Manage and use warehouses
Concept
A warehouse in an elastic CelerData cluster is a physical group of multiple compute nodes that provide you with the required compute resources, such as CPU, memory, and temporary storage, to perform query, ingestion, and data processing tasks on data stored in remote storage. You can resize a warehouse based on your workloads, and use different warehouses to isolate your workloads from different data analysis scenarios.
Access control
Users with the cluster_admin role can create new warehouses and delete, suspend, or resume existing warehouses through the GUI, and can use all warehouses available within the cluster.
By default, users without the cluster_admin role can only use the built-in warehouse default_warehouse provided and have no access to other warehouses. If they want to use any other warehouse, they must be granted the USAGE privilege on that warehouse through the following SQL command:
GRANT USAGE ON WAREHOUSE <WAREHOUSE_NAME to <USER_NAME>;
Only users with the user_admin role can grant or revoke privileges in the cluster. See Manage privileges.
Manage warehouses
Create a warehouse
Each new elastic cluster has a built-in warehouse named default_warehouse which is created along with the cluster. For more information about the default warehouse, see Overview of warehouses - Usage notes.
To create a new warehouse in your elastic cluster, follow these steps:
-
Sign in to the CelerData Cloud BYOC console.
-
On the Clusters page, click the elastic cluster for which you want to create a warehouse.
-
On the cluster detail page, click Manage and choose Add warehouse.
NOTE
You can also navigate to the Warehouses tab of the cluster detail page and click Create warehouse to create a warehouse.
-
In the dialog box that appears, configure the following parameters and click Create:
- Warehouse name: Enter a name for the warehouse. Each warehouse name must be unique within your elastic cluster.
- Description: Optionally enter a description for the warehouse. The description helps you manage multiple warehouses easily.
- Compute node size: Select an instance type for the compute nodes of the warehouse. The instance type determines the number of vCPU cores and the memory capacity per compute node.
- Compute node count: Select the number of compute nodes you want to deploy for the warehouse.
- Compute storage size: (Available for EBS-backed instance types only) Specify the storage size for the compute nodes of the warehouse. You can also customize the number of volumes by ticking the box next to this field.
- Node distribution policy: Select a Compute Node distribution policy for the warehouse. This field is available only when Multi-AZ deployment is enabled. For more information about the node distribution policies of Multi-AZ Deployment, see Multi-AZ Deployments.
- Resume this warehouse along when cluster is resumed: Tick this option if you want to resume the warehouse automatically when the cluster is resumed.
- Add tag: Optionally add one or more tags to the warehouse. Note that duplicate tags between the cluster and the warehouse are not allowed.
note- Multi AZ Policy is a Private Preview feature and is available when the database kernel version is v4.0 or later.
- Crossing AZ Policy is available when the database kernel version is earlier than v4.0. From v4.0 onwards, you cannot create new clusters with Crossing AZ Policy.
Creating a warehouse takes approximately 2 minutes.
After a warehouse is successfully created, CelerData will start to charge you for the runtime of this warehouse.
Resize a warehouse
If the size of a warehouse causes a performance bottleneck for your workloads, you can scale out the warehouse as needed.
For information about how to scale the warehouse in your cluster, see Scale an elastic cluster.
You can also enable autoscaling for each warehouse to allow the system to automatically scale the number of Compute Nodes or Compute Node Groups based on the CPU utilization or query queue length of the warehouse. For more information, see Warehouse Autoscaling.
Suspend and resume a warehouse
Because the continuous runtime of a warehouse will bring you continuous costs. Therefore, if you only run your workloads in a specific warehouse occasionally, you can suspend the warehouse to save unnecessary costs and resume it manually on demand.
NOTE
The default warehouse cannot be suspended separately from the cluster. It will be suspended only when the cluster is suspended.
After you suspend a warehouse, CelerData stops charging you for this warehouse until this warehouse is resumed again.
To suspend or resume a warehouse, follow these steps:
-
Sign in to the CelerData Cloud BYOC console.
-
On the Clusters page, click the elastic cluster for which you want to suspend or resume a warehouse.
-
On the Warehouses tab of the cluster detail page, move the cursor to the lower-right corner of the card for the warehouse to display the View more details button, and then click the button.
-
On the warehouse detail page, click Suspend or Resume.
-
In the message that appears, click Suspend or Start resume.
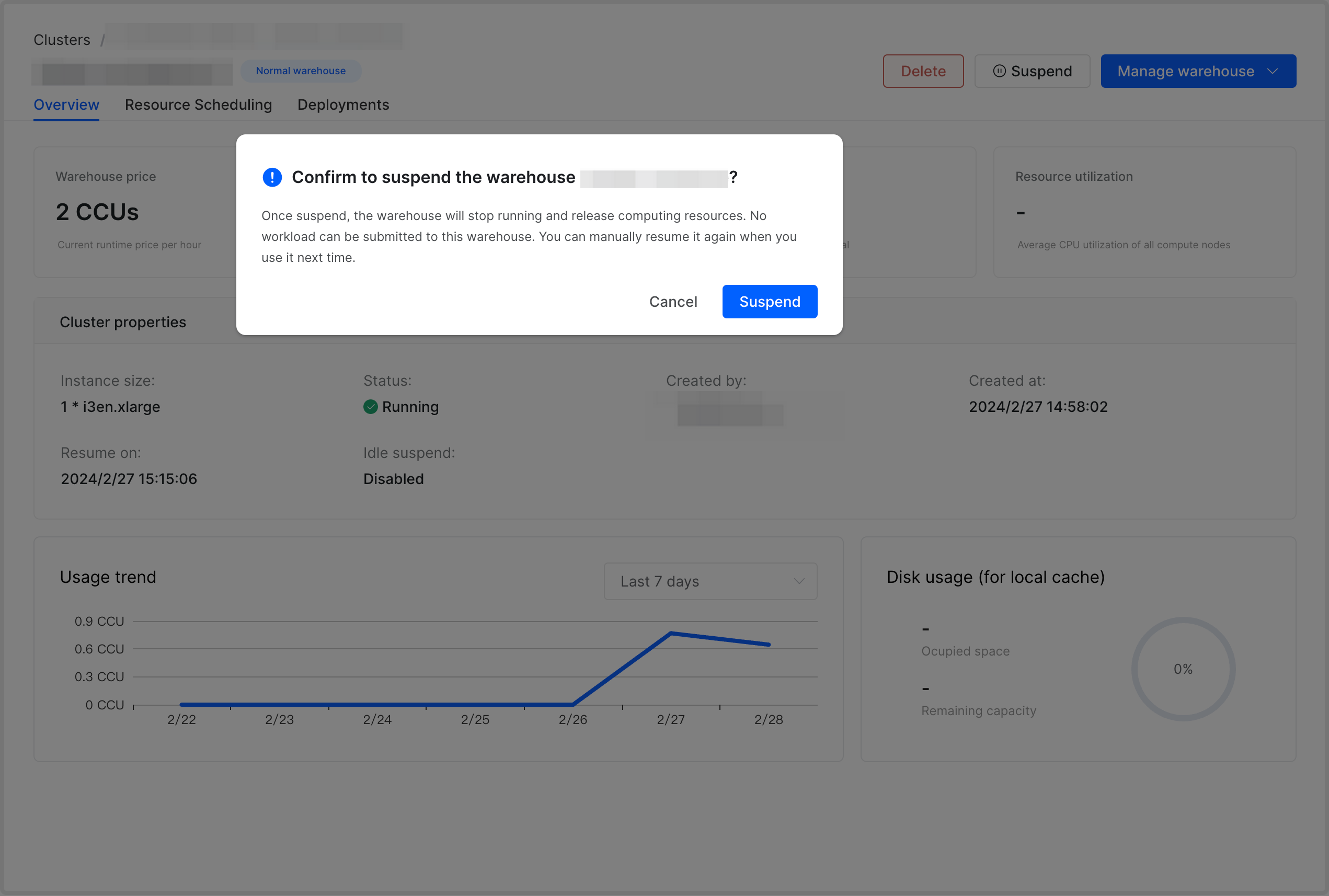
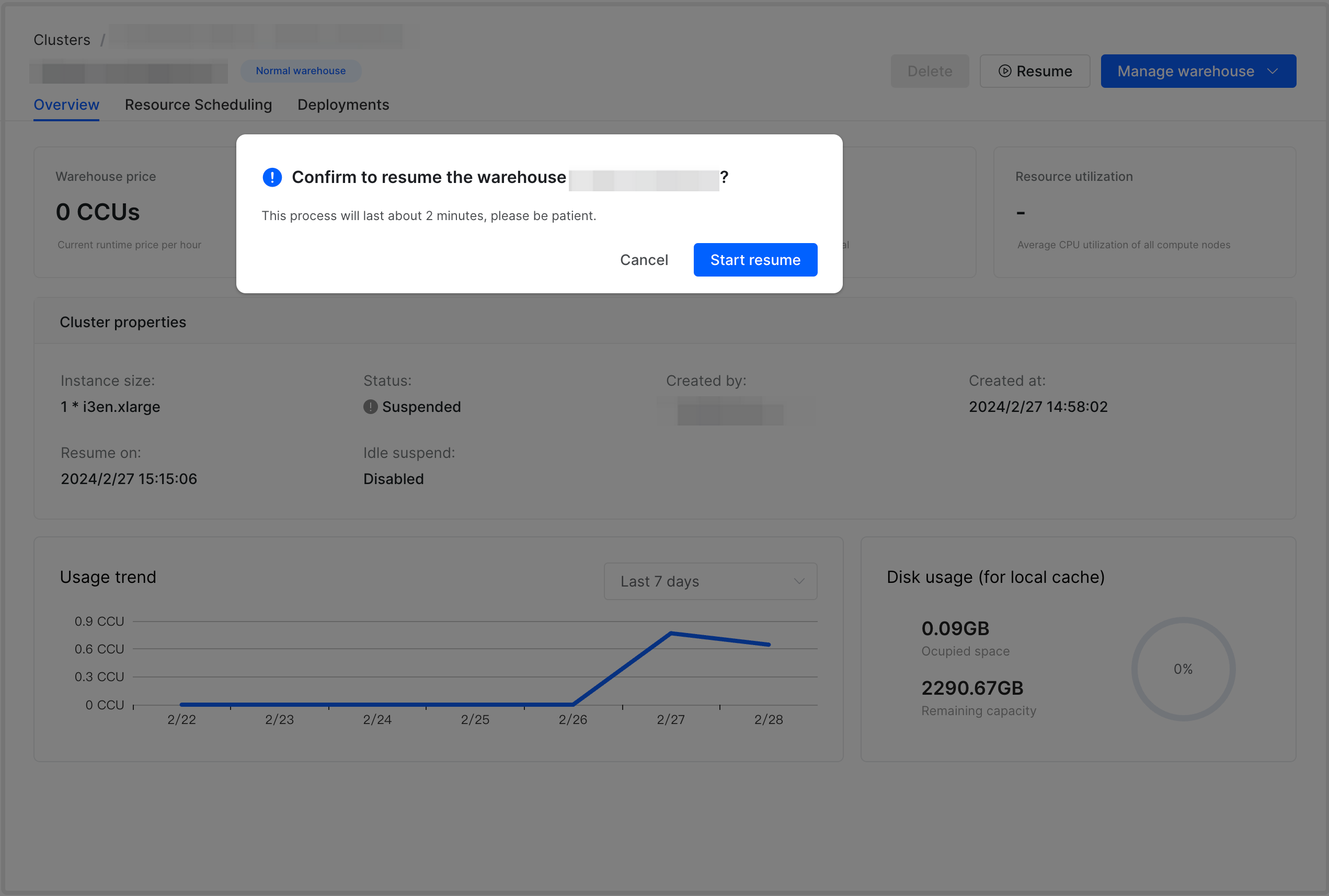
NOTE
You can suspend or resume a warehouse immediately by clicking the Quick suspend or Quick resume button on the card of the warehouse.
Enable Auto Suspend for a warehouse
When the Auto Suspend feature is enabled for a warehouse, CelerData monitors the activity levels of the compute nodes in the warehouse. If the nodes stay idle for a specified amount of time, CelerData automatically suspends the warehouse.
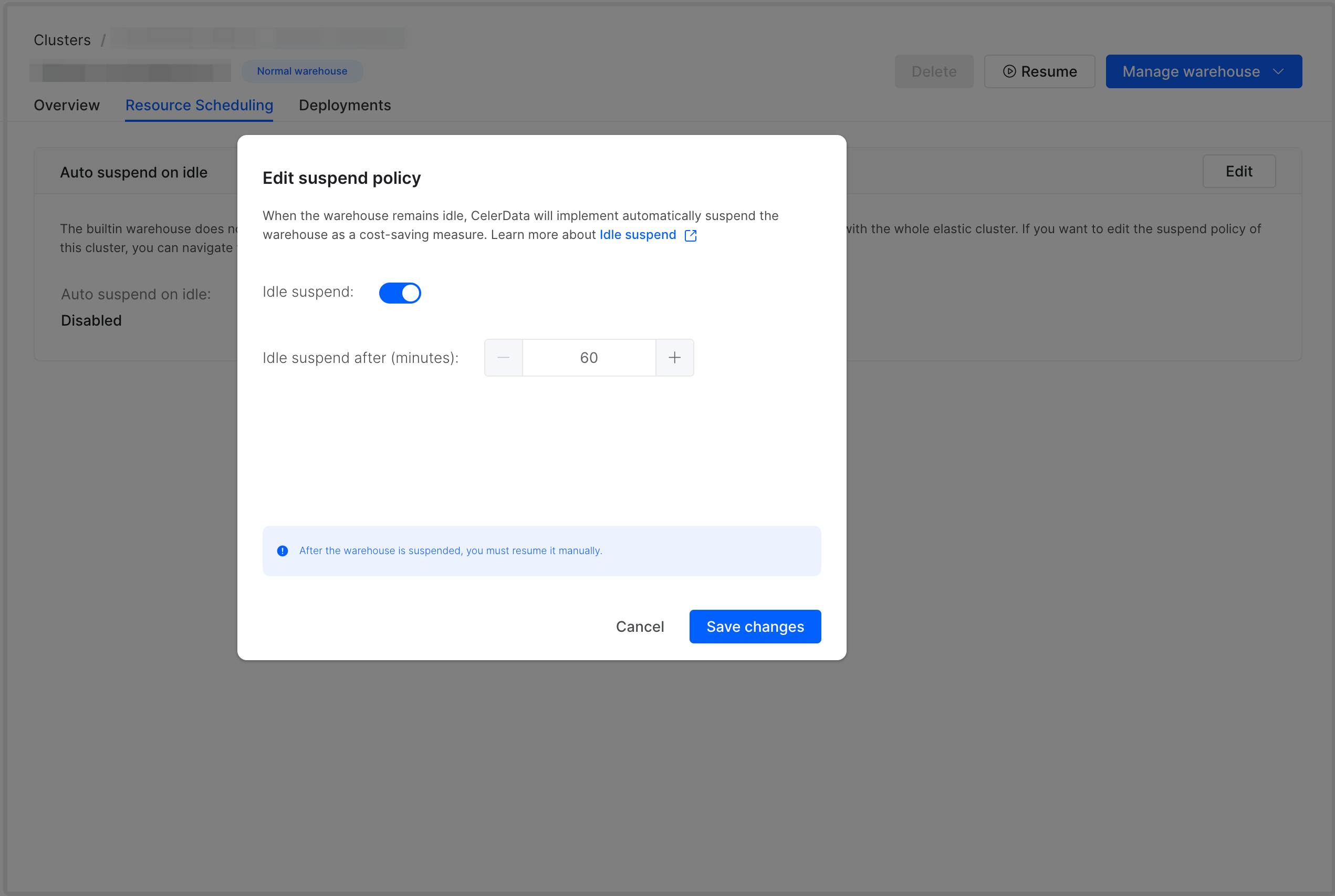
To enable the Auto Suspend feature for a warehouse, follow these steps:
-
Sign in to the CelerData Cloud BYOC console.
-
On the Clusters page, click the elastic cluster where the warehouse that you want to enable Auto Suspend resides.
-
On the Warehouses tab of the cluster detail page, move the cursor to the lower-right corner of the card for the warehouse to display the View more details button, and then click the button.
-
Click the Resource Scheduling tab. Then, click Edit in the Auto suspend on idle section.
-
In the Edit suspend policy dialog box, turn on the switch next to Idle suspend, select the maximum amount of time during which the warehouse can stay idle, and then click Save changes.
Delete a warehouse
If you no longer need a warehouse, you can delete it. This will release all compute resources provisioned to the warehouse, stop billing, and forcibly terminate any SQL queries running on the warehouse.
NOTE
- You can only delete a warehouse while it is in the running state.
- The default warehouse cannot be deleted.
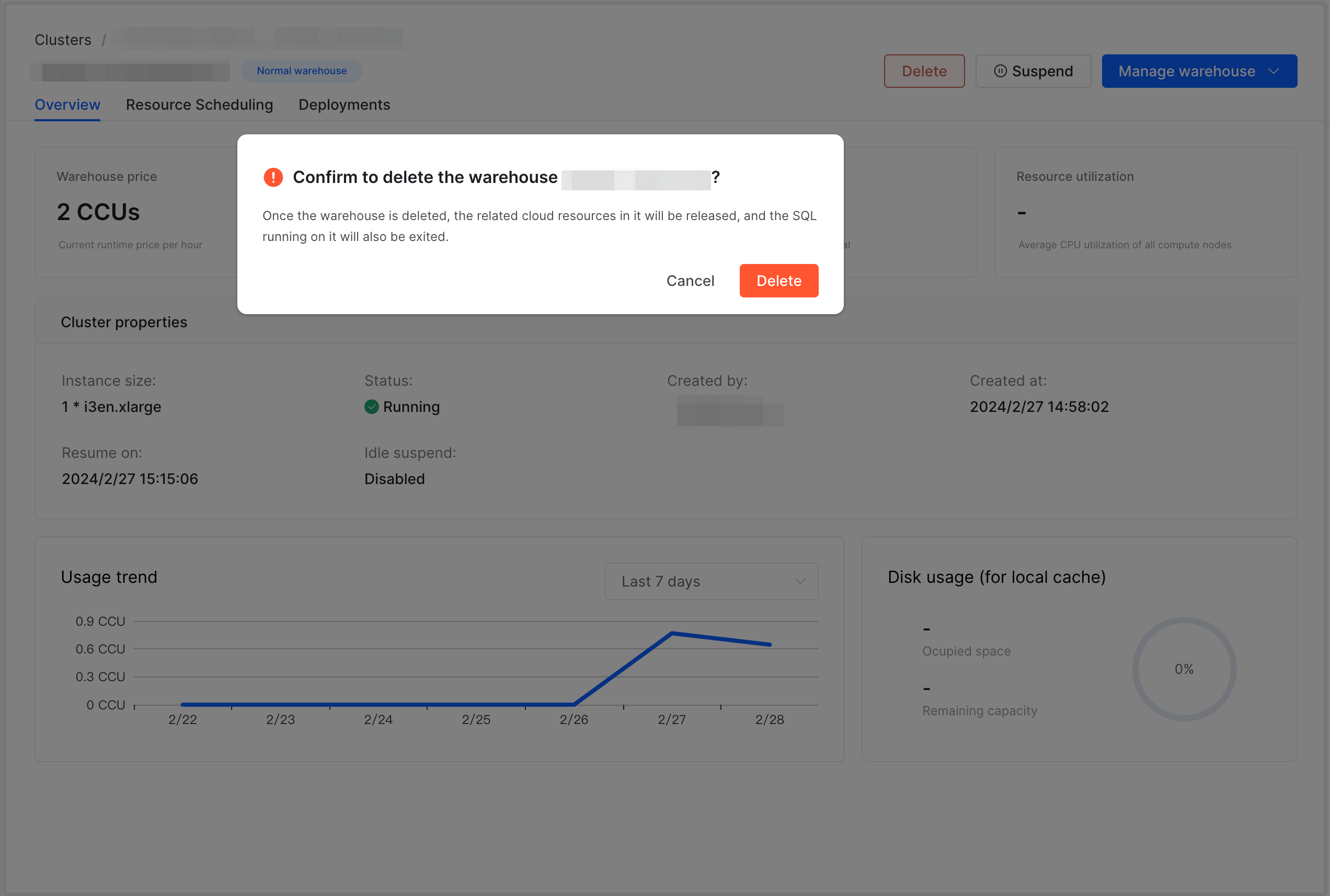
To delete a warehouse, follow these steps:
-
Sign in to the CelerData Cloud BYOC console.
-
On the Clusters page, click the elastic cluster for which you want to delete a warehouse.
-
On the Warehouses tab of the cluster detail page, move the cursor to the lower-right corner of the card for the warehouse to display the View more details button, and then click the button.
-
On the warehouse detail page, click Delete.
-
In the message that appears, click Delete.
View a warehouse
To view the details of a warehouse, follow these steps:
-
Sign in to the CelerData Cloud BYOC console.
-
On the Clusters page, click the elastic cluster you want to view.
-
On the cluster detail page, click the Warehouses tab. The Warehouses tab provides an overview of all of the warehouses created within your elastic cluster. The overview includes the status, size, disk usage, and CCU usage histogram of each warehouse.
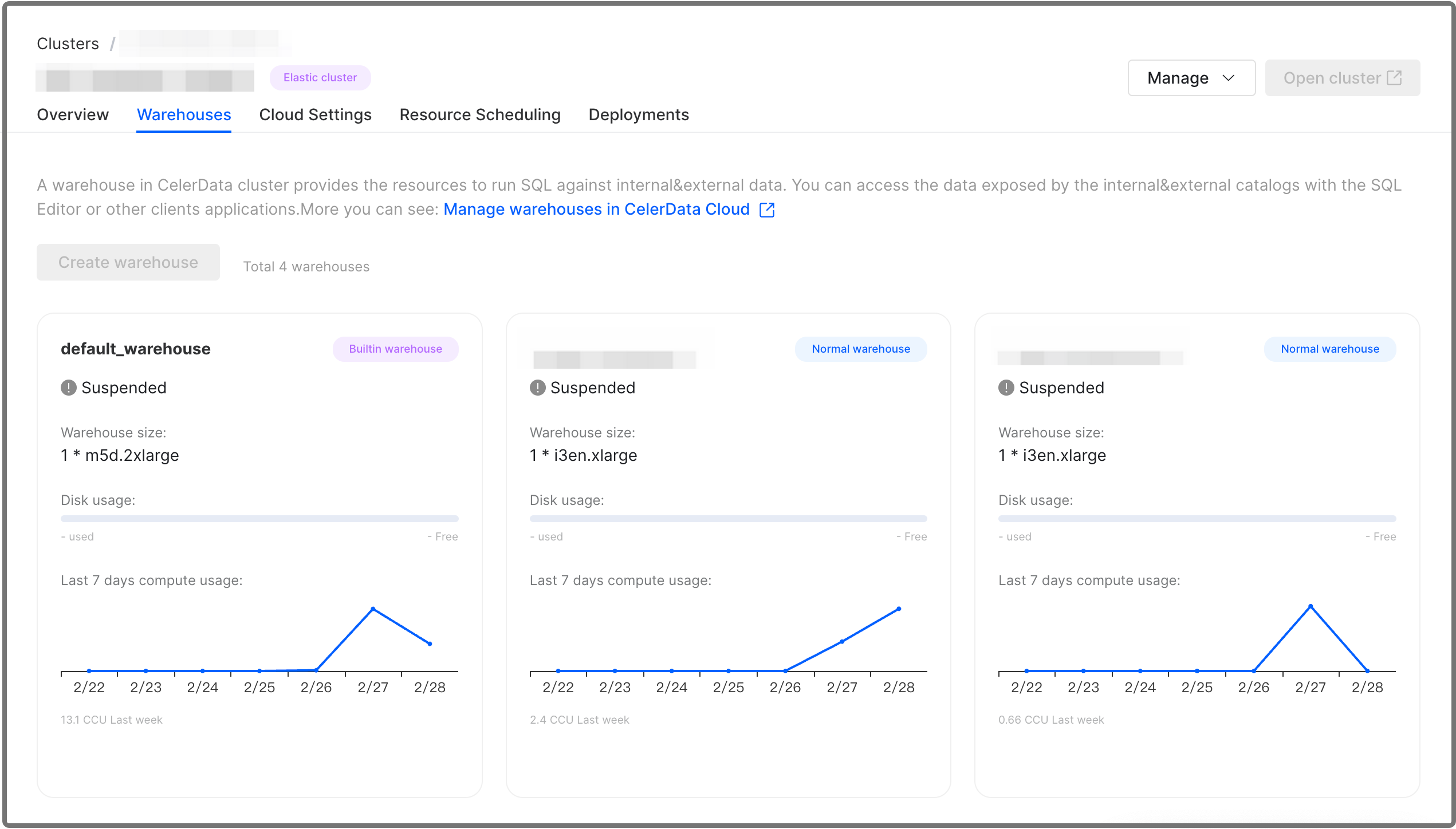
Move the cursor to the lower-right corner of the card for the warehouse to display the View more details button, and then click the button. The warehouse detail page displays three categories of information on three distinct tabs: Overview, Resource Scheduling, and Deployments.
Overview
The Overview tab consists of the following sections:
- Warehouse price: the current runtime CCU price per hour of the warehouse.
- Monthly warehouse usage: the month-to-date CCU usage of the warehouse.
- Warehouse nodes: the compute node count within the warehouse (running nodes/all nodes).
- Resource utilization: the average CPU utilization of all compute nodes.
- Cluster properties
- Instance size: the instance type of the compute nodes in the warehouse.
- Status: the status of the warehouse.
- Created by: the user who created the warehouse.
- Created at: the time when the warehouse was created.
- Resume on: the time when the warehouse was last resumed.
- Idle suspend: whether the Auto Suspend feature is enabled for the warehouse.
- Usage trend: the CCU histogram of the warehouse.
- Disk usage (for local cache): the disk usage of the warehouse.
Resource Scheduling
On the Resource Scheduling tab, you can view the setting of the Auto Suspend feature for the warehouse.
Deployments
The Deployments tab displays the following information of each compute node in the warehouse:
- Node host: the IP address of the node.
- Node size: the instance type of the node.
- Status: the status of the node.
- vCPU (core): the vCPU core count of the node.
- Memory (GB): the memory size of the node.
- Volume size (GB): the disk volume size of the node.
Set warehouse
After creating a new warehouse, you can enable it whenever needed by setting the warehouse for the current session, specified users, or specific operations. Thus, each request can only use the compute resources of the specified warehouse.
The way you specify a warehouse varies depending on the method you use to interact with your elastic cluster.
Set warehouse in SQL Editor
In SQL Editor, select a warehouse that is in the running state as shown below:
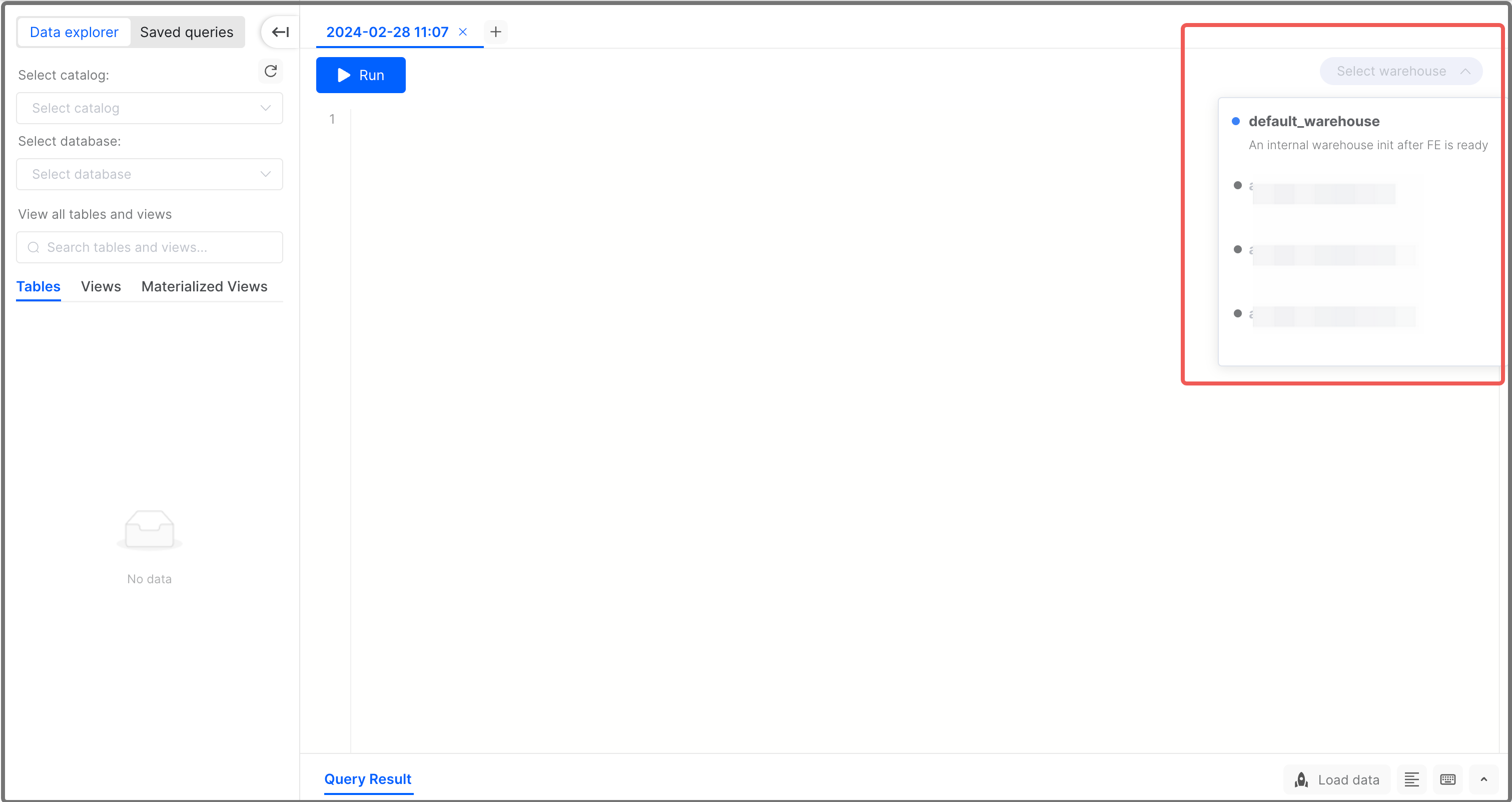
Set warehouse for current session
Use the following syntax to set a warehouse for the current session:
SET WAREHOUSE = <warehouse_name>
Parameter:
warehouse_name (Required): The name of the warehouse you want to use in the current session.
NOTE
If you do not set the warehouse for the current session,
default_warehouseis used.
Example:
Set wh1 for the current session.
SET WAREHOUSE = wh1;
You can view the warehouse that is in use in the current session:
SHOW VARIABLES LIKE "%warehouse%";
Set warehouse for specific user
You can set a warehouse for a user as their default warehouse.
ALTER USER '<username>' SET PROPERTIES ("session.warehouse" = "<warehouse_name>")
Parameter:
username(Required): The username of the user for whom you want to set the default warehouse.warehouse_name(Required): The name of the warehouse you want to set as the default warehouse for the specified user.
Example:
Set wh1 as the default warehouse of the user jack.
ALTER USER 'jack' SET PROPERTIES ("session.warehouse" = "wh1");
Set warehouse for specific SQL
You can use hints to set the warehouse for specific SQL statements.
Example:
SELECT /*+ SET_VAR(warehouse="wh1") */ * FROM my_db.my_table;
UPDATE /*+ SET_VAR(warehouse="wh1") */ my_db.my_table SET c1 = 2 WHERE c1 = 1;
DELETE /*+ SET_VAR(warehouse="wh1") */ FROM my_db.my_table PARTITION p1 WHERE k1 = 3;
INSERT /*+ SET_VAR(warehouse="wh1") */ INTO my_db.my_table SELECT * FROM my_db.my_table2;
Set warehouse for loading tasks
For Broker Load
You can set the warehouse for a specific Broker Load task by declaring it in the property warehouse.
Example:
LOAD LABEL user_behavior
(
DATA INFILE("s3://starrocks-examples/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"aws.s3.enable_ssl" = "true",
"aws.s3.use_instance_profile" = "false",
"aws.s3.region" = "us-east-1",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
)
PROPERTIES
(
"warehouse"="wh1"
);
For Routine Load
You can set the warehouse for a specific Routine Load task by declaring it in the job property warehouse.
Example:
CREATE ROUTINE LOAD example_db.example_tbl1_ordertest1 ON example_tbl1
COLUMNS TERMINATED BY ",",
COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price)
PROPERTIES
(
"desired_concurrent_number" = "5",
"warehouse"="wh1"
)
FROM KAFKA
(
"kafka_broker_list" ="<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>",
"kafka_topic" = "ordertest1",
"kafka_partitions" ="0,1,2,3,4",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.security.protocol"="SASL_SSL",
"property.sasl.mechanism"="PLAIN",
"property.sasl.username"="***",
"property.sasl.password"="***"
);
For Stream Load
You can set the warehouse for a specific Stream Load task by declaring it in the header parameter.
Example:
curl --location-trusted -u <username>:<password> \
-H "Expect:100-continue" \
-H "warehouse:wh1" \
-H "column_separator:," \
-H "columns: id, name, score" \
-T example1.csv -XPUT \
https://<fe_host>/api/mydatabase/table1/_stream_load
Set warehouse for materialized view refresh
You can set the warehouse for the refresh task of materialized views by declaring it in the property warehouse.
NOTE
If
warehouseis not specified, the warehouse of the current session will be used.
Example:
CREATE MATERIALIZED VIEW order_mv
DISTRIBUTED BY HASH(`order_id`)
REFRESH ASYNC EVERY (interval 1 MINUTE)
PROPERTIES ("warehouse" = "wh1")
AS SELECT
order_list.order_id,
sum(goods.price) as total
FROM order_list INNER JOIN goods ON goods.item_id1 = order_list.item_id2
GROUP BY order_id;
After the materialized view is created, you can view the property warehouse by executing SHOW MATERIALIZED VIEWS or SHOW CREATE MATERIALIZED VIEW. It will also be recorded in fe.audit.log.
Set warehouse for Compaction
By default, Compaction tasks are running on default_warehouse. You can change it by setting the FE configuration item lake_compaction_warehouse.
-
Execute the following statement to dynamically change the default Compaction warehouse:
ADMIN SET FRONTEND CONFIG ("lake_compaction_warehouse" = "<warehouse_name>"); -
You can set this parameter permanently by setting it as a static parameter:
lake_compaction_warehouse = <warehouse_name>
After changing the configuration, you can view the warehouse information of compaction tasks by executing SHOW PROC '/compactions'.
Set warehouse in JDBC URL
jdbc.url=jdbc:mysql://<host>/<db_name>?sessionVariables=warehouse=<warehouse_name>
Show warehouse
Show all warehouses
Use the following syntax to show all warehouses in a cluster:
SHOW WAREHOUSES [ LIKE '<pattern>' ]
Example:
Show all warehouses in the current cluster.
SHOW WAREHOUSES;
The returned information is as follows:
+-------+-------------------+-----------+-----------+---------------------+-----------------+-----------------+------------+-----------+---------------------+-----------+---------------------+----------------------------------------------+
| Id | Name | State | NodeCount | CurrentClusterCount | MaxClusterCount | StartedClusters | RunningSql | QueuedSql | CreatedOn | ResumedOn | UpdatedOn | Comment |
+-------+-------------------+-----------+-----------+---------------------+-----------------+-----------------+------------+-----------+---------------------+-----------+---------------------+----------------------------------------------+
| 0 | default_warehouse | AVAILABLE | 2 | 1 | 1 | 1 | 0 | 0 | 2023-10-11 15:28:46 | NULL | 2023-10-11 15:28:46 | An internal warehouse init after FE is ready |
| 11078 | wh1 | AVAILABLE | 1 | 1 | 1 | 1 | 0 | 0 | 2023-10-11 16:31:20 | NULL | 2023-10-11 16:31:20 | NULL |
+-------+-------------------+-----------+-----------+---------------------+-----------------+-----------------+------------+-----------+---------------------+-----------+---------------------+----------------------------------------------+
Return:
Id: The ID of the warehouse.Name: The name of the warehouse.State: The state of the warehouse. Valid values:AVAILABLE: The warehouse is running.SUSPENDED: The warehouse is suspended.
NodeCount: The number of Compute Nodes in the warehouse.CurrentClusterCount:MaxClusterCount:StartedClusters:RunningSql: The number of queries that are currently running in the warehouse.QueuedSql: The number of queries that are waiting for execution.CreatedOn: The time when the warehouse is created.ResumedOn: The time when the warehouse is resumed.UpdatedOn: The time when the warehouse is updated.Comment: The comment of the warehouse.
Show all Compute Nodes in a cluster
Use the following syntax to show all Compute Nodes in the current cluster:
SHOW COMPUTE NODES
Example:
Show all Compute Nodes in the current cluster.
SHOW COMPUTE NODES;
Show Compute Nodes in specified warehouse(s)
Use the following syntax to show Compute Nodes in the specified warehouse(s):
SHOW NODES FROM
{ WAREHOUSE <warehouse_name>
| WAREHOUSES [ LIKE '<pattern>' ] }
Parameter:
warehouse_name(Required): The name of the warehouse in which you want to view the Compute Nodes.WAREHOUSES: Shows the Compute Nodes in all warehouses or a group of warehouses with the specified pattern.
Example:
Show all Compute Nodes in all warehouses in the cluster.
SHOW NODES FROM WAREHOUSES;