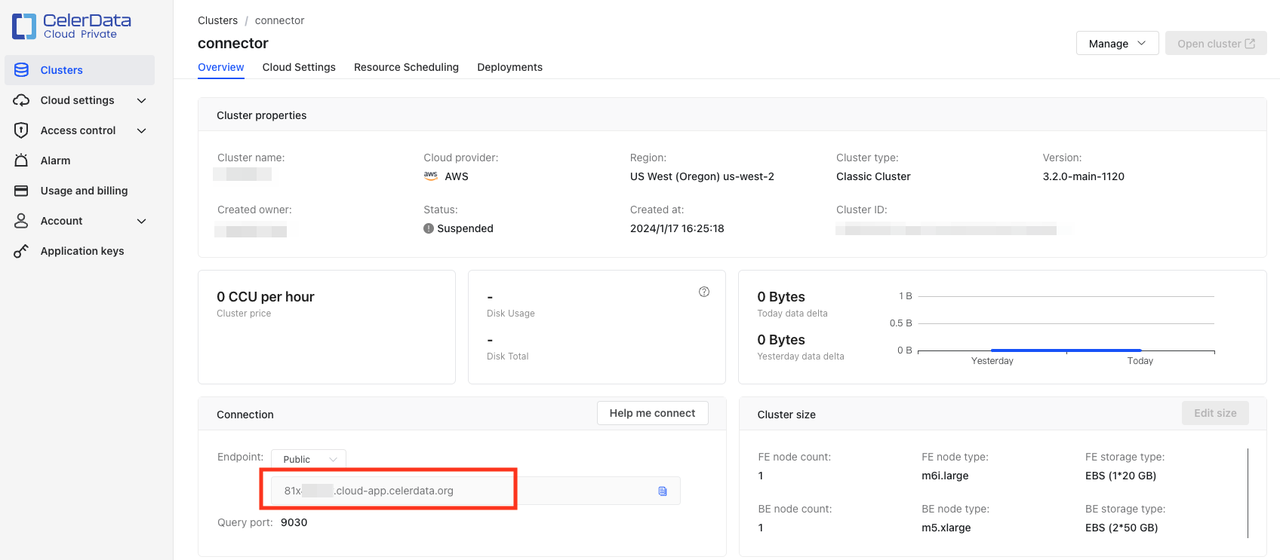
-
Also, some configurations need to be added according to the source data format.
In this example, the source data is AVRO records and Confluent Cloud Schema Registry is used, so the required configurations also need to include
confluent.custom.schema.registry.autoandvalue.converter. For more information, see Confluent Documentation.{
"topics": "datagen_topic",
"confluent.custom.schema.registry.auto": "true",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"connect.timeoutms": "6000",
"starrocks.http.url": "https://81xxxxxxx.cloud-app.celerdata.org:443",
"starrocks.username": "xxxxxx",
"starrocks.password": "xxxxxx",
"starrocks.database.name": "test",
"starrocks.topic2table.map": "datagen_topic:test123",
"sink.properties.strip_outer_array": "true",
"sink.properties.jsonpaths": "[\"$.ordertime\",\"$.orderid\",\"$.itemid\",\"$.orderunits\",\"$.address.city\",\"$.address.state\",\"$.address.zipcode\"]"
}If the source data is JSON records without Schema Registry, the required configurations also need to include:
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",The complete configurations can be as follows:
{
"topics": "datagen_topic",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"connect.timeoutms": "6000",
"starrocks.http.url": "https://81xxxxxxx.cloud-app.celerdata.org:443",
"starrocks.username": "xxxxxx",
"starrocks.password": "xxxxxx",
"starrocks.database.name": "test",
"starrocks.topic2table.map": "datagen_topic:test123",
"sink.properties.strip_outer_array": "true",
"sink.properties.jsonpaths": "[\"$.ordertime\",\"$.orderid\",\"$.itemid\",\"$.orderunits\",\"$.address.city\",\"$.address.state\",\"$.address.zipcode\"]"
}
-
-
In the Networking section:
Enter the format of a connection endpoint is
<endpoint>:443:TCPwhere the endpoint is same as the one instarrocks.http.urlwhose format ishttps://<endpoint>:443.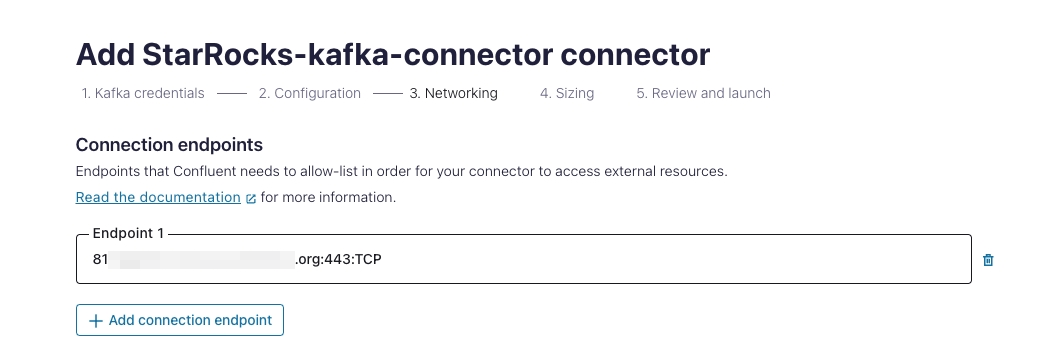
-
In the Sizing section:
Use the default settings.
-
In the Review and launch section:
Check the configurations for the Kafka connector, and click Continue once you validate all the configurations.
-
-
On the Connectors page, check the Kafka connector you have launched.
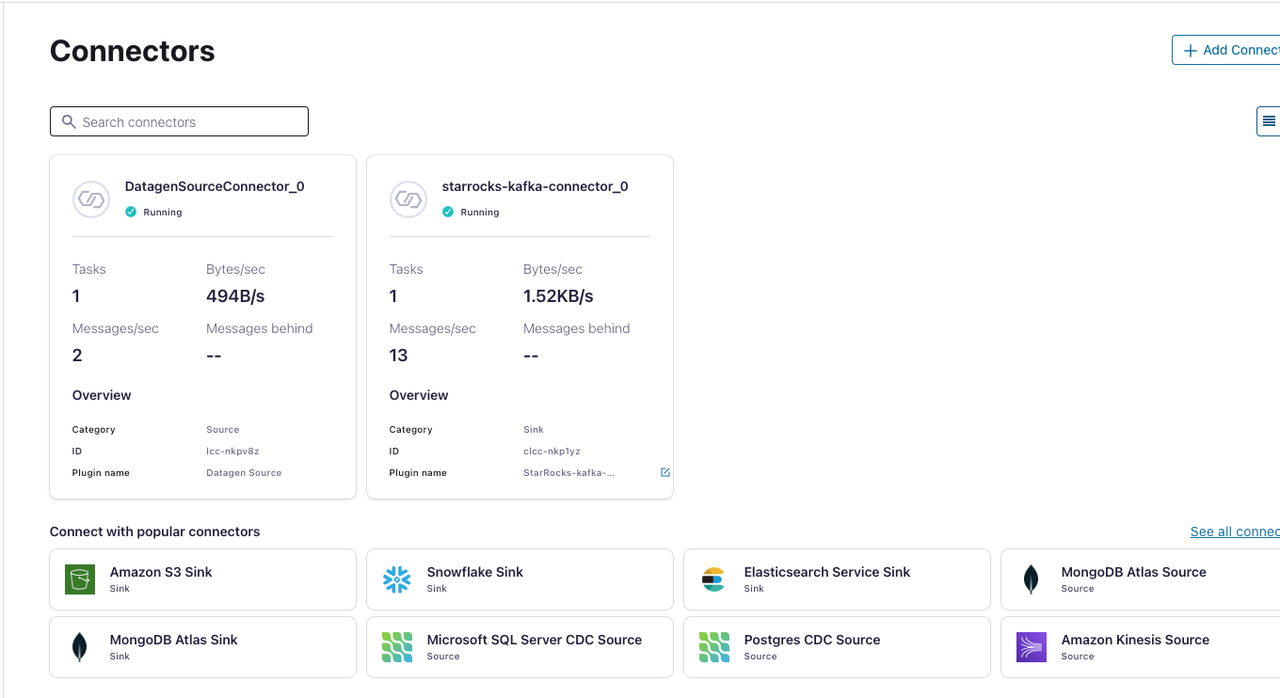
Once the Kafka connector completes provisioning, the status changes to running.
-
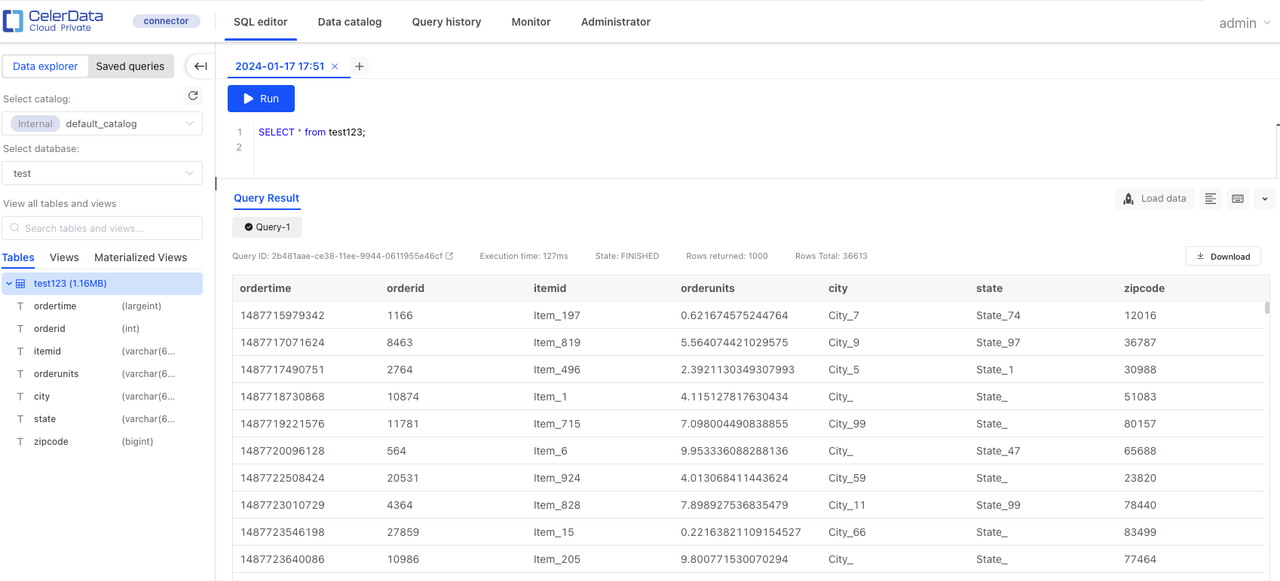
After both connectors are running, check the data in the CelerData table.
Parameters
name
- Required: YES
- Default value:
- Description: Name for this Kafka connector. It must be globally unique among all Kafka connectors within this Kafka Connect cluster. For example, starrocks-kafka-connector.
connector.class
- Required: YES
- Default value: com.starrocks.connector.kafka.SinkConnector
- Description: Class used by this Kafka connector's sink.
topics
- Required: YES
- Default value:
- Description: One or more topics to subscribe to, where each topic corresponds to a CelerData table. By default, CelerData assumes that the topic name matches the name of the CelerData table. So CelerData determines the target CelerData table by using the topic name. Please choose to fill in either
topicsortopics.regex(below), but not both. However, if the CelerData table name is not the same as the topic name, then use the optionalstarrocks.topic2table.mapparameter (below) to specify the mapping from topic name to table name.
topics.regex
- Required:
- Default value:
- Description: Regular expression to match the one or more topics to subscribe to. For more description, see
topics. Please choose to fill in eithertopics.regexortopics(above), but not both.
starrocks.topic2table.map
- Required: NO
- Default value:
- Description: Mapping of the CelerData table name and the topic name when the topic name is different from the CelerData table name. The format is
<topic-1>:<table-1>,<topic-2>:<table-2>,....
starrocks.http.url
- Required: YES
- Default value:
- Description: HTTP URL of your CelerData cluster in the format is
https://<endpoint>:443. The endpoint can be found in the connection section on the CelerData cluster's Overview page.
starrocks.database.name
- Required: YES
- Default value:
- Description: Name of the CelerData database.
starrocks.username
- Required: YES
- Default value:
- Description: Username of your CelerData cluster account. The user needs the INSERT privilege on the CelerData table.
starrocks.password
- Required: YES
- Default value:
- Description: Password of your CelerData cluster account.
key.converter
- Required: NO
- Default value: Key converter used by Kafka Connect cluster
- Description: Key converter for the sink connector (Kafka-connector-starrocks), which is used to deserialize the keys of Kafka data. The default key converter is the one used by Kafka Connect cluster.
value.converter
- Required: NO
- Default value: Value converter used by Kafka Connect cluster
- Description: Value converter for the sink connector (kafka-connector-starrocks), which is used to deserialize the values of Kafka data. The default value converter is the one used by Kafka Connect cluster.
key.converter.schema.registry.url
- Required: NO
- Default value:
- Description: Schema registry URL for the key converter.
value.converter.schema.registry.url
- Required: NO
- Default value:
- Description: Schema registry URL for the value converter.
tasks.max
- Required: NO
- Default value: 1
- Description: Maximum number of task threads that the Kafka connector can create, which is usually the same as the number of CPU cores on the worker nodes in the Kafka Connect cluster. You can tune this parameter to control load performance.
bufferflush.maxbytes
- Required: NO
- Default value: 94371840(90M)
- Description: Maximum size of data that can be accumulated in memory before being sent to CelerData at a time. The maximum value ranges from 64 MB to 10 GB. Keep in mind that the Stream Load SDK buffer may create multiple Stream Load jobs to buffer data. Therefore, the threshold mentioned here refers to the total data size.
bufferflush.intervalms
- Required: NO
- Default value: 300000
- Description: Interval for sending a batch of data which controls the load latency. Range: [1000, 3600000].
connect.timeoutms
- Required: NO
- Default value: 1000
- Description: Timeout for connecting to the HTTP URL. Range: [100, 60000].
sink.properties.*
- Required:
- Default value:
- Description: Stream Load parameters o control load behavior. For example, the parameter
sink.properties.formatspecifies the format used for Stream Load, such as CSV or JSON. For a list of supported parameters and their descriptions, see STREAM LOAD.
sink.properties.format
- Required: NO
- Default value: json
- Description: Format used for Stream Load. The Kafka connector will transform each batch of data to the format before sending them to CelerData. Valid values:
csvandjson. For more information, see CSV parameters and JSON parameters.
Limits
- It is not supported to flatten a single message from a Kafka topic into multiple data rows and load into CelerData.
- The Kafka connector's sink guarantees at-least-once semantics.