Load data from a local file system
CelerData allows you to load data from a local file system by using Stream Load.
Stream Load is an HTTPS-based synchronous loading method. After you submit a load job, CelerData synchronously runs the job, and returns the result of the job after the job finishes. You can determine whether the job is successful based on the job result.
Stream Load is suitable for loading of data less than 10 GB from a local file system.
Supported formats
Supported file formats are CSV and JSON.
For CSV data, take note of the following points:
- You can use a UTF-8 string, such as a comma (,), tab, or pipe (|), whose length does not exceed 50 bytes as a text delimiter.
- Null values are denoted by using
\N. For example, a data file consists of three columns, and a record from that data file holds data in the first and third columns but no data in the second column. In this situation, you need to use\Nin the second column to denote a null value. This means the record must be compiled asa,\N,binstead ofa,,b, becausea,,bdenotes that the second column of the record holds an empty string.
Limits
Stream Load does not support loading the data of a CSV file that contains a JSON-formatted column.
Before you begin
Make source data ready
Make sure that the source data in your local file system is ready, and obtain the path in which the source data is stored.
In this topic, two sample data files are used as examples:
-
A CSV file named
example1.csv. The file consists of three columns, which represent the user ID, user name, and user score in sequence.1,Lily,232,Rose,233,Alice,244,Julia,25 -
A JSON file named
example2.json. The file consists of two columns, which represent city ID and city name in sequence.{"name": "Beijing", "code": 2}
Check privileges
You can load data into tables within your CelerData cluster only as a user who has the INSERT privilege on the tables. If you do not have the INSERT privilege, follow the instructions provided in GRANT to grant the INSERT privilege to the user that you use to connect to your CelerData cluster.
The account admin of a CelerData cluster has all privileges enabled within that cluster. If you use this account to connect to the cluster, you do not need to perform GRANT operations.
Connect to CelerData
Before you start a load job, you need to:
-
Connect to your CelerData cluster.
-
Specify the catalog and then the database to use.
In this topic, assume that you select a database named
mydatabase. You can create this database by using the CREATE DATABASE statement:CREATE DATABASE mydatabase; -
Make sure that the destination table is ready.
If you do not have a table in the database you specify, you can create one by using the CREATE TABLE statement.
In this topic, create two tables like below:
-
A Primary Key table named
table1. The table consists of three columns:id,name, andscore, of whichidis the primary key.CREATE TABLE `table1`(`id` int(11) NOT NULL COMMENT "user ID",`name` varchar(65533) NULL COMMENT "user name",`score` int(11) NOT NULL COMMENT "user score")ENGINE=OLAPPRIMARY KEY(`id`)DISTRIBUTED BY HASH(`id`); -
A Primary Key table named
table2. The table consists of two columns:idandcity, of whichidis the primary key.CREATE TABLE `table2`(`id` int(11) NOT NULL COMMENT "city ID",`city` varchar(65533) NULL COMMENT "city name")ENGINE=OLAPPRIMARY KEY(`id`)DISTRIBUTED BY HASH(`id`);
NOTE
CelerData can automatically set the number of buckets (
BUCKETS) when you create a table or add a partition. You do not need to set the number of buckets by hand.In CelerData, some literals are used as reserved keywords by the SQL language. Do not directly use these keywords in SQL statements. If you want to use such a keyword in an SQL statement, enclose it in a pair of backticks (`). See Keywords.
-
-
If the destination cluster is an elastic cluster, also specify the warehouse to use.
Note that the warehouse you specify must be running.
For the examples below in this topic, assume that the destination cluster is an elastic cluster, and you select
default_warehouseas the destination warehouse.
Start a Stream Load
This section uses curl to explain how to run a Stream Load job in your local terminal to load CSV or JSON data.
The basic syntax is as follows:
curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
# The parameter warehouse is used only for data loading into an elastic cluster.
-H "warehouse:<warehouse_name>" \
# The parameter column_separator is used only for CSV data loading.
-H "column_separator:<column_separator>" \
# The parameter jsonpaths is used only for JSON data loading.
-H "jsonpaths: [ \"<json_path1>\"[, \"<json_path2>\", ...] ]" \
-H "columns:<column1_name>[, <column2_name>, ... ]" \
-H "format: CSV | JSON" \
-T <file_path> -XPUT \
https://<fe_host>/api/<database_name>/<table_name>/_stream_load
The load command mainly includes the following parts:
-
HTTPS request header
Expect: Specify its value as100-continue, as in"Expect:100-continue". -
<username>:<password>: Specify the username and password of the account that you use to connect to your CelerData cluster. -
warehouse: Specify the destination warehouse. This parameter is required only for data loading into an elastic cluster. If you do not specify this parameter, the default warehouse nameddefault_warehouseis used for the data loading. Make sure the destination warehouse is running. If the destination warehouse is not running, the data loading will fail. -
column_separator: Specify the characters that are used in the CSV data file to separate fields. The default value is\t, which indicates tab. If the CSV data file uses tabs to separate the fields in it, you do not need to specify this parameter. -
jsonpaths: Specify the names of the keys that you want to load from the JSON data file. You need to specify this parameter only when you load JSON data by using the matched mode. The value of this parameter is in JSON format. See Configure column mapping for JSON data loading. -
columns: Specify the column mapping between the data file and the destination table. -
format: Specify the format of the data file. -
file_path: Specify the save path of the data file. You can optionally include the extension of the file name, and then you do not need to specify theformatparameter. -
HTTPS line: This includes the method, which is
-XPUT, and the URL that contains the path to the destination table within your CelerData cluster.
URL Syntax:
https://<fe_host>/api/<database_name>/<table_name>/_stream_load
The following table describes the parameters in the URL.
| Parameter | Required | Description |
|---|---|---|
| fe_host | Yes | The public or private endpoint of the cluster. You can open the Overview page of the cluster in the CelerData Cloud BYOC console and navigate to the Connection section to find and copy the endpoint. |
| database_name | Yes | The name of the database to which the destination table belongs. |
| table_name | Yes | The name of the destination table. |
For detailed syntax and parameter descriptions, see STREAM LOAD.
Load CSV data
To load the data of the CSV data file example1.csv into table1 within the default_warehouse of the elastic cluster you selected in Connect to CelerData, run the following command:
curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
-H "warehouse:default_warehouse" \
-H "column_separator:," \
-H "columns: id, name, score" \
-T example1.csv -XPUT \
https://<fe_host>/api/mydatabase/table1/_stream_load
example1.csv consists of three columns, which are separated by commas (,) and can be mapped in sequence onto the id, name, and score columns of table1. Therefore, you need to use the column_separator parameter to specify the comma (,) as the column separator. You also need to use the columns parameter to temporarily name the three columns of example1.csv as id, name, and score, which are mapped in sequence onto the three columns of table1.
For more information about column mapping, see Configure column mapping for CSV data loading.
Load JSON data
To load the data of the JSON data file example2.json into table2 within the default_warehouse of the elastic cluster you selected in Connect to CelerData, run the following command:
curl -v --location-trusted -u <username>:<password> \
-H "strict_mode: true" \
-H "Expect:100-continue" \
-H "warehouse:default_warehouse" \
-H "format: json" \
-H "jsonpaths: [\"$.name\", \"$.code\"]" \
-H "columns: city,tmp_id, id = tmp_id * 100" \
-T example2.json -XPUT \
https://<fe_host>/api/mydatabase/table2/_stream_load
example2.json consists of two keys, name and code, which are mapped onto the id and city columns of table2, as shown in the following figure.
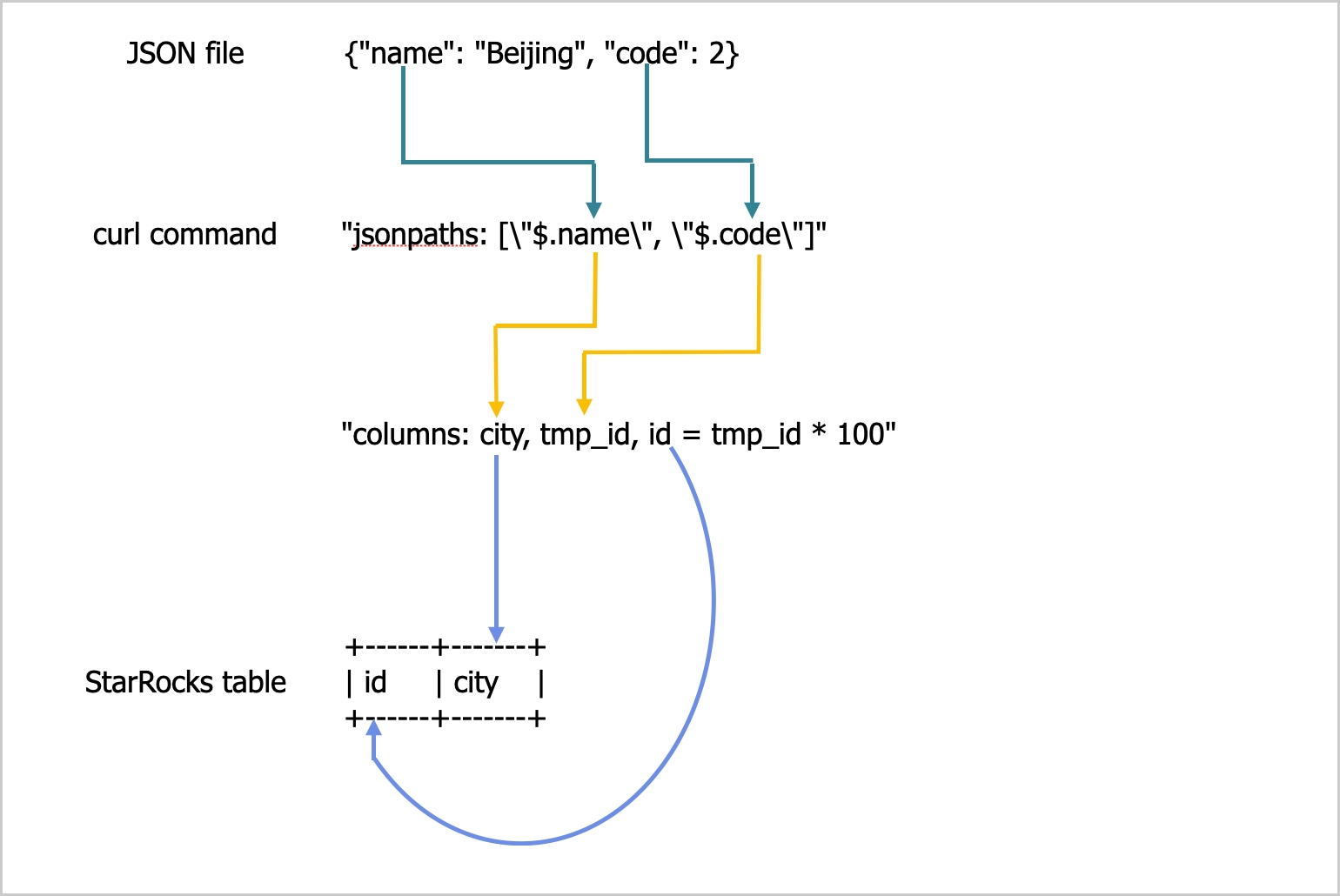
The mappings shown in the preceding figure are described as follows:
- CelerData extracts the
nameandcodekeys ofexample2.jsonand maps them onto thenameandcodefields declared in thejsonpathsparameter. - CelerData extracts the
nameandcodefields declared in thejsonpathsparameter and maps them in sequence onto thecityandtmp_idfields declared in thecolumnsparameter. - CelerData extracts the
cityandtmp_idfields declared in thecolumnsparameter and maps them by name onto thecityandidcolumns oftable2.
NOTE
In the preceding example, the value of
codeinexample2.jsonis multiplied by 100 before it is loaded into theidcolumn oftable2.
For more information about column mapping, see Configure column mapping for JSON data loading.
Check Stream Load progress
After a Stream Load job is complete, CelerData returns the result of the job in JSON format. For more information, see the "Return value" section in STREAM LOAD.
Stream Load does not allow you to query the result of a load job by using the SHOW LOAD statement.
Cancel a Stream Load job
Stream Load does not allow you to cancel a load job. If a load job times out or encounters errors, CelerData automatically cancels the job.